快排 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public static void quickSort (int [] arr,int low,int high) int i,j,temp,t; if (low>high){ return ; } i=low; j=high; temp = arr[low]; while (i<j) { while (temp<=arr[j]&&i<j) { j--; } while (temp>=arr[i]&&i<j) { i++; } if (i<j) { t = arr[j]; arr[j] = arr[i]; arr[i] = t; } } arr[low] = arr[i]; arr[i] = temp; quickSort(arr, low, j-1 ); quickSort(arr, j+1 , high); }
有向无环图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public static List<Startup<?>> sort(List<? extends Startup<?>> startupList) { Map<Class<? extends Startup>, Integer> inDegreeMap = new HashMap<>(); Deque<Class<? extends Startup>> zeroDeque = new ArrayDeque<>(); Map<Class<? extends Startup>, Startup<?>> startupMap = new HashMap<>(); Map<Class<? extends Startup>, List<Class<? extends Startup>>> startupChildrenMap = new HashMap<>(); for (Startup<?> startup : startupList) { startupMap.put(startup.getClass(), startup); int dependenciesCount = startup.getDependenciesCount(); inDegreeMap.put(startup.getClass(), dependenciesCount); if (dependenciesCount == 0 ) { zeroDeque.offer(startup.getClass()); } else { for (Class<? extends Startup<?>> parent : startup.dependencies()) { List<Class<? extends Startup>> children = startupChildrenMap.get(parent); if (children == null ) { children = new ArrayList<>(); startupChildrenMap.put(parent, children); } children.add(startup.getClass()); } } } List<Startup<?>> result = new ArrayList<>(); while (!zeroDeque.isEmpty()) { Class<? extends Startup> cls = zeroDeque.poll(); Startup<?> startup = startupMap.get(cls); result.add(startup); if (startupChildrenMap.containsKey(cls)){ List<Class<? extends Startup>> childStartup = startupChildrenMap.get(cls); for (Class<? extends Startup> childCls : childStartup) { Integer num = inDegreeMap.get(childCls); inDegreeMap.put(childCls,num-1 ); if (num - 1 == 0 ){ zeroDeque.offer(childCls); } } } } return result; }
Android开发艺术探索 RemoteViews 应用场景主要2个:Notification 和桌面小部件。它是在运行在其他进程(SystemServer 进程),所以更新UI需要跨进程。
Activity A 启动 B 的时候,在 onPause 里面不要做耗时操作,因为A onPause 执行完成后 B 的 onResume 才会执行。调用 onPause 的时候,如果快速又返回到当前 Activity,则onResume 就会调用 ,onResume 的时候,意味着在 Activity 在前台了(�用户的输入交给它响应)。
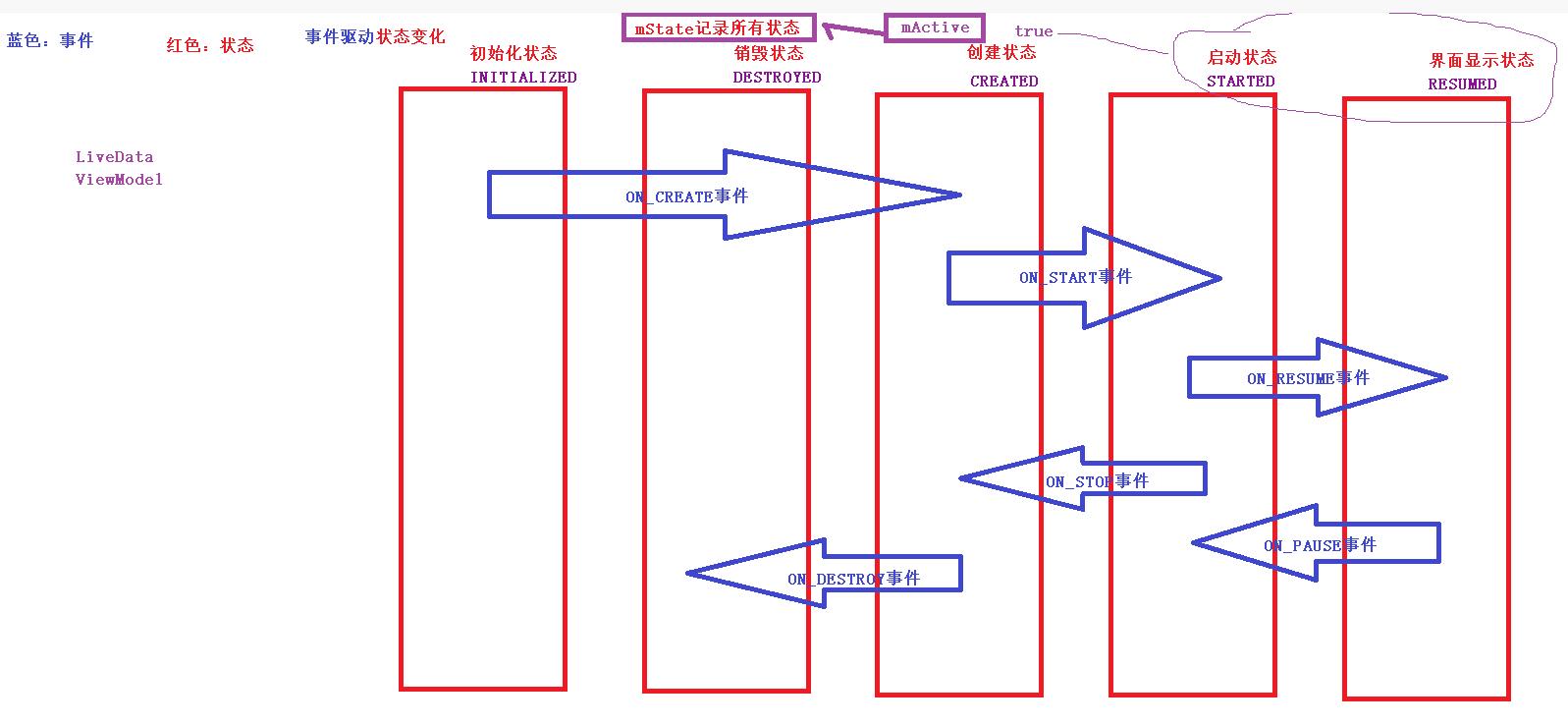
异常销毁Activity 会在 onStop 之前调用 onSaveInstanceState 保存数据,恢复的时候可以在onCreate 中和 onRestoreInstanceState 中,不过系统建议在 onRestoreInstanceState 中,因为只要这个回调又,就一定能保证有数据。
在 5.0 源码中,在 ActivityStackSupervisor 类的startActivityUncheckedLocked 里面判断launchmode。
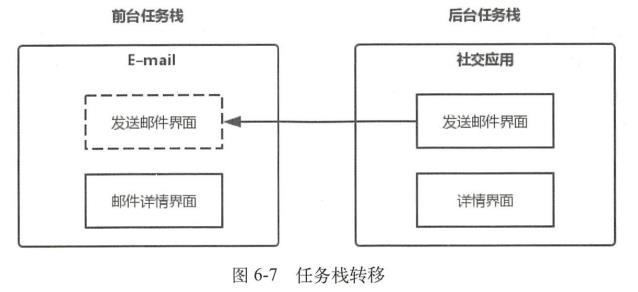
不希望用户通过历史列表回到我们的Activity的时候使用 Activity 的属性 android:excludeFromRecents = “true”
开启多进程:xml 中 process 顺属性 或者 在native 中 fork操作
多进程导致静态和单例失效、线程同步失效、sp失效、Application 多次创建
Serializable 没有显式 声明serialVersionUID,则序列化运行时将根据类的各个方面计算该类的默认serialVersionUID值。但是,强烈建议 所有可序列化类显式声明serialVersionUID值,因为默认的 serialVersionUID 计算对类详细信息高度敏感,这些详细信息可能因编译器实现而异,因此在反序列化过程中可能会导致意外的InvalidClassExceptions。同步回博客,开发艺术探索第二章
serialVersionUID 是干什么的? - 知乎 (zhihu.com)
组件化 组件化好处:解耦、自由组合、重复利用、不相互依赖
我们使用 gradle 编译项目的时候,执行顺序是根据范围从大到小的,依次是: settings.gradle -> project的build ->app的build -> library 的 build
组件化侧重功能重用,比如相册组件之类的;而模块化侧重的是业务层面的拆分,比如收银台模块。
google 表态说 Framework 层还会是 Java ,不会上 Kotlin ,所以这块的源码不会怎么变动
JavaPoet 这个工具在构建的时候是反着来的,首先 build 出来一个方法,然后作为 build 的一个参数 build 出来一个 类,再将类作为参数 build 出来一个 包。
ARouter 中自动生成代码很重要的一个精髓是 2 个接口: ARouterGroup 和 ARouterPath ,里面分别有 getGroupMap() 和 getPathMap() 方法
插件化选择开源框架的时候,如果非常独立不要和宿主通信,就可以使用 RePlugin,其他情况推荐 VirtualApk
为什么反射耗时?临时对象,容易 GC ;参数为可变长的,会有拆装箱
使用反射的时候,Class.forName 和 Class.loadClass 的区别是啥?loadClass 只是做类加载;forName 会做加载、验证准备、解析、初始化。
Robust 是通过在每个方法里面都插入一个拦截来实现的,其中每个类中会有一个 changeQuickRedirect ,当这个类没有bug 时, changeQuickRedirect 是空的;如果有bug ,那就会被反射给这个类对象的 changeQuickRedirect 赋值,然后方法就会被导到修复的方法中去。
Binder 是一个虚拟机的物理设备,在 dev/Binder 上
IPC方式:AIDL、Bundle、文件共享、Messager、ContentProvider、Socket、广播
使用 AIDL 在Stub的 asInterface 方法中会根据 IBinder 类型的obj 对象来判断是不是有跨进程,不跨进程就强转;否则创建 Proxy 对象返回
因为 Stub 是客户端,的 onTransact 指的是接收Server 返回的数据,每个操作都有唯一 code 对应,这样就无需传方法名之类的,节省空间。数据都是挨个排放的,不是key-value 的形式,所以读取也要按照存入顺序读取。
Launcher 启动斗鱼App,向 AMS 申请启动斗鱼时会将自己的 ApplicationThread 和 Launcher 当前的 Activity (mToken )传过去,AMS 收到请求后,会根据上述的信息跨进程通知 Launcher 让其 pause 。
Pause 的原理:在ActivityThread 中有一个 mActivities 集合,保存当前App(目前是Launcher)中所有的Activity,找出来让其休眠
AMS创建新进程后,马上创建 ActivityThread 对象,并且在其中创建主线程Looper、创建Application
Activity 和 context 的 startActivity 最终都走到 Instrumentation 中的 execStartActivity。(context的startActivity 也是通过 mMainThread 获取 instrumentation 对象,然后调用其 execStartActivity)
service 有2套流程,一套是启动流程,一套是绑定流程。区别在于:startService 以及对应的 stopService ,就是简单地启动和停止 Service ;bindService 执行时会传递一个 ServiceConnection 对象给 AMS ,接下来 Service 在执行 onBind 时,可以把生成的 binder 对象返回给 App 调用端,这个值存于 ServiceConnection 对象的 onServiceConnected 回调函数的第二个参数中。
四大组件创建对象时,都是通过LoadedApk对象获取 ClassLoader,之后再通过反射创建出来 Activity 或者 Service 等。
静态广播,在App安装的时候注册;动态广播注册的时候发给AMS ,当然还包括当前进程自身对象,以便产生广播的时候知道发到哪里。动态Receiver 与静态Receiver 分别存在AMS中不同的变量中,在发送广播时,会合并,并且动态的排在静态的前面,因此动态Receiver 永远先于静态Receiver收到消息。
粘性广播,如电量低于20%了会有广播,但是后续来的注册,也能马上收到这个广播。
ContentProvider 本质就是对 SQLite 的封装
ContentProvider 的 onCreate 会在 Application 的 onCreate 之前执行,LeakCanary 就是利用这个机制免代码注册。
ContentProvider 通过匿名共享内存的方式传递数据,主要过程是:
client端向server端请求ContentProvider 数据得到一个代理
client根据代理向 ContentProvider 发送增删改查
server 端向 client 端发送数据时,client 端会将一个 CursorWindow 对象(还是空的)发给server,server 搜集数据填充到这个 CursorWindow ,Client 就能读到
从apk读取资源,并不是先解压再找资源,而是解析apk中的resources.arsc文件,这个文件存储着资源的所有信息,包括资源在apk中的地址、大小等,按图索骥,可以很快拿到资源文件。安装时不解压自然是节省空间 。
Android手机系统每次启动时,都会使用PMS,把Android系统中所有的apk都安装一遍。app安装过后,都会xml保存安装信息,所以Android系统再次启动后,就可以直接读取之前保存的xml 。
Google推出了 MultiDex 工具,它就是把原先的一个dex文件,拆分成多个dex文件
Hook 只能在自己的进程或者子进程中 ,Hook其他进程需要 Root 权限。对于Activity 的 startActivity 我们有以下几个 Hook 点。上半场:
Activity 的startActivityForResult方法(实际只是重写了)
Activity 的 mInstrumentation 字段
AMN 的 getDefault 方法获取到的对象(以前是 ActivityManagerNative.getDefault().startActivity, 后续变成 ActivityManager.getService() )
下半场:
H 的 mCallback 字段
ActivityThread 的 mInstrumentation 对象,对应的 newActivity 方法和 callActivityOnCreate 方法
动态代理只能对接口进行操作而不能对类,这是因为动态生成的 xxxProxy 中会继承 Proxy 类然后再实现我们的接口,Java 单继承原则,只能针对 接口。
Android P开始google 官方就禁止调用经过 @hide 修饰的方法,插件化面临终结。不过,为了破解这个限制,可以将我们的某个工具类的 ClassLoader 设置为 BootStrapClassLoadder 然后变成了系统类 !参考突破Android P非公开API限制_Android/iOS_刘洪凯_InfoQ精选文章
startService 和 stopService 这种类型的插件化处理方式和 Activity 差不多,都是 在 Instrumentation 中hook ams 的接口,然后 hook H 类的 mCallback ;bindService 就更简单,只需要在 bind 的时候欺骗 AMS 即可,但是 unbind 是无需处理的,因为我们 unbind 是这样操作的:
只需要传入 ServiceConnection 的参数就行,AMS 根据这个 conn 来找到对应的 Service,所以无需欺骗。
bindService 的时候,会将 Service 放入 mService 集合中。
静态广播在 Android系统重启时 PMS 解析 App 中的 Manifest,所以静态广播存在于 PMS ,相反,动态广播最终调用 AMS 实现的,所以动态广播信息存在于 AMS 中。
插件化动态广播其实好解决,只需要能识别有广播的类就行,所以只需要合并 dex 就能做到。静态广播可以在宿主中定义一个 StubReceiver 占位广播,注册很多 action ,收到广播后分发。
一般来说,数据量不超过1M使用Binder,超过就使用ContenProvider
点击屏幕时,事件最先传递给Activity ,在 Activity 的dispatchTouchEvent() 回调中,默认首先调用 getWindow().superDispatchTouchEvent(ev) 将事件交给window 处理:
1、PhoneWindow.superDispatchTouchEvent
组件化的 module 的 manifest 文件在合入的时候,最主要的差别在于,activity 声明的时候,name 属性不再是缩进,而是完整地址
组件化要求功能模块独立,应该尽量少影响 App module 和 Base module ,其中 Base module 尽量做得通用,不受其他模块影响
组件化时,如果使用:
1 2 intent.setClassName("模块包名" , "Activity路径" ); intent.setComponent(new ComponentName("模块包名" ,"Activity路径" ));
2种方式匿名跳转的话,会产生崩溃说在 Activity 里面没有注册(实际上已经注册了),因为包名不能选择 模块的包名,而是应该宿主App的包名。因为打包之后没有组件的包名了。
在组件化架构中,假如移除一些功能 module 和跳转关系,则跳转无法成功,此时,如果要做一些提示,将迁入更多的判断机制代码。而使用路由机制,可以统一对这些索引不到的 module 页面进行提前拦截和做出提示 。另一个重要作用就是拦截,比如可以在跳转前进行登录状态验证
如果不想使用第三方路由,可以采用空类索引的方式。把其他module 打包,知道里面到底有哪些Activity,然后通过某种方式生成一个jar包包含所有的空 Activity ,通过 provider 的方式引入到其他module ,其他module 就能通过startActivity跳转了。
或者单 Activity + 多fragment 的方式,根据路由动态创建 Fragment
有个封装的权限框架:AndPermission,适配各大国产手机厂商
Lib Module 中的资源生成 R 文件不会被 final 修饰,所以我们不能使用switch-case 去使用它,合并后才会。但我们自己可以保证,每个module 的资源以module 名开头,如 haha_ 这样。Butternife 的解决方案(为了避免findiviewById)
哪些资源不能混淆?
反射使用的元素以及用到反射的注解
四大组件
JNI 调用的 Java 方法
js 调用的方法
View滑动的方法:layout、layoutparams、scrollTo、scrollBy、Scroller
Android进阶解密 Android系统分为五层:内核、硬件抽象层、系统运行库(比如ART、C/C++库)、应用框架(为开发人员提供的API-Framework)、应用层(系统应用和非系统应用)
系统启动:
按电源,将bootloader 加载到 RAM ,拉起内核,然后启动 init 进程
init 进程 fork 出 zygote 进程以及启动属性服务(类似 Windows 注册表,App重启后还保持以前的状态而不是新应用),并且监听僵尸进程
zygote 进程注册JNI、通过 JNI 调用 ZygoteInit 之后,进入了 Java 世界
zyote进程创建虚拟机、 server socket 、systemserver 进程、
systemserver 进程会关闭zygote 的 socket,启动线程池 ,创建很多服务并注册:AMS、pkms 等
最后,Launcher 启动(通过AMS 去启动),通过 pkms 获取已经安装的 App
Context 的数量是 Activity 数量 + service 数量 + 1(Application)
记住 Context 的继承关系
zygote 创建一个子进程后,在子进程创建Binder线程池,然后反射 ActivityThread 调用其 main 方法(如果 pid == 0 说明为子进程),连带虚拟机一起 fork 过来了
main 方法中有几件事:prepareMainLooper、创建 ActivityThread 实例 thread、从thread 中获得 H 类的实例、开始 loop 循环
Activity 的 startActivityForResult 最终会调用到 instrumentation.execStartActivity(xx,xx,xx)
AMS 最终调用 ActivityStater.startActivityLocked 启动 Activity,如果有 TaskRecord (代表启动Activity 的栈)也会作为参数传入。在这里会生成 ActivityRecord 对象,并且与 Task 和 Stack 关联。
AMS 是在 Systemserver 进程哦
跨进程调用 ApplicationThread 的 scheduleLaunchActivity ,在这里面会调用 ActivityThread 的 sendMessage 方法,后续调用 handleLauchActivity 以及 performLaunchActivity 方法。随后调用 Instrumentation 的 callActivityOnCreate ,它再调用 activity 的 performCreate ,所以我们说 Instrumentation 是事件总管(其实newActivity 之类的也是经过它)。
Launcher启动应用的流程:
Launcher 用 Binder 向 Systemserver 发起 startActivity 请求
Systemserver 向 zygote 发起fork 请求
zygote fork出 App 进程
App 进程创建 Binder 线程池,反射调用 ActivityThread.main
App 进程就绪后向 Systemserver 发送 attachApplication 告知准备完毕
Systemserver 通过 Binder 向 ApplicationThread 发送 scheduleLaunchActivity
App 进程收到后,向 H 类 sendMessage 发送 LUNCH_ACTIVITY
主线程反射机制创建 Activity ,并回调 Activity.onCreate
context.getApplicationContext 先从 LoadedApk 类型的 mPackageInfo 中获取,如果为 null 的话,调用 ActivityThread.getApplication 方法
像 Activity 和 Application 等地方,他们里面的 mBase (ContextImpl 类型)会 setOuterContext 方法将 Activity/Application 等设置进去,这样 ContextImpl 也能访问 Activity 的变量和方法。
JNI 原理:静态注册就是在java 调用的时候,需要在 native 那里根据全名来找方法:比如java 的 init 方法,在 native 可能就是 com_example_Demo_init,这样就有个映射,并且查找了一次之后,就会缓存起来;动态注册就是会创建一个映射表,java 方法对应 native 特定的签名方法(入参、返回参数一起决定)。
类生命周期:加载、验证、准备、解析、初始化、使用、卸载
堆上分配空间处理并发安全:CAS重试、为每个线程预先分配一小块内存,这块使用完成后,才需要同步分配新的内存。
DVM: Zygote space (系统加载和创建的对象) 和 Allocation Space (我们开发的对象基本上在这)
Java 高并发核心编程 标准线程由3部分构成:线程描述信息(id、名称、状态、优先级)、程序计数器、栈内存。Linux 中默认为每个线程分配 1M 大小 的栈内存。
创建线程的方法:Thread、Runnable、FutureTask(实现了 RunnableFuture 接口(封装了任务状态,线程没执行完,获取结果会阻塞)、里面有 Callable 成员变量(所以可以有返回值))、线程池
Java 线程的 6 种 状态:NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING(sleep(n)、wait(n) 等)、TERMINATED
线程 interrupt 操作其实只是为线程设置了中断状态,有2个作用:如果线程处于阻塞,调用interrupt 会退出阻塞 并抛出 InterruptedException 异常;如果线程处于正常运行,则不受影响,只是标记为被设置为阻塞了。
守护线程需要再 start 之前设置 deamon 状态,否则抛异常;守护线程创建的线程默认是守护线程。
newCachedThreadPool 可以根据任务的多少灵活调节线程数量,并且几乎没有数量限制,只是60秒空闲后会被回收。它的构造方法:
1 2 3 new ThreadPoolExecutor(0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
线程池的 corePoolSize 与 maximumPoolSize 的值可以动态更改
submit 和 excute 2种方式的区别:submit 有返回值 Future ,execute 没有
默认的拒绝策略:丢掉抛异常、丢掉不抛异常、抛弃老的任务,新任务加入、在调用线程执行任务
每个线程都有自己的 ThreadLocalMap
不能显式地声明一个 Class 对象,因为 Class 没有公共的构造方法,Class 对象是在类加载的时候由 Java 虚拟机调用类加载器中的 defineClass 方法自动构造 的
java 对象的结构: 对象头(markword、类对象指针、ArrayLen)、对象体、对齐字节
内置锁:无锁、偏向锁(CAS操作换线程id,成功就是偏向,不成功转为轻量级锁,在安全点停止当前拥有线程的锁)、轻量级锁(是一种自旋锁,CAS尝试将锁的markword 指向自己拷贝的,为什么要替换,因为markword改变了,不会保存以前的数据无锁数据)、重量级锁 只能升级,不能降级
线程间通信:等待-通知、共享内存、管道流
CAS操作防止 ABA 问题,可以采用版本号,jDK提供 AtomicStampedReference、AtomicMarkableReference 来解决
一般碰到CAS 竞争激烈解决办法为:分散热点、使用队列削峰等
CAS 效率提升的例子:分散热点。多线程加法: AtomicLong 变量 value 保存 值,所有操作都是针对该 value,它是一个热点。LongAdder 将 value 值分散到一个数组中,不同的线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行 CAS 操作,热点被分散了。如果要获取完整的 LongAdder 存储的值,只要将各个槽中的变量值累加即可
多线程三大问题:可见性、原子性、有序性
显式锁的 lock 操作一定要在try 语句外,因为抢锁不一定成功,抢锁出现Exception 了,那么就会执行finnaly unlock 操作,如果没获取锁就执行 unlock 会抛出 Exception。并且 lock 和 try 语句(执行抢锁之后的代码)之间不要插入任何代码,避免一场而无法执行到try ,进而无法释放锁。同步回博客 参考lock.lock() 写在 try 代码块内部行吗?_lock放在try里面吗_许大侠0610的博客-CSDN博客
Condition condition = lock.newCondition(); 其中 condition 的 await 相当于object.wait() ,signal 相当于 object.notify() ,在调用 await 和 signal 之后都必须执行 lock.unlock() 。
LockSupport 是JUC 提供的一个 线程阻塞与唤醒的工具类 ,park() 无限期阻塞当前线程;unpark(Thread thread) 唤醒某个被阻塞的线程
锁分类:可重入、悲观、公平、共享 等
CHL自旋锁的关键在于:有新的线程进来时,封装成 Node 放在列表尾部(用 AtomicReference 实现列表,线程安全),让后 node 不断循环(while)查询前去node 的 locked 状态为 false 了(初始默认为true),说明释放锁了,轮到自己拿到锁了。
JDK8 中提供了一个 ThreadMXBean 用于检测线程是否有死锁。
Semophore 称作为 许可管理者更形象,acquire 和 release 方法
AQS 的关键在于:非公平锁:tryAcquire 的时候,compareAndSetState 如果set 成功了,说明获得锁;如果没set 成功,就执行 acquire 从队列里取 Node 出来获取锁(按照公平方式);公平锁没有 compareAndSetState 这个步骤,就老老实实按照 acquire 来操作,只能从队列中队头开始。
Java 线程安全的容器: Collections.synchronizedMap 操作、CopyOnWriteArrayList、BlockingQueue 、ConcurrentHashMap
1.8 及以后的 ConcurrentHashMap 使用 CAS 自旋和 Synchronized 来实现同步,为什么呢,相比 ReentrantLock ,Synchronized 的偏向锁和轻量级锁性能比较高,如果为每个Bucket(桶)都创建要给 ReetrantLock 对象也会带来内存消耗,所以在 Bucket 层面用的是 CAS 。
Android系统源代码情景分析 无
深入理解Android内核设计思想 Binder 是个 misc 设备,Ashmem 也是,为什么这样做呢?misc 相对比较简单,注册只需要 misc_register 就能实现。
我们需要向 Service Manager 查询各个 Service 的地址,但是 Service Manager 本身也是个服务器,它的地址是 0
Binder 机制中:B 通过 mmap 申请到一块内存后,Binder 驱动的 buffer 也有个指针指向某个虚拟地址,对应的物理地址和 B 的那块内存是一样的,这时候,A 只需要通过copy_from_user 复制到Binder 所指向的 buffer 空间,即可实现数据传递到 B 空间了。
深入理解Java 虚拟机 程序计数器是虚拟机规范里面唯一没有规定任何 OutOfMemoryError 的区域
栈帧包括:局部变量表、操作数栈、动态链接、方法出口信息
方法区域:存储已经加载的类信息、常量、静态变量、运行时常量池(存放有字面量和符号引用)就在这里面
直接内存不属于虚拟机数据区的一部分,可以通过Java 堆中的 DirectBuffer 对象去操作
对象没有与 GC Roots 有关联也不是非死不可,会被标记让其执行重写的 finalize 方法(如果没有重写就不用执行),这个期间如果重新建立roots 之间的联系就可以逃避回收。
CMS 收集器的步骤: 初始标记、并发标记、重新标记、并发清除。其中,初始标记、重新标记 这两个步骤仍然需要“Stop The World”。初始标记仅仅只是标记一下 GC Roots 能直接关联到的对象,并发标记就是根据初始标记过程中标识出来的直接关联对象,并发标记存活的对象。由于是多线程的,所以 CMS 对于CPU 是非常敏感的。
分配策略:优先Eden、大对象直接进入老年代、长期存活去老年代、动态年龄判定、空间担保
解释器可以作为编译器激进优化时的一个“逃生门”
深入理解Kotlin协程 1 2 3 4 5 6 7 8 9 10 suspend fun bitmapSuspendable (url: String ) suspendCoroutine<Bitmap> { continuation -> thread { try { continuation.resume(downLoad()) } catch (e: Exception) { continuation.resumeWithException(e) } } }
异步代码同步写的一个例子。
可挂起的 main 函数,还是正常的main 函数,挂起函数被封装了,然后在 main 方法中调用。
Kotlin 中,挂起方法能调用普通方法,但是不能反过来,原因就是挂起方法是需要传入 Continuation参数的。
suspend 函数的调用处称为挂起点,如果判断挂起点出现异步调用(resume 函数与对应的挂起函数调用是否在相同的栈上,有可能发生在 Handler.post 上,线程不一定切换 )当前协程就会被挂起。
挂起函数同步返回时,传入的 continuation 的 resumeWith 不会被调用,函数实际返回值就是挂起函数返回值;挂起函数挂起,执行异步逻辑,此时函数返回的是一个挂起标志(一个枚举量,有 SUSEPEND/RESUME 等),调用方根据这个标志就知道函数需要挂起了。
协程上下文 context 类似一个单链表,根据 context 的名字就能找到这个 context ,比如这样的 : context[CoroutinExceptionHandler].onError()
比如要写个延迟多少秒之后执行的协程(其实就是定时回调机制):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private val executor = Executors.newScheduledThreadPool(1 , object : ThreadFactory{ override fun newThread (r: Runnable ) return Thread(r, "Scheduler" ).apply { isDaemon = true } } }) suspend fun delay (time: Long , unit: TimeUnit = TimeUnit.MILLISECONDS) suspendCoroutine<Unit > {continuation: Continuation<Unit > -> executor.schedule(object : Runnable{ override fun run () continuation.resume(Unit ) } }, time, unit) } }
计算机网络-自顶向下方法-中文第6版 TCP 为什么要拥塞控制?因为能给因特网整体带来好处,而不是给我们的通信进程带来好处。
TCP首部 20 个字节,UDP 只有 8 个
拥塞控制算法:慢启动、快速恢复(拥塞窗口减半,之后执行拥塞避免)、拥塞避免(tcp发送成功一次后不是翻番,而是缓慢增长),如何判断拥塞?收到 3 个冗余的 ACK
ssl 握手得先建立 TCP 连接
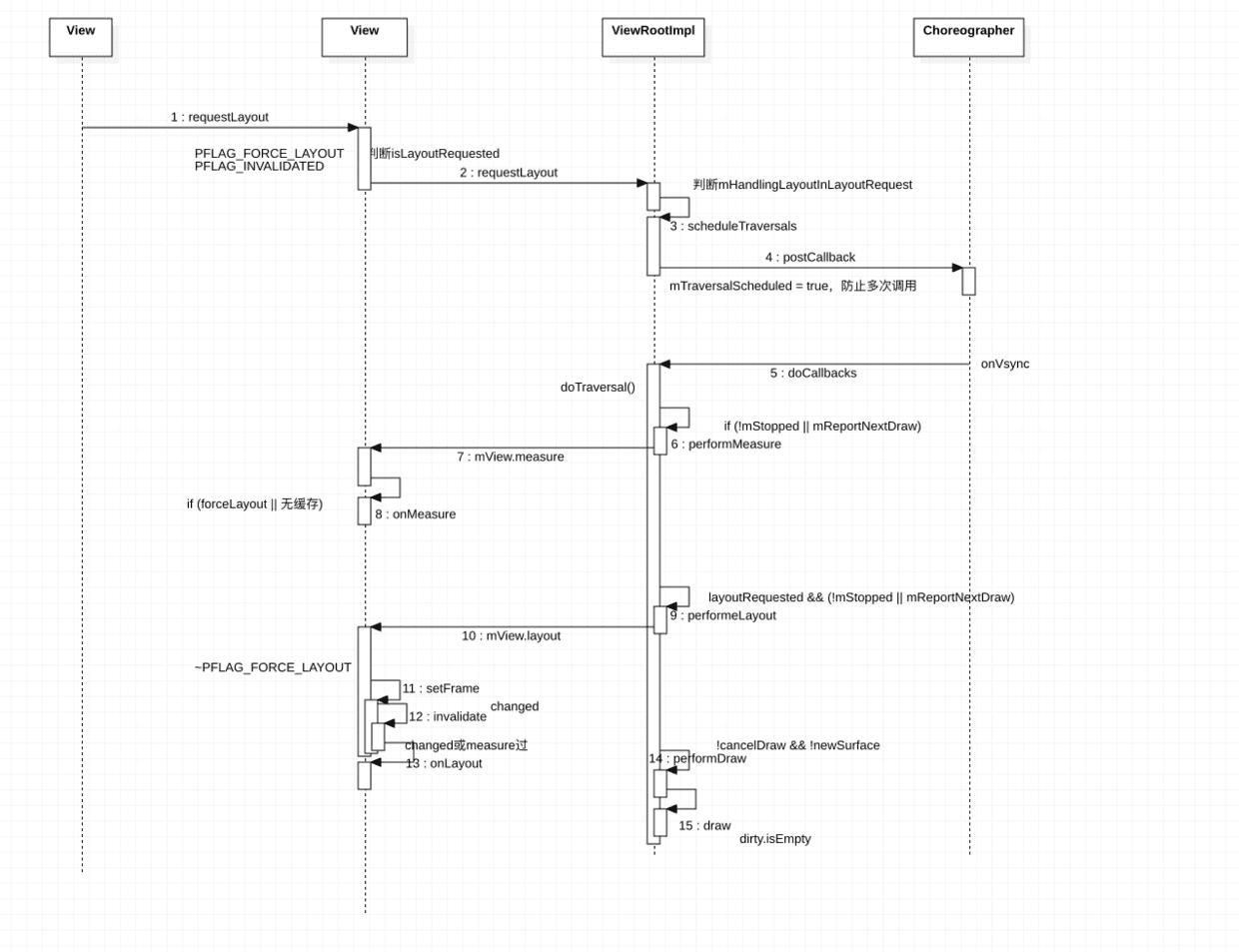
Android自定义控件开发入门与实战 measure 用于测量控件大小,为 layout 的时候提供建议,最终用不用还得看 layout 本身
MeasureSpec 值中模式3种:UNSPECIFIED、EXACTLY(具体值或者match_parent)、AT_MOST(wrap_content)
当模式是 EXACTLY 时,就不必计算值了,因为这个大小是用户指定的,我们不应该改。但当模式是 AT_MOST 时,就需要将大小设定为我们计算的数值,因为用户使用的是 wrap_content
由于需要计算自己的宽高,在onMeasure 的时候,就得先知道child的宽高,所以就回将child 也测量了一遍,这样,measure 之后每个view 都存了自己的大小,最终都会调用 setMeasuredDimension :
1 2 setMeasuredDimension((measureWidthMode == MeasureSpec.EXACTLY) ? measureWidth : width, (measureHeightMode == MeasureSpec.EXACTLY) ? measureHeight : height);
getMeasuredWidth 函数在 measure 过程结束后就可以获取到宽度值,而getWidth 需要在 layout 完成后才能获取到高度值(因为是根据right - left 得到)
如果要自定义 ViewGroup 支持子控件的 layout_margin 参数,则自定义的 ViewGroup 类必须重写 generateLayoutParams() 函数,并且在该函数返回一个 ViewGroup.MarginLayoutParams 派生类对象!
Android进阶指北 linux 提供的进程间通信方式:共享内存、socket、管道、信号、信号量 等。
管道的主要思想是在内存中创建一个共享文件 ,,它不属于文件系统并且只能存在于内存中。管道采用半双工 通信方式,数据只能在一个方向上流动。
HTTP 权威指南 常见TCP 时延的操作:TCP 握手、拥塞控制、捎带确认的TCP延迟确认算法、TIME_WAIT
消除时延带来的影响: 长连接(避免握手、慢启动、TIME_WAIT)、并行连接、管道化链接(可以将多条连接放入队列,当第一条请求发出之后,第二条第三条请求也可以开始发送了,这样做可以降低网络环回时间,提高性能)
TIME_WAIT :2 * MSL
SSL/TLS 是在 HTTP 与 TCP 层之间。常见的对称加密算法:DES、RC2、RC4
数字证书的内容:证书颁发者、证书颁发者签名、过期时间、对象名称、对象的公钥、使用的算法 等
证书校验有几个方面:日期检测、颁发者可信度检测、签名检测、站点身份检测(防止使用别人的正规证书,所以要校验证书的host 和 当前服务器的host)
Kotlin核心编程 我们使用 lateinit 和 by lazy (默认会加上 Synchronized 同步锁)这 2 种语法实现延迟初始化。其中 by lazy 用于 val 类型, lateinit 用于 var 类型。
lateinit 不能用于基本类型,如 Int、Long 等
Kotlin中的类和方法默认实现反编译成 Java的时候,会被final修饰,所以,类默认是不能被继承的,方法默认也不能被覆写的
Kotlin通过 sealed 关键字 来修饰一个类为密封类,若要继承则需要将子类定义在同一个文件中 (反编译成Java 就能知道,sealed 类是用抽象类实现的)
kotlin 的内部类必须在前面加上 inner 关键字,否则就只是在同一个文件种写了几个类而已。
kotlin 用起来有哪些比 Java 爽的?
当且仅当Kotlin编译器确定在类型检查后该变量不会再改变,才会产生Smart Casts
Kotlin 中的 Int 类型等同于 int, Int? 等同于 Integer !
其实,泛型类型擦除并不是真的将全部的类型信息都擦除,还是会将类型信息放在对应 Class 的常量池的。所以,我们能通过相应的方式来获取这个类型信息,使用匿名内部类就可以实现这种需求。匿名内部类在初始化的时候就会绑定父类或者接口的相应信息,这样就能通过获取父类或者父接口的泛型类信息来实现我们的需求,你可以用这样一个类来获取任何泛型的类型,我们常用的Gson也是使用了相同的设计 。
在类种定义扩展方法,就只能在类种使用,它没有static 关键字。如果在外面定义的那么到处可以使用,只需要引用就可以
扩展方法默认是静态方法,扩展属性是利用方法实现的,所以没有默认值。
如果扩展函数和现有类的成员方法一样,那么成员方法的优先级高于扩展函数。
TCP IP详解卷1:协议 在UDP 中,源端口号是可选的,如果数据报的发送者不要求对方回复的话,它可以被置为 0。
2个完全不同的服务器可以使用相同的端口号和 IP 地址,只要它们属于不同的传输协议。因为:TCP 的端口号只能被 TCP 使用,UDP 端口号只能被 UDP 使用
定义一个分组窗口作为已经被发送但是还没完成确认 的分组集合,我们把窗口中分组的数量称为窗口大小 ,收到确认之后,发送方保存的副本可以释放了。接收方维持这个窗口的意义:哪些分组是下一步期望的,哪些是接收了也会被丢弃的。
在本地与外地的 IP 地址、端口号 都相同的情况下,2MSL 状态能防止新的连接将前一个连接的延迟报文解释成自身数据的状况
假如一台与处于 TIME_WAIT 状态下的链接相关联的主机崩溃,然后再 MSL 内重新启动,并且使用与主机崩溃之前处于 TIME_WAIT 状态的连接相同的 IP 地址与端口号,那要怎么处理呢?解决办法就是:在崩溃或者重启后,TCP 应该在创建新的连接之前等待一个 MSL 的时间,这段时间称为 静默时间 。
所以我们说 2MSL 状态能防止新的连接将前一个连接的延迟报文解释成自身数据的状况只有在相关主机未关闭的情况有意义
TCP有2套机制来完成重传:基于时间-发送数据后设置计时器,超时还未收到ack则重传;基于确认信息:收到 3 个相同的 ack (也叫快速重传)
在TCP 握手阶段,SYN 、ACK 等数据包并未包含实际数据,由于 TCP 对不包含数据的报文段不提供可靠传输 ,意味着若出现丢包不会重传,因此无须设定重传计时器 !
当TCP 超时重传时,并不需要完全重传相同的报文段。TCP 允许执行重新组包 发送一个更大的报文来提高性能。
有一类 DoS 攻击称为 低速率DoS 攻击。向主机发送大量数据,使得受害系统持续处于重传超时的状态,攻击者可以预知受害TCP何时启动重传,并在每次重传时发送大量数据。解决方案:随机选择 RTO,使得攻击者无法预知准确的重传时间
从小工到专家 无
深入探索Android热修复技术原理 AndroidManifest 出现bug是无法修复的,因为它是由系统进行解析的,解析过程不会访问补丁包
每一个Java 方法在 ART 虚拟机种都对应一个 ArtMethod ,记录了这个 Java 方法的所有信息,包括所属类、访问权限、代码执行地址等
ArtMethod 存储在 ArtMethodArray 中,多个 ArtMethod 紧密排列,所以,一个 ArtMethod 的大小刚好就是两个相邻的 ArtMethod 的起始地址的差值。
只是替换了 ArtMethod 的内容,但是补丁方法所属的类和原有方法所属的类不同,被替换的方法访问这个类的其他 private 方法的时候已经不做检查了,推测是在 AOT 代码的时候做一些检查和优化了。
一旦补丁类中出现方法的新增和减少,就会导致这个类以及整个 Dex 的方法数发生变化, 会伴随方法索引的变化, 导致无法访问。所以 sophix 热修复不能有方法数变化。(所以要注意补丁包中不要有新增内部类-会和顶级类一样编译,方法的内联、方法裁剪-无用参数被裁掉、)
如果类所引用到的类和当前类都在同一个dex中的话,dex 中 所有的类都会被打上 CLASS_ISPREVERIFIED 标记。QQ空间的解决方案:一个单独的无关类被放在一个单独的dex中,原 dex 中所有的类构造函数都引用这个类,所以都不会有 CLASS_ISPREVERIFIED 标记。不过会导致类的校验和优化都在类加载阶段进行,影响性能。
了解决 Art 下类地址写死的问题,Tinker 通过 dex merge 成一个全新的 dex 整体替换掉旧的 dexElements 数组。ART 下将补丁dex 放在 dexElements 最前面即可。
资源修复:阿里的Sophix 还是使用以前的 AssetManager 对象,在 Android kk 以下 是先析构 AssetManager 再重构的时候将补丁资源也加入,避免了一些额外操作。
修改资源,比如替换了一张图片,那么将其视为新增资源,在打入补丁包的时候,代码引用处也做相应修改,把原来使用的旧资源id的地方变为新的 id,所以代码也配合修改了。
为什么很多方案说资源补丁一定要重新创建一个 AssetManager 对象,那是因为 1)在某些版本上addPath 之后,会从前往后遍历,补丁包资源在后面,所以无法遍历到。2)有些低版本addPath 只是将路径加进去了,但是已经错过了资源解析的时间,同样不起作用
so 一般不能实时生效,改成冷部署重启后生效。
现代操作系统(第三版) 实际上只有一个物理程序计数器,所以程序运行时,它的逻辑程序计数器装入实际的程序计数器,暂停时,又保存回逻辑程序计数器。
操作系统维护一张进程表,保存各个进程的信息:程序计数器、堆栈指针、内存分配状况、打开的文件状态、调度信息等
死锁条件:互斥条件、不可剥夺、占有等待、环路等待
第一行代码 fragment的生命周期:onAttach、onCreate、onCreateView、onActivityCreated、onStart、onResume、onPause、onStop、onDestroyView、onDestroy、onDetach
普通广播发送的时候,所有接收器几乎同时收到,这也意味着它无法被截断
不要再onReceive方法中添加过多的逻辑或者进行任何耗时的操作,因为广播接收器中是不允许开启线程的 ,如果有耗时任务,建议放在 Service 里面做
同步回博客第5章 为什么广播接收器不能开启线程或者耗时操作,因为广播接收器里面超时时间时 10s ,超过 就 ANR ,其次,广播接收器的生命周期很短,如果开了线程,广播已经结束了,线程还在执行,导致生命周期不一致。
问题记录 ListView 中维护了2个 item 列表: ActiveViews 和 ScrapViews ,前者存放屏幕上展示的 View ,后者存放回收的 View 。ScrapViews 中的 view 会变成 contentView 去复用。
每种类型的item 都会创建一个 RecycleBin 对象,都有独立的 ActiveViews 和 ScrapViews
baidu.com 和 .baidu.com 存储 cookies 是 2份,需要单独清理。
如果 RecyclerView 默认带有动画的情况下,notifyItemChanged 会创建一个新的ViewHolder !
面试题 视频播放慢:避免加载过大的视频头(换格式或者分为多个视频),加载视频头才能下载 moov 数据,才能解析视频。将 moov 移到前面来一点,少一次 seek 请求。 适当的时候可以预加载视频头。
线上监控:
卡顿:Looper.getMainLooper().setMessageLogging()
FPS:Choreographer.getInstance().postFrameCallback()
ANR:连续发生多次的未累加
Net : 360 Argust 切片判断 okhttp ,然后添加 interceptor
Activity : Hook Instrumentation
启动时间:Hook Instrumentation,在 Instrumentation 的 callApplicationOnCreate 方法执行时,就记录下 Application 启动的时间,然后 callActivityOnCreate 记录下第一个 Activity 的启动即可获得冷启动的启动时间
Native 层崩溃: 爱奇艺的 xCrash
ANR : 读取anr 只适合低版本手机。xCrash 知道发生 ANR 时回再Native 有 信号。
ViewPager2 不像 ViewPager 那样帮我们处理了事件冲突。并且 ViewPager2 是 final 的,不能继承,所以一般要给它包一层Layout ,在 layout 里面处理冲突。
eventBus 支持跨进程吗?不支持,因为 EventBus 那些时间都是通过单例实现的。
http3:
基于UDP
握手链接很快,1个RTT
无需等上一个请求ack 之后才能下一个请求,因为是基于stream,多路复用
拥塞控制可以在应用层修改,而不需要到TCP层
流量控制也类似滑动窗口
http3 不以四元组(ip、端口)为标识,而是以64位随机数,即使端口或者ip变化都不影响。
面试题目 同步回博客 kotlin 爽在哪?更安全-空和非空、扩展函数、if-when 有返回值、协程、is 比 instance 好用-不用再强转、高阶函数-无需自己去创建一个callback 接口之类的
协程不能有阻塞操作,否则整个线程被阻塞。擅长处理 IO 密集型操作,不适合cpu 密集型。
在 onInterceptTouchEvent 中,首先是ACTION_DOWN 这个事件,父容器必须返回false,即不拦截,因为一旦拦截了 ACTION_DOWN ,后续的 ACTION_MOVE 和 ACTION_UP 都没法再传递给子view了;
可以让父空间不拦截,如果是ViewGroup的话,可以在 onInterceptTouchEvent 方法中请求忽略外层容器拦截事件:getParent().requestDisallowInterceptTouchEvent(true) 。如果是View的话,那么把getParent().requestDisallowInterceptTouchEvent(true) 写在setOnTouchListener 方法中可能更合适。
性能优化具体优化效果:
内存从经常性的 380M 左右降低到 330M 的水平
页面秒开(talkingdata数据显示,优化前88%左右,93%的收集数据显示1秒以内打开,从onCreate 到onResume)
过度绘制(优化前几乎所有主要页面都是红色-蓝、绿、粉、红 分别代表过度绘制 1,2,3,4 次,优化后基本上都是蓝绿,粉色的比较少,红色的可能只有极少数小块)
App启动速度加快,冷启动,从3.5秒左右降低到1秒左右(录屏,记录从启动到展示flash页面,多次时间取平均值)
网络连接,网络的错误率4%(按次数统计出的)左右,dns加速后,网络错误率基本上保持,主要集中在网络超时、网络无连接两种异常,其中网络超时占了40%左右
ArrayMap 有2个数组,左边的数组存储了 key 的 hashcode 值;另一个数组存储 key-value 对(key和value 在相邻的空间),查找首先计算key 的hashcode ,之后根据二分查找得到其再左边数组中的index ,然后 在右边数组index处上下查找。
好处:避免了自动装箱,数组只存了key 的hashCode,节约空间;同时也避免了hashmap 的空间浪费;但是插入和删除元素时,由于是数组形式,需要移动元素,因此效率不高
SparseArray 适用于 key 为 int 、value 为 Object ,也是 2个数组,避免了装箱,连key 的 hashcode 都不用计算了。插入和查找也是二分法。此外还有 SparseIntArray 、SparseLongArray 等
为什么要三次握手:交换起始编号、确认双方收发能力正常、
HandlerThread 本质还是个 Thread ,只不过给做了prepare 的工作,并且能线程安全地获取到 Looper 而已,真正使用的时候,比如在 IntentService 里面,一般还是需要自己写 Handler ,只不过用 HandlerThread 的 Looper 去初始化 Handler 。(因为使用它自带的 getThreadHandler 获得的 Handler 功能可能不是我们想要的 )
DNS 服务解析:119(腾讯的 119.29.29.29) 和 114(114.114.114.114)
webview 的 ip 直连: 在WebviewClient 的 shouldInterceptRequest 回调中自定义构建的网络请求,获取结果后,自行重新组装 WebResourceResponse 对象
做的安全努力: 签名本地验证、https证书本地验证、广播改为本地广播、sp 加密、加密key 在native 生成
稳定的排序有:冒泡、插入、合并 ,不稳定排序:选择、shell、快排、堆排
项目 广告-小程序:根据appId 获取配置信息,判断是否需要登录态,如果没登录,startActivityForResult 登录,在 onActivityResult 中跨进程更新登录态。多进程也带来断点调试问题,开发的时候去除多进程
AIDL 支持基本的类型,int、long、boolean、float、double、String,要支持对象,还得自定义一个 aidl文件:
1 2 3 4 5 文件:AidlUserInfo.aidl parcelable AidlUserInfo;
高级进阶课 如果你使用了 Thread.sleep() 这样的系统方法,那么使用 interrupt 方法来停止线程,否则一律使用 boolean 标志位停止线程
总结:如何进行锁优化 :
异步,不一定涉及到多线程,比如你setOnclickListener,它不是马上执行,而是等点击再相响应。
如果你的Activity 暴露出去了,那么攻击者可以来攻击,让你的Activity 拒绝服务.传入一个不存在的类,这样 intent.getExtra() 反序列化的时候就崩溃。
图片计算大小:
从 assets:如果png,采用ARGB_8888 的话呢,那就是 宽 × 高 × 4 ,因为每个像素要有4个字节,这里 4个8,每个8代表8个比特
从 hdpi: 假设图片的大小为 112px * 131px ,格式png,如果你图片在 hdpi 中,那么系统会认为你这个图片的密度本身就是1.5,如果你这时候有个2.75密度屏幕的手机,那么它就会换算,比如说宽度 : 112 / 1.5 * 2.75 = 205.333…. ,系统会四舍五入取 205 ,同理高度会换算成: 131/1.52.75 = 240,所以如果使用 ARGB_8888 ,那占用内存就是 205 240 * 4。同理啊,如果手机屏幕大点,比如说是3,那就是 131/1.5*3 和 112 / 1.5 * 3 了。
在把它放到xxhdpi,这时候密度是 3 了,这时候如果手机是 3,那就得是 131/3*3 和 112 / 3 * 3 了
所以如果在 mdpi中,那默认图片密度是 1了,那么在 dpi 是 3的手机上,图片宽高应该是 131*3 和 112 * 3
以此类推,其实在drawable,后面没有带dpi 的,那效果和 mdpi 一样,默认图片是 1
如果是nodpi ,告诉系统不会缩放,就按照原始的像素,131 和 112 了
所以宽高的计算方式 : 图片/dpi * 屏幕dpi
设计短视频:
视频如何处理?
视频来源?自有还是第三方?
视频由用户上传还是专业供应平台
是否需要建立用户关系链
支持分享?
支付系统打赏啊?
社交。聊天
播放器比较耗电
视频防止对手获取
防止广告被劫持
设计网络框架:
不局限于http,还可以 websococket
单向请求还是双向请求啊?
支持异步请求?使用Rxjava 还是kotlin 协程?
要考虑可移植性啊?
缓存策略,多大啊?如何淘汰?
全局数据拦截器,对所有请求ip替换啊,对公共结果处理啊
日志输出,json,pb 转换为可视化
重试机制,3s、6s 之后再重试,最多重复多少次,防止死循环
参数组装,bean?hashMap,或者类似Retrofit 使用注解配置
协议体可以使用 Builder 模式
数据传输与拦截使用责任链模式
数据序列化
DNS 增强-httpDnsServer ,比如google的,还有aliyun 和腾讯云有,可以默认支持几个
http3的特性:
基于 UDP:比较快速
建立连接快:1 RTT 就可以,主要是获取 Server Config,缓存这个 config 后可以 0 RTT
连接迁移:不基于四元组,而是使用64位id唯一标识一条连接
队头阻塞/多路复用:Http1.1 通过一条 TCP 同时传输 10 个请求,其中1,2,3请求被客户端接收,但第 4 个请求丢失,那么5~10 请求会被阻塞,这就是队头阻塞;此外,TCP 本身还有队头阻塞问题,所以 Http2 虽然将数据分为多个 frame 来解决上层的队头阻塞问题,但是它还是基于 TCP 。并且 ssl 也是有队头阻塞问题,因为用一堆数据加密,然后接收方要等这一堆数据都到了才能解密。而 http3 传输单元是 Packet ,加密、传输、解密都是基于 packet ,避免 ssl 队头阻塞;并且基于 udp 也不会有接收顺序要求,避免tcp 的队头阻塞。
拥塞控制:http3 可以在应用层设置拥塞控制算法,比较便捷
使用异步 msg 需要谨慎,不留神就容易导致 App 假死,还不好排查
卡顿监控:
ANR 就是做某个操作时埋炸弹,比如 AMS 在 scheduleCreateService 的时候,就通过 Handler 发送了个 SERVICE_TIMEOUT_MSG 延时消息,如果操作执行完成,就将消息移除。
ANR 监控:
系统信号(不可取):当ANR 发生时,会有系统信号 SIGNAL_QUIT 发出,一般是这时候去获取trace.txt文件来分析。但是这种方法在高版本需要root 权限才能获取文件,所以线上环境不可取。
ANRWatchDog(不可取):开一个线程,post 一个请求到主线程执行修改标记位操作,5秒后检查标记位是否更改,未更改说明ANR。但是会有漏捕捉
ANRMonitor(可行,改进 ANRWatchDog):每秒post到主线程执行一次修改标记位,每秒检测一次,如果有一次没改过来,就次数 + 1 ,如果有 5 次没有执行,说明ANR 。
Fresco 图层原理:维护了一个 Drawable 序列,分别代表不同层的显示图,如果某层没有设置,那就是 null,如果某层要隐藏,比如,真正的图片加载成功,placehoder 图片要隐藏,就将 placeholder 的 alpha 设置为 0 即可,这样就不会绘制。
Fresco 如何将图片放到 Ashmem 中呢?通过设置 BitmapFactory.inpurgeable = true ,这样decode 出来的bitmap 是在 Ashmem 中的,GC 无法直接回收它,当 Bitmap 使用的时候,就 pin 住不会释放,使用完成后 unpin 操作,这样系统在未来某个时刻会释放这部分内存。
可以学习 LeakCanary2 的策略无需用户自己去注册,利用ContentProvider 去自动执行 install 操作。
Toast 的 makeToast 创建了一个 toast 对象和 TN 对象(Stub对象,客户端),TN 里面还有个当前线程Looper创建的 Handler (控制toast 的显示和隐藏),这也是为什么在子线程中发送 Toast 时需要 prepare 的原因。创建的Toast 会放到 framework 中的队列里面,然后被不断取出来将要显示的Toast 的 View 放到 WindowManager 中,就显示出来了。
事件发生顺序:dispatchTouchEvent -> onTouchListener ->onTouchEvent ->(super.onTouchEvent 中) onLongClick -> 如果 onLongClick返回 false ,还会执行 onClick (onLongClick 是在 DOWN事件中判断的,onClick 是在 UP 事件中判断的,二者都是在 onTouchEvent 中)
Handler 中的执行顺序:
如果有 msg.callback 则执行;
否则,mCallback 是否返回true ,true 的话就不往下走
执行 handleMessage
viewstub 的原理:
关于不可见:visible 为 gone 、setWillNotDraw(true)、onMeasure 的时候 setMeasuredDimension(0, 0)、onDraw 方法和 dispatchDraw 方法都是空实现。
关于展示:setVisible 的时候,如果真正的 View 有 inflate 出来,那就直接 visible 。否则触发 inflate: 在里面以 ViewStub 的patent 来 inflate 出来真正的 view ,然后将 ViewStub 自身的参数、以及在 parent 中的 index 全部给真正的 View ,之后 ,在parent 中将 ViewStub 自己 remove 掉。
能多次 inflate 吗?不行,inflate 其实就是将真 view 替换 ViewStub 的过程,从parent 的移除的时候,ViewStub 都已经没有 parent 了,就会报错
Cookie 存储在 客户端,而 Session 存储在 Server 端
http2对比 http1 : 新的二进制格式(非文本了)、多路复用、header 压缩、server push 、更安全的 SSL
粘包:TCP 建立连接后,A端给B端发先发送 100字节,接着再发送 100 字节,B端会收到 2 次 100 字节吗?答案是不一定的。因为操作系统底层有 MTU 的概念,就是网络中一个数据包的最大长度,如果要发送的数据超过这个长度,就分包;否则,如果数据太小了,可能几个数据合在一起发送了,这是“粘包”。但是如果传输的是指令之类的,就不能粘包,我们还是要区分的,解决方案:1)定长结构 2)不定长结构,带上包的长度 3) 短连接,发送一个数据包就断开 TCP ,不过这样性能低下
心跳:TCP 建立连接后,一端拔掉电源线,另一端能首都奥通知吗?不会。解决方案:心跳包。
TCP 如何保证数据的正确性?
为什么 wait、notify 在 Object 中?sleep 在 Thread 中?
假如 notify 、wait 在 Thread 中,在wait 之后如何通知其他竞争者呢?这就很麻烦了
为什么 wait-notify 要在同步块中?因为可能出现 lost Wake-Up 问题,漏掉 notify 事件。
线程间通信方式:notify-wait、Condition 实现等待/通知、内存共享
synchronized 如果锁对象是 Thread ,并且在wait ,那么在 thread 执行完之后,无需notify 就能继续执行 wait 后面的语句了。join 就是这个原理,它里面就是利用 wait 实现的。
Java 多态:
概念:不同类对象(父类的多个子类)对同一个方法有不同响应。
存在的条件:要有继承关系,要有重写方法,父类指向子类对象。
如何实现的:动态绑定,在执行期间判断实际应用类型,调用相应方法
表现:继承 和 接口实现的时候方法重写、同一个类的 方法重载
ArrayList: 初始容量是 10,容量不够就先扩容到 1.5 倍,还不够就直接扩充为需求值,之后拷贝到新空间,比较耗时。插入删除也耗时,但是索引很快;LinkedList: 双向链表本身就占用了更多空间,访问下标时,如果i超过了链表长度的一半,会从末尾开始遍历找。插入删除比较迅速。
HashMap 允许null 键/值,会将key = null 时放在第 0 个位置。在链表插入的时候,使用头插法,因为设计者认为刚插入的比较容易使用到。默认桶长度是 16 ,每次扩容都必须是 2 的幂(hashcode & (len - 1) 的每位都是1,都能起作用),并且将高16位与低16为异或操作作为 低16的值,避免只有低4位是有效的,进一步降低碰撞。
HashMap 链表转红黑树问题:一是数组长度达到 64;二是链表长度达到 8 ;退回链表是链表长度变到 6 。
WeakHashMap:两次调用 size 可能值不一样,因为有些元素可能被回收了。
hashcode 生成注意事项:是int型,防止溢出、不同的对象hash尽量不同,防止碰撞、无论何时同一个对象的hashcode 应该都是同样的值
无父类情况:静态属性、静态代码块、非静态属性、非静态代码块、构造方法
有父类情况:父类的静态属性、父类的静态代码块、子类的静态属性、子类的静态代码块、父类的非静态属性、父类的非静态代码块、父类的构造方法、子类非静态属性、子类非静态代码块、子类构造方法
普通的类方法是可以和类名同名的,它与构造方法唯一的区别就是构造方法没有返回值
CharSequence 是一个接口,String、StringBuilder、StringBuffer 都实现了这个接口,它们三个的本质都是通过字符数组 实现的。StringBuilder、StringBuffer 的char 数组开始的存储空间是16,如果append() 过程中超过这个容量,将会申请新的空间,并把老的数组一起复制过去。
为毛 String设计成不可变?
字符串常量池的需要。
允许String对象缓存HashCode。String 对象的哈希码被频繁使用,比如在HashMap 中。
其次,为了安全。多线程安全:多个线程同时读一个资源,不会引发竞态条件,但是对资源做写操作就会有危险,这样保证String使用线程安全。url、反射所需要的参数等都是String类型,如果允许改变,会引起安全隐患(比如非法访问:如果String可变,那么可以在安全检测后,修改String值,导致非法访问)。
注解@interface 编译后再反编译变成了interface,而且自动继承了Annotation
父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象
更新UI检查线程是在 ViewRootImpl 中,只要 ViewRootImpl 的创建线程和 View 的创建线程在同一个线程就行,并不要求主线程。所以你可以在子线程创建一个 Dialog,以及自己获取 WindowManager 创建 TextView add 到 Window 中,在子线程也能正常展示。
LruCache 使用 LinkedHashMap 实现,可以选择按照插入顺序还是访问顺序,如果是访问顺序,那么get 之后,就会把节点删除,再把这个节点插入到头节点,淘汰就从尾巴淘汰
RecyclerView 优化:
A 的 onPause 必须执行完 B 的 onResume 才会执行;等 B 的 onResume 执行完成后 A 才会覆盖看不见,A 的 onStop 才调用。同样,在按返回键的时候,B 的 onPause 执行,然后 A 的 onRestart、onStart、onResume 之后,B 才会 onStop 和 Destroy 。
Bundle 内部使用的是 ArrayMap ,比较节省内存。
SP 在内存中存储的数据结构是: static ArrayMap<String, ArrayMap<File, SharedPreferenceImpl>>,它是静态的,在每个进程都只有这个唯一的
Sp 每次 edit() 操作都会创建一个 EditorImpl 对象,所以不要频繁 edit() 操作。它的 apply 操作会交给 HandlerThread 使用单线程的子线程执行。
内存泄漏的场景:资源型对象未关闭(File、Stream 等)、注册对象未注销(EventBus 等)、非静态内部类创建静态实例、匿名内部类和异步线程、Handler 的临时内存泄漏
APK安装步骤:判断安装源合法性、apk复制到 /data/app目录、解析apk(包括四大组件、签名校验等)、dexopt 操作优化、更新权限信息到 PMS、完成安装发送广播
如果仅仅只要Bitmap 的尺寸和类型,那就没必要将其加载到内存中,我们在解码的时候设置 BitmapFactory.options 中的 inJustDecodeBounds 属性为 true 即可。这样避免为 bitmap 分配内存,但是能读到图片的尺寸和类型
如果图片太大,我们可以使用 BitmapRegionDecoder 来实现,每次只加载其中一个矩形区域
ANR:
input 操作 5s 未响应
provider 是 10s
广播: 前台 10s ,后台 60s
Service: 前台 20s ,后台 200s
证书校验:assets文件保存 crt 格式证书,通过 CertificateFactory 将 crt 文件加载成 x.509 格式的对象,对比证书的公钥和服务器返回的证书的公钥是否一致。
BitmapFactory.Options 用于内存优化:
RecyclerView 缓存ViewHolder 有4个等级,优先级从高到低有4个层次:
mAttachedScrap: 缓存屏幕中可见范围的ViewHolder
mCachedViews: 缓存滑动时即将与RecyclerView 分离的 ViewHolder,存有postion信息,如果需要复用,直接可以拿过去用,不需要改变数据。默认最多2个
ViewCacheExtention: 用户自定义的扩展缓存,需要用户自己管理View的创建和缓存。
RecycledViewPool:缓存池。在 mCacheViews 中缓存已满时,就会将旧的ViewHolder 放到RecyclderViewPool,如果 RecyclderViewPool 满了,就不会再缓存。从这里取出的缓存需要bindView 才能使用(本质上是一个SparseArray,其中key是ViewType(int类型),value存放的是 ArrayList< ViewHolder>,默认每个ArrayList中最多存放5个ViewHolder )。
webview 的速度优化可以将一些静态资源放在本地,之后 拦截 H5 请求,如果是请求那些静态资源则可以直接从本地加载,提升速度。
享学Java 元注解: @Target (TYPE、METHOD、FIEDL、PARAMETER)、Retention(RESOURCE、CLASS、RUNTIME)
字节码插桩技术:只有到字节码的时候才能操作,比如说组件化,互相都不知道对方存在,字节码的时候才能路由过去,ARouter 路由表实现。
如果有final 类型的int 值 a,然后有 get 方法返回这个 a,那么反射改掉这个 a 的值,那么 get 方法的时候需要注意,可能是直接返回老的值,不会被改掉。这是Java 优化导致的
反射方法调用为什么耗时:
调用 Object.invoke(Object object, Object…args) 这个 invoke 时,发现参数是变长的了,意味着需要有数组承载
其次,变长参数都是Object ,意味着可能有装箱、拆箱操作
反射调用耗时还有临时变量太多
栈帧里面包含的内容:局部变量表、操作数栈、方法出口(记录的是调用方执行到哪一行了)、动态连接
对象在堆上内存分配2种方式:指针碰撞、空闲列表,分配的时候需要注意线程安全,有2种方式解决:1)CAS 重试、每个线程本地分配一部分内存
对象头包括: Markword、类型指针、数组长度(如果是数组的话)
我们平时说的是对象几乎都在堆上分配 ,因为还有可能栈上分配:热点代码触发 JIT,如果逃逸分析发现对象不会逃出当前方法和线程,就会触发栈上分配
标记-整理的算法怎么做?标记、整理、清除(肯定会暂停所有线程,因为整理的时候,对象的位置会发生变化)
CMS 做 GC 的时候: 初始标记、并发标记、重新标记、并发清除,其中初始标记和 重新标记都必须要在 safePoint 暂停所有的用户线程。
堆的空间大小是动态变化的,根据需要有时候大有时候小,不过一般建议最大堆大小和最小堆大小设置为同一个值,避免变化。一般来说,年轻代占堆空间的1/3 ,老年代占 2/3,这样老年代才能提供所需要的担保分配
CMS 有预清理操作,包括 2 部分:1)并发标记的时候,如果Eden区的 A 与 老年代的B (但是 B 与老年代的 GC Root 没有路径,在老年代会被视为 垃圾)有关联,则会将 B 设置为 GC Root。 2)并发标记阶段,如果老年代内部引用发生变化(可达变为不可达了),会建立一个表结构记录他们,重新标记的时候就不考虑这个表里面的区域了。
cms 的缺陷:cpu 敏感、浮动垃圾(边清扫边产生垃圾)、碎片化(本质还是标记-清除)
增大年轻代是否可以提高 GC 效率?答案是可以的,原因如下:
GC 时间间隔会增大。比如以前是500ms 一次,现在为 1000ms
年轻代GC 效率高。避免大对象直接到老年代了,放在年轻代回收比老年代回收好
标记比复制的耗时要小。扫描时间变成了 2倍T1 ,但是复制的时候,应该没有 2倍T2
如果有跨代引用,但是目前只回收年轻代,如果避免全盘扫描的呢?因为如果出现年轻代引用老年代的情况,会有一个表结构记录这种情况
JVM 基于栈(通过虚拟机栈进行所有操作),Dalvik 基于寄存器(局部变量表和操作数栈合并成了虚拟的寄存器)。简单操作时,基于栈的数据移动次数比较多。
PathClassLoader 的父加载器是 BootClassLoader ,但是他的父类是 BaseDexClassLoader
PathClassLoader 里有 PathList ,PathList 里面有 dexElements 数组
热修复时 我们为什么不能修改系统的类,只能修改自己的类呢?因为系统类使用的是 BootClassLoader 加载的,而我们自己的类是使用 PathClassLoader 加载的。
序列化其实就是将数据结构转换为二进制的过程,在 Java 里面很容易和 String 混淆,其实 String也是一种特殊对象,当然也需要序列化
serialVersionUID 如果不指定它的值,先序列化,那么如果类里面增加了属性,反序列化的时候会报错;反之,如果指定了 serialVersionUID ,反序列化的时候会给新增属性一个默认值。
如果子类实现了 Serializable ,但是父类没有实现,那么父类成员都将会是默认值。
1 2 3 4 DataOutputStream out = new DataOutputStream( new BufferedOutputStream( new FileOutputStream( new File(file))));
其中 FileOutputStream 将 File 转为字节流;BufferedOutputStream 就是用来提升速度的;DataOutputStream 就是保持数据的格式(所以写到磁盘肯定是不需要的),在磁盘和网络传输都是字节流,在内存里面才有字符流。
加固思路有3种: 1)壳dex 和 源dex 2)代码虚拟化,写的代码运行在自己写的虚拟机上,核心代码是以压缩或者加密形式存在,一段一段的 3) 反模拟器
从 Thread.java 类的注释来说,创建线程就 2 种方式,一是 扩展 Thread 类,二是实现 Runnable 接口。其中 Thread 是 Java 对线程的抽象,而 Runnable 是对任务的抽象
线程上下文切换是很耗时的,一般在 2W 个 CPU级别,所以线程不要太多。
如果 Integer 这种变量 i ,做 i ++ 操作是会创建新的对象的,所以需要注意使用 Integer 作为同步锁的时候的问题。
每个线程都有自己的 ThreadLocalMap ,map 里面用数组(tabl ,初始大小是 16,根据某种计算获取存储位置 index ,有冲突就重新计算,就是 index + 1操作,循环,直到取到为止)存放了所有 ThreadLocal 值。
ThreadLocal 不及时 remove 可能会内存泄漏,因为当 ThreadLocal 不再使用时,以它作为 key (WeakReference)的地方就没有 key 了,这样就没法寻址到这个 key ,但是 value 还存在,所以要及时 remove 。(当然,set 或者 get 的时候会做一下扫描操作,判断key 为空的 Entry 然后移除掉)
wait /notify 范式中为什么需要while 循环去判断条件是否满足,这是因为 notifyAll 会唤醒多个线程,多个线程之间只会有一个线程获取到资源,其他的线程再去获取条件可能就不满足了,所以需要 while 。
停止线程为什么用 interrupt 方法去做呢?因为假如你使用volatile 变量 isCancel ,如果是在 sleep 的过程,那么实际上不会判断 isCancel 变量的,但是 interrupt 会有中断产生。
在守护线程的run 方法中 ,finally 不一定保证执行,这是因为如果守护线程关闭的时候,整个进程都要结束了,无需考虑资源释放。
AQS 对 CLH 队列的改进:链表改为双向链表、控制自旋次数,超过次数就挂起。公平锁在获取锁的时候需要判断前面是否还有线程在等待锁。
CAS 存在的问题:自旋 cpu 消耗、ABA、只能简单变量
偏向锁和轻量级锁的对象头是完全不一样的,所以在撤销偏向锁改为轻量级锁的时候,需要替换 markword 。但是撤销偏向锁的时候,会有 Stop The World,因为 MarkWord 会粗放到线程的堆栈里面了,抢锁线程会跨线程把当前持有锁的线程的堆栈数据改过来。
Gson 是基于事件驱动的解析方式,它可以不要求一次性将数据全部加入内存。它的原理是,碰到左括号就压栈,等到右括号就取出来解析成对象。
如果是自己公司想写 APM ,可以参考 Matrix 和 Koom 。自己做 AMP 肯定是有配置的,使用 JSON 的样式下发过去。
[(n - 1) & (hash = hash(key)) 在 n 是 2 的幂的时候,可以用来对 hash 做求余操作
如果需要证明某个操作比之前的操作性能更高,可以采用运行很多很多次,或者数据装载很多的方式
如果想要一个 Service 长期运行,应该将其运行在单独的进程中,UI进程与Service 进程分离,就能获得比较小的 oom_adj 值,就比较难回收。
Native 的内存泄漏怎么分析?Koom 使用爱奇艺的 xHook 去做 Hook 操作,能监听内存分配等;Google 官方提供了 libmemunreachable 库来分析不可达的内存。
我们 Dump 内存的时候,会暂时挂起所有的线程,这时候会非常卡(如: LeakCanary),那要怎么解决这个问题呢?使用子线程可以不?肯定不行,因为这时候挂起了所有线程的,解决方案: fork 进程在子进程中去 dump 内存快照。
App 启动三个阶段:点击Launcher 通过 AMS 启动应用、Application 启动、MainActivity 启动。其中第一个阶段在 Framework 层,我们没法做什么,第二个阶段我们能做 Application 优化,以及 Application 到 MainActivity 白屏处理
用户点击 Launcher 到 第一个 Activity 出来,显示的是啥?其实是Application 的 theme。但只有 Window 才能被展示出来,所以这个 Window 是系统给创建的一个 SplashWindow ,在startActivity 之后, Activity 的 Window 真正展示之前,就是它在展示。以前我们说可以给系统 theme 设置 background ,但是background只能展示图片,如果设置成 windowSplashscreenContent (Android 26,也就是 8.0才支持)属性还能有动画
Activity 怎么优化?可以用 new View ,而不用 xml ,因为 xml 解析费事,并且反射创建 View 也很耗时。然后如果 Activity 比较复杂,也需要使用类似 Alpha 的启动框架,区分先后以及区分线程。
GC 会 STW ,所以,理论上我们可以在 IdelHandler 中做 GC 操作就不会影响到我们的主线程
我们一般使用 windowFocusChange 来标记一个新的 Window 启动。
总结下冷启动优化:
黑白屏阶段,使用 WindowSplashScreenContent 属性
Application 利用有向无环图优化任务
Activity 阶段,create 、start、resume 都不要执行耗时任务,因为onResume 之后才会vm.addView展示 Activity 的 Window
CountDownLatch 如果在初始化的时候,传入 0 这个数字将不会被阻塞
启动任务,需要区分主线程和子线程,如果主线程任务在前面,就可能失去并发的意义,因为主线程的一直在执行,阻塞子线程的任务被dispatch
SplashActivity 在什么时候没用呢?我们可以在其 onStop 的时候 finish 掉,因为这时候肯定MainActivity 已经 onResume 了,启动成功了。不能在 onPause,因为如果 MainActivity 启动崩溃了,此时 SplashActivity 也没有了
我们说调用 GC 需要 2 次(包括 LeakCanary),这是为什么呢?这是因为在 5.0 之后,第一次 GC 基本上只是设置一个标记位,第二次 GC 才会执行。所以间隔 500ms 的时候再次调用。
我们监测启动时间,可以(用 systrace)在 Application 的 onCreate 中去start ,在 Activity 的 onWindowFocusChanged 第一次调用的时候(说明 Window 刚从 SplashWindow 切换到 MainActivity 的 Window)停止
TCP/IP 四层模型: 应-传-网-数。 OSI七层: 应表会传网数物
DNS 主要使用 UDP 协议,有时候也使用 TCP
如果设计QQ 的网络协议: 登录采用 TCP和 Http ,利用 TCP 来保持在线状态;朋友间发送消息采用 UDP,在应用层保证可靠传输,如果发送失败,就提示用户重新发送;内网传输文件采用 P2P 技术。
是不是每次都选择 epoll 才是最好的呢?不是,在连接少,用户都活跃的情况,select 和 poll 可能效率更高
如果你选择堆上的 Buffer ,那么在发送的时候,还会在直接内存上创建一个 Buffer ,这样一来,首先需要将数据拷贝到堆上的buffer(因为堆上有GC机制,在 Socket 过程中,数据是不能变化的,如果在中途堆上的 Buffer 被GC 了那就麻烦,直接内存buffer不会GC),之后拷贝到 直接内存上的 Buffer ,所以应该用直接内存的 Buffer 。
零拷贝的几种方案:mmap、FileChannel
Okhttp 通过 client 的 newCall 方法得到一个 RealCall 对象来,然后可以 dispatch。 Dispatchers 里面维护了 3 个队列:准备执行的异步、正在执行的异步、正在执行的同步
异步 Call 在 enqueue 的时候,会判断队列里面(准备和正在)有没有 call 和自己的host 是一样的,如果是一样的,那就将自己的 callsPerHost 的属性替换成队列中 Call 的 callsPerHost 属性(用同一个AtomicInteger方便计数不超过 5个)
异步总连接不能超过64个,然后 同一个 host 的请求不能超过5个。
Okhttp 的线程池(和Executors.newCachedThreadPool一样):corePoolSize: 0 ;60s 超时,SynchronousQueue (其本身是没有容量的,比如我放一个元素到队列中去,不能立马返回,必须要有人消费了才能返回)无存储空间的同步队列,来一个任务就能马上执行
拦截器的添加顺序: addInterceptor 添加的、重试(重试重定向)、桥接(添加请求头、UA、GZIP压缩等行为)、缓存、连接(从连接池寻找,没有就创建)、addNetWorkInterceptor添加的(非 WebSocket才有用)、CallService 拦截器(真正请求)
所以,addInterceptor 和 addNetWorkInterceptor 的区别:拦截器队列中的位置不同,然后,打印日志的话,如果是在 addInterceptor 就是原始请求,addNetWorkInterceptor 中就还已经添加了自动补全的一些内容(请求头之类的)
Okhttp 的分发器是如何工作的?对于同步请求,只是记录一下;对于异步任务,首先添加到 ready 队列中,然后检查所有请求数小于64,以及同 host 请求数小于 5 是否满足,满足执行并添加到 running 队列中
重试 Interceptor 会判断 路线异常(Socket链接失败等)和 IO 异常,在这种异常里面判断是否要重试(重试的条件很苛刻,比如最后还要判断是否还有更多路线,即有多个ip),在异常里面如果不需要重试就直接抛出异常
Okhttp 如果是发送个比较大的文件,是需要与服务端协商的:如果服务器允许则返回 100 ,则客户端继续发送请求体;如果服务器不允许就直接返回给用户;如果服务器忽略这个问询的请求头,一直无法读取应答,此时会抛出超时异常
Glide 版本 4.1.1,Glide 会根据ImageView 设置的 ScaleType 来生成 ScaleType 对象
Glide 加载图片三部曲: with、load、into,只有在主线程,并且传入的是 Activity/Fragment 时,才会创建空白Fragment 来监听生命周期;否则,在子线程或者传入 Application 都不会监听声明周期
Glide 巧妙的一点就是如何保证一个 Activity 只有一个 Fragment ,这里面用到了 Handler 机制:先findFragmentByTag 查找,如果空,就从map 中查找(以 fragmentManager 为key),还是没有才创建,创建后马上加入到 map 中(以 fragmentManager 为key),正是因为 commit 的方式将 fragment 添加的时候是通过 Handler 的 msg 的,不一定实时
Glide 有活动缓存(ActiveResources) 和 LRU 缓存,他们都在内存里面,图片只能在这二者里面存在一份。。那为什么要在内存中设置2级缓存?Glide 将正在显示的图片都放在活动缓存,防止被回收;获取图片时,先从活动缓存找,没有就从LRU缓存找,找到了就复制到活动缓存,再把LRU 中的删除掉。当前页面关掉之后,又讲图片从活动缓存里面放回 LRU
Glide 还有一级 DiskCache 缓存,所以总共三级缓存,内存中的缓存都没有的时候,如果 Disk 中有的话,会直接放到活动缓存中。如果不得不网络请求获取,在获取成功后,Disk 中保存一份,然后给活动缓存也提供一份供马上使用。监听到 onDestroy 的时候,将活动缓存的移入LRU 缓存中
Glide 最终通过 UrlConnection 去请求图片的,有两个队列:等待队列和运行队列
LRUCache 的实现中,默认每个元素的大小就是 1,需要重写方法表明实际的大小
图片 url 需要经过处理才能作为key ,因为比如Disk 里面,名称包含斜杠冒号等就会报错的
注解2个用法:apt 技术生成代码、注解+反射运行时操作
gradle 中执行的步骤: settings.gradle、project 级别的 build.gradle、壳工程的 build.gradle、library中的 build.gradle
我们可以定一个公共的 gradle ,将各个 module 中相同部分放进去即可,然后在 module 中 apply from ‘publicdd.gradle’ 引入进来,在使用的时候建议用成员变量,可以提高效率: def ext = rootProject.ext
组件化要做到:正式环境和测试环境部署、测试环境各个module 独立打包和运行,正式运行必须要依赖App 壳。其中的区别就是apply 的时候是 application 还是 library,然后就是 独立运行时需要 appId
代码生成可以自己完全复制文本进去,但是如果手抖之类的少写标点符号之类的,容易崩溃,如果想要更准确可以选择 JavaPoet
理解 ARouter ,主要理解 ARouterGroup 和 ARouterPath 两个类,前者里面有 getGroupMap() 方法,后者有 getPathMap() 方法。这里面肯定 Path 类先生成。
插件化:侧重动态化加载某些功能,主要问题是兼容性问题,支付宝都放弃了
反射耗时:临时对象导致GC、字节码没有优化、参数非固定长度用数组承载、自动拆装箱
loadClass 和 forName 的区别:前者只会做类加载,后者会做加载、验证、准备、解析、初始化
DexClassLoader 和 PathClassLoader 没啥区别,只是 8.0 以前 DexClassLoader 需要多传入一个 odex 存放的路径。其实最后都是通过 DexPathList 的findClass 去加载类
Android 10 的 AMS 变成了 ATMS ,所以需要适配下,但是 Handler 源码没变,所以不需要适配。AssetManager 需要反射创建新的对象
资源问题,在 BaseActivity 中创建自定义的 AssetManager 时,要传入 Application 的 Context ,如果还传入当前 Activity ,就会陷入死循环。自定义的 AssetManager 加载宿主和插件的资源,然后再 BaseActivity 里面做如下操作就行:
1 2 3 4 5 6 @Override public Resources getResources () Resources resources = LoadUtil.getResources(getApplication()); return resources == null ? super .getResources() : resources; }
插件化,建议将宿主的 dex 放在前面,不然如果插件 dex 有问题,宿主也被带崩了
热修复 Robust 定义了一个接口,在每个方法前面都插入了一个判断,判断接口是否为空,不空就判断当前方法是否可以用 接口完成,如果可以,那原有逻辑就不执行,转而执行接口的这个逻辑。(通过反射的方式将补丁的实例赋值给类的那个接口对象)
Handler 的 Messager 其实就是一块内存,从子线程可以到主线程来执行,从而实现线程切换。
一个线程只有一个 MessageQueue,然后Msg 的添加(enqueue)和获取(next)是要 synchronized 同步的,为什么取的时候也要加锁?因为取的时候可能有 msg 正在加入。
避免内存抖动一个解决方案是池化技术
所有的线程都公用一个 ThreadLocal 对象用来存 Looper,因为这个 ThreadLocal 是static final 的,所以我们可以说 key 是相同的,但是它们的 value ,也就是 Looper 是不同的。根本原因还在于每个线程都有自己的 ThreadLocalMap 。
Proxy 是给客户端使用的,Stub 服务端使用。asInterface 判断如果是跨进程,
Binder 是一个驱动,通过 mmap 创建的空间大小就是 1M - 8k (1M - 2 * pageSize),如果是异步的话,还要除 2 : (1M - 8k)/2
linux 中一切皆文件,输入输出也是,在代码中写 system.out.println() 也是将内容写入到某个目录
进程是没有 Java进程 和 Native进程 的区分的,所以,zygote 执行的时候,不论是在 Native 层还是 Java 层,我们都说是在 Zygote 进程
fork 行为是这样的:复制整个数据,然后仅仅复制当前线程 到子进程,所以可能死锁
那么一个进程可以有多个 App 吗? 答案当然也是可以!我们可以用 sharedId 去实现 。
在哪里对 Activity 的栈进行管理? 答案是在 ActivityStarter 这个类,在这里还会计算 Activity 的启动模式
FLAG_ACTIVITY_FORWARD_RESULT 的作用是当前 Activity 忽略 ActivityResult ,这样就会将结果传给上一级,使用它的时候只能startActivity 不能 forResult
statusBar 和 searchBar 等也都是 System Window
WindowManagerGlobal 创建和管理所有的 ViewRootImpl
TextView 连续 2 次setTextView ,那么会触发几次重绘?每16ms 间隔才会刷新一次,所以连续的 setTextView 只会有一次重绘。
如果 MessageQueue 中的 其他 Msg 太多,导致老是执行不到同步屏障那个 Msg ,同样会引起卡顿,所以主线程不要做太多的耗时操作。
四大组件管理者以前说的都是 AMS ,但是 ANdroid 10 之后,这么说就不准确的,新增了一个 ATMS (ActivityTaskManagerService), 其中 ATMS 专门管理 Activity , AMS 管理其他三个以及其他的。
Activity 的情况:setContentView 会调用到 getWindow.setContentView,在里面会 installDecorView 从而 new 出一个 DecorView。为什么在 setContentView 之后调用 requestWindowFeature 会报错?那是因为在 setContentView 里面会 generateLayout 根据各种 flag 来选择相应的 layoutResource ,所以,更改 flag 应该在其之前(源码是通过一个boolean 类型的标志位实现)。
AppcompatActivity 的情况:将 Activity 的 windowContentId 设置给自己的 subDecorView ,然后将原来 Activity 的 windowContentView 的 id 设置为 NO_ID,实现了DecorView 的替换
解析xml 的时候,会根据name 是否带有点(.) 来判断是否是SDK 自带组件,没有点就是自带组件,自带组件会自动补全全名,并且会根据全名使用 forName 获取Class 对象,之后 newInstance 创建出来(调用的是2个参数的那个)。反射创建出来的 constructor 会保存起来,下次直接反射就行。
创建 View 的时候,如果有 mFactory2 ,则优先使用它来 createView,所以我们可以基于这个去做换肤。(基于这个原理,如果我们继承了 AppCompatActivity ,然后在布局文件中写了个 TextView 然后通过 findViewById 去获取的时候,可以打印一下这个 tv ,发现它不是个 TextView,而是 AppcompatTextView!)
我们的 view 只需要一直往上递归 getParent ,最后肯定会到最顶部的 ViewRootImpl (DecorView 的 parent 是 ViewRootImpl)
我们有个输入框,当点击弹出输入法的时候,这个输入框可能会移动,这是怎么做到的呢?其实就是在 draw() 方法里面执行的 scrollxxx 某个方法实现的。
一般 ViewGroup 的 onDraw 是不执行的,如果我想让 ViewGroup 的 onDraw 方法执行: 1)设置背景 2)setWillNotDraw 为 false
皮肤包资源替换:在替换的时候,我们先拿到app 中这个资源的id ,再通过 id 获取其名字,再从 皮肤包中通过名字找到这个 皮肤资源的 id ,这样就能替换了。所以如果没有名字,都是直接的资源(如 #ff0000)就不能换肤
攻玉 有一个Button有ABC三种样式,然后屏蔽View的其他方法怎么做(三种方法:1. 编译时发现访问了View方法报错 2. 继承并且复写方法为空实现,内部提供super访问方法 3.面向对象思想 返回一个只有ABC三个方法的接口)
websocket
命令dumpsys meminfo中VSS、PSS、GSS、USS代表什么意思
Android绘制三部曲、Canvas是怎么最终显示在屏幕中的、是以什么样子的数据结构传输的
Android Heap的结构是怎么样的
ActivityTask的使用
启动Activity A后,按home键,再从桌面启动activity A , Activity A的生命周期?
如何实现一个拥有取出最小值方法的堆栈,要求算法的事件复杂度是O(E)如何算
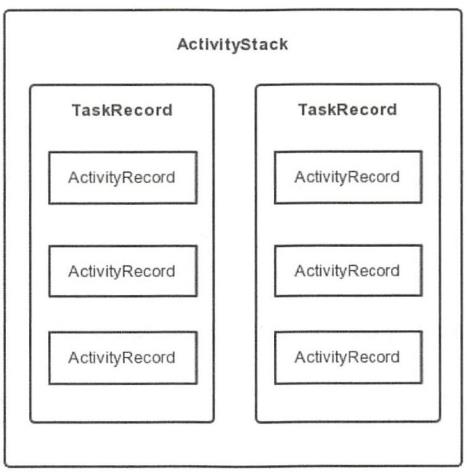
TaskRecord、ActivityRecord、ActivityStack
在kotlin中各个部分的执行顺序:companion > init > constructor
常见对称加密算法: AES,DES,3DES,RC4
注意postInvalidate的使用
项目中遇到的 ANR 有哪些? 怎么排查的?
为什么要重构网络框架?重构后有什么亮点?
OkHttp这些 interceptor 执行的顺序是什么?能否换位置?
kotlin的 lazy 是怎么实现的
开发者模式中,GPUInfo 中柱状图颜色代表的含义;命令dumpsys meminfo中VSS、PSS、GSS、USS代表什么意思
Android绘制三部曲、Canvas是怎么最终显示在屏幕中的、是以什么样子的数据结构传输的
binder如何根据文件描述符找到对应的binder实体
最有挑战的项目?你负责做了什么?给公司带来什么价值?
Kotlin 的协程是通过变异生成的状态机实现的,并不需要栈,所以是无栈协程。
notify 之后会立刻释放锁么?答案是不会,还得等同步代码块执行完。
A跳转到B的生命周期调用,如果A的onStop方法方法发生在B的onResume方法之前会发生什么现象,
httpdns 的设计
做sdk的话,如何在接入的时候管理第三方依赖
Okhttp 多个host,如何配置
插件话第三方开源框架
Apk的签名原理,v1和v2
什么情况下本地方法栈会引用Java对象
异步创建view的原理
contentprovider 用于跨进程的数据传递,比如500 的广告方案,ContentProvider 传递数据的原理
扫码登录是怎么做到的
onTouchListener 和 onLongClick 哪个先执行?
ashmem 有哪些作用?
优化 App 的步骤!发现问题,解决问题,形成标准
dalvik 和 art 的 gc 过程有了解吗
网络成功率怎么优化
可以给子线程创建消息队列吗?消息队列 Native 层源码知道吗?
React Native了解它的实现原理吗?除了组件映射,还有更深的理解吗?
SurfaceTexture,TextureView区别
类中还有其他静态方法或变量时,饿汉模式才有优势,此时可以通过访问任一静态成员来实例化对象
sharedpreference 的 apply什么时候同步到磁盘上去
我拿了别人的库,别人会校验签名,如果我想用这个库,怎么弄?
GlobalScop 有什么不好的点吗?
lateinit 只用于变量var ,而 layzy 只用于常量val
那你获取证书这部分我是不是可以中间人攻击,你们发的是tcp包还是http包?http包那你们也还是会有明文,就会有漏洞。
MMKV 是如何解决跨进程问题?为什么SP跨进程是不好的?
内存泄漏经常会OOM,这种OOM怎么在线上怎么监控?
视频播放:视频有做过加密吗?视频地址是固定的吗?
kotlin的作用域函数apply、also等,怎么确定什么时候用什么?
如何监控启动就crash的问题? Debug.waitxxx 断点调试吧
OOM类型的问题如何解决
内存泄漏如何线上监控
Android so如何减包
JNI的attachCurrentThread作用是什么
在https建立后,使用对称加密之后,如何验证双方的身份?
红黑树:最通俗易懂入门红黑树(R-B Tree)-腾讯云开发者社区-腾讯云 (tencent.com)
从Java中TreeMap集合来引出外部比较器和内部比较器的一些用法_treemap比较器_LL的小小卖部的博客-CSDN博客
有看过哪些安卓的源码
Activity启动
handler
ThreadHandler
IntentThread
ViewStub 可以源码熟悉
LeakCanary
Alpha
okhttp
注解替代枚举类也能减轻内存压力
重载和重写的区别 方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载是一类中多态性的一种表现。
override(重写):
1、方法名、参数、返回值相同。
2、子类方法不能缩小父类方法的访问权限。
?3、子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常)。
4、存在于父类和子类之间。
5、方法被定义为final不能被重写。
overload(重载):
1、参数类型、个数、顺序至少有一个不相同。?
2、不能重载只有返回值不同的方法名。
3、存在于父类和子类、同类中。
TCP 三次握手和四次挥手 java中的this编译时的原理 我们知道,this关键字主要有三个用途:
调用本类中的属性
调用本类中的其他方法
调用本类中的其他构造函数
this编译时的原理:
this指代的一定是对象(所以静态方法不能使用this),且该对象的静态类型就是就是当前类
实例方法以及 构造方法 的第一个参数都是this(在构造方法之前,jvm其实已经给对象在堆中分配好了内存了,构造方法的作用是对类初始化 )
this一般出现在方法中;如果this出现在方法体外部,如:在类A中定义了成员变量 A a = this;最终这行代码仍然会被放入 A 类的构造函数中执行 。
touchdelagate 一个父view只能设置一个delegate,如何解决设置多个
android app签名原理
Fragment View区别
onSaveInstanceState onSaveInstanceState 调用顺序:对于版本较低的系统,这个方法将在onStop之前调用,无法保证与onPause的先后调用顺序。
不要把这个方法与activity生命周期中的一些方法混淆了,onPause()会在acitivity且后台的时候被调用。什么时候onPause和onStop会调用,但是onSaveInstanceState不会调用呢?举个例子,当从Activity B回到Activity A后,由于B的状态不需要保存了,所以系统就不会调用onSaveInstanceState方法了。什么时候onPause会调用但是onSaveInstanceState不会调用呢?当Activity A上打开了Activity B后,如果A在B的生命周期内不会被销毁,那么A就不会调用onSaveInstanceState方法,A的用户交互信息仍将保持完整性。
讲讲Android存在的设计模式:
Context 的装饰器模式
AlertDialog 使用了建造者模式
BitmapFactory 的工厂模式
View 的layout、measure、draw 就是 责任链模式
aidl 代理模式
ListView、Gridview 等 使用的适配器模式
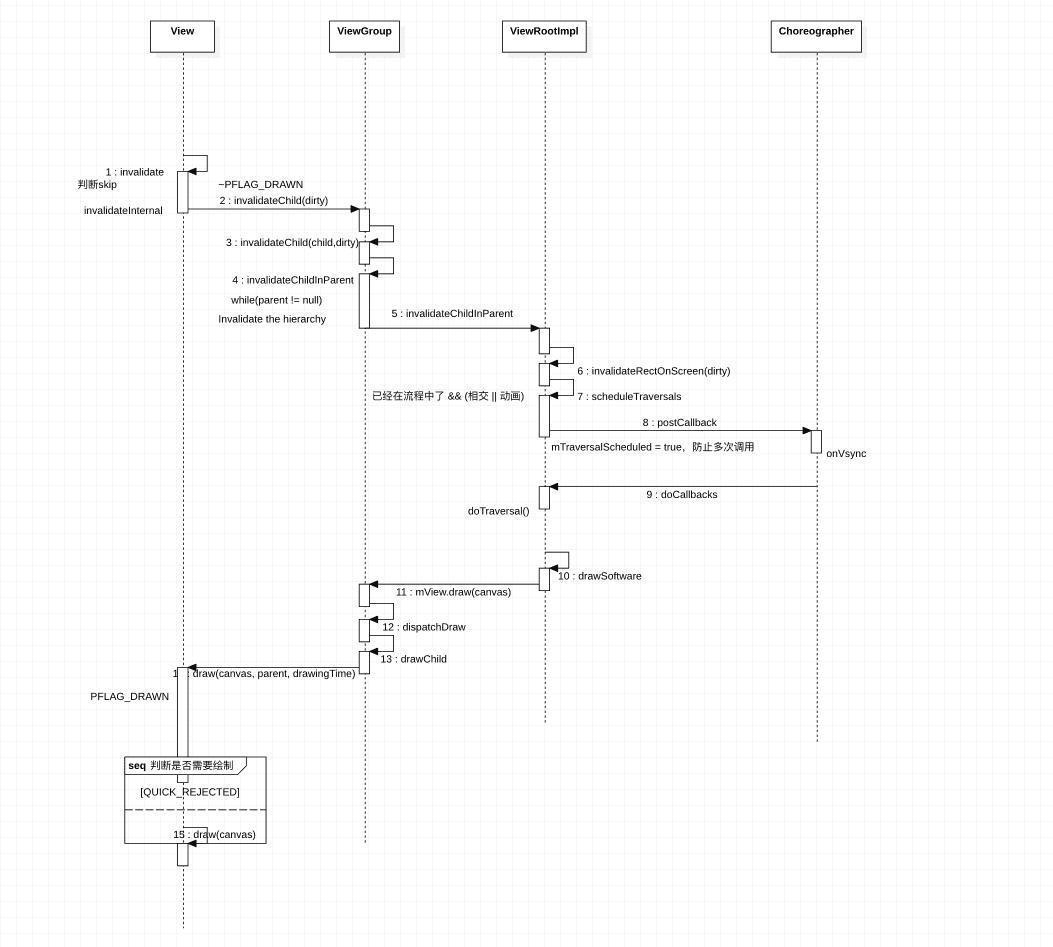
View怎么展示?Android 上屏原理 - 简书 (jianshu.com)
(12条消息) Java实现多个线程一起并发执行_怎样同时并发20个线程_后端小王的博客-CSDN博客
View 绘制流程 : (12条消息) Android-举一反三:12个View绘制流程高频面试题,带你全面理解View的绘制流程_android view绘制面试_沈页的博客-CSDN博客