TCP连接
HTTP的连接实际上就是TCP的连接和一些使用连接的规则。
TCP是可靠的数据管道:TCP为HTTP提供了一条可靠的比特传输管道,从TCP连接一端输入的字节会从另一端以原有顺序、正确地传送出来。
TCP流是分段的,由IP分组传送:HTTP以流的形式将报文数据通过一条打开的TCP连接传输,TCP会将数据流分成若干段,每个TCP段都是由IP分组承载,从一个IP地址发送到另一个IP地址。
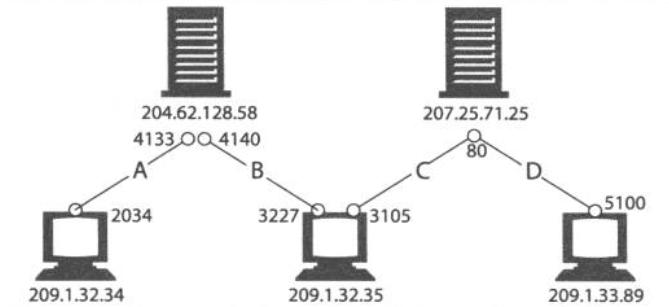
任意时刻计算机都可以有多条TCP连接处于打开状态,TCP是通过端口号来保持这些连接的正确运行。
TCP的连接是通过4个值来识别的:<源IP地址、源端口号、目的IP地址、目的端口号> ,这4个值定义了唯一一条连接,IP地址可以将你连接到正确地计算机,而端口号可以将你连接到正确的应用程序。
以下表示四条不同的TCP连接,各连接要么源IP不同,要么目的IP不同,要么源端口不同,要么目的端口不同:
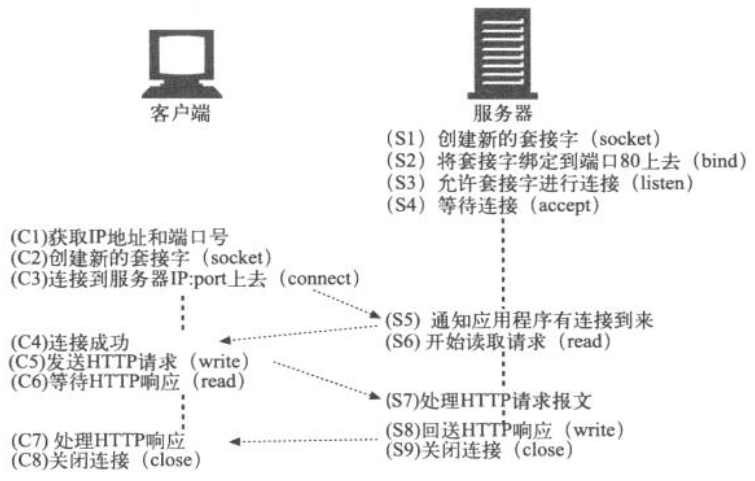
利用套接字操纵TCP客户端和服务器之间的连接:
HTTP性能讨论
性能概述
HTTP事务流程主要包括几个方面:
- 客户端首先根据URI确定WEB服务器的IP和端口,如果没有DNS缓存的话,这个过程可能花费数十秒。
- 接下来,客户端向服务器发送TCP连接请求,并等待服务器应答,每条新的TCP连接都会有连接建立时延。
- 一旦连接建立起来,服务器处理请求、因特网传输请求报文都需要时间。
HTTP位于TCP上层,所以HTTP事务的性能很大程度上取决于TCP通道的性能。这其中,对HTTP性能影响最常见的是TCP相关的时延,包括:
TCP连接建立握手
小的HTTP事务可能会在TCP建立上花费50%的时间,这是不合理的。
用于捎带确认的TCP延迟确认算法
每个TCP段都有一个序列号和数据完整性校验和,每个段的接收者收到完好的段时,都会向发送者回送确认分组。如果发送者没有在指定的时间窗口收到确认信息,发送者就认为分组已损坏,并重新发送数据。由于确认报文很小,所以TCP允许TCP将返回的确认信息与输出的数据分组结合在一起,可以更有效地利用网络。为了增加确认报文找到输出数据分组的可能性,很多TCP栈都实现了一种“延迟确认”算法,延迟确认算法会在一个特定的窗口时间(通常100~200毫秒)内将输出确认存放在缓冲区中,以寻找能够捎带它的输出数据分组,如果那个时间段内没有输出数据分组,就将确认信息放在单独的分组中传送。
TCP慢启动拥塞(se)控制
TCP数据传输的性能还取决于TCP连接的使用期(age)。TCP连接会随着时间进行自我“调谐”——期初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输速度,这种“调谐”称为 TCP慢启动,用于防止因特网的突然过载和拥塞。例如,如果HTTP事务有大量的数据要发送,是不能一次将所有分组发送出去的,必须发送一个分组等待确认,然后可以发送两个分组,每个分组都必须确认,这样就可以发送四个分组了,这种方式被称为“打开拥塞窗口”。由于存在这种拥塞控制,所以新连接的传输速度会比已经传输过一定量数据的“已调谐”的连接慢一些。由于已“调谐”的连接快,因此HTTP中有一些可以重用现存连接的工具,提高效率。
数据聚集的Nagle算法与TCP_NODELAY
如果每次发送的数据量很少,但是传输的次数很多,就会产生大量包含少量数据的分组,网络性能就会下降,Nagle算法鼓励发送全尺寸(LAN上最大尺寸的分组大约1500字节,因特网上是几百字节)的段,试图在发送一个分组前,将大量TCP数据绑在一起,提高网络效率,毕竟每个TCP段中哪怕只放了一个字节,也至少装载了40个字节的标记和首部。但是这也会引发HTTP性能问题,首先,可能某个小的HTTP报文无法填满一个分组,但等待那些永远不会到来的额外数据而产生时延。其次,Nagle算法与前面体积的延迟确认似乎是矛盾的 —— Nagle算法会阻止数据发送,直到有确认分组抵达为止,但是确认分组会被延迟确认算法延迟100~200毫秒。
TIME_WAIT时延和端口耗尽
当某个TCP端点关闭TCP连接时,会在内存中维护一个小的控制块,用来记录最近所关闭连接的IP地址和端口号,这类信息指挥维持一小段时间,通常是所估计的最大分段使用期的2倍(称为2MSL,通常为2分钟)。
HTTP的性能改善
有几种方法可以提高HTTP的性能:
- 并行连接,通过发起多条TCP连接发起并发的HTTP请求。这样可以避免单条连接的空载时间和没有充分利用带宽。以下两个图为对比:
串行: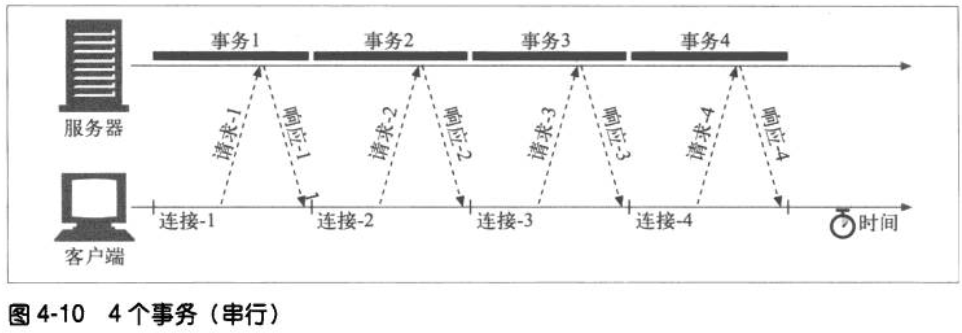
并行: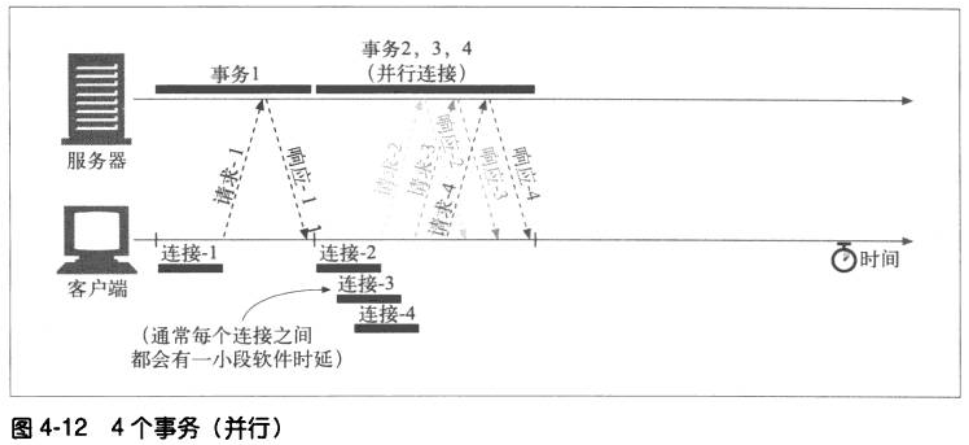
2. 持久连接,用于消除连接及关闭的时延。 以前使用 keep-alive 字段,现在使用 persistent。
3. 管道化连接。通常,http请求总是顺序发送的,下一个请求只有在当前请求的响应被完全接受的时候才会被发送。由于网络延迟和带宽的限制,这样会导致在服务器发送下一个响应的时候中间有很大的延迟。管道化连接可以将多条连接放入队列,当第一条请求发出之后,第二条第三条请求也可以开始发送了,这样做可以降低网络环回时间,提高性能。
如果一个事务,不管是执行一次还是很多次,得到的结果都是相同的,那我们说这个事务是幂等的。 GET、HEAD PUT DELETE TRACE OPTIONS 是幂等的,但POST不是幂等的,所以不应该以管道化的方式发送POST请求。
书本之外:关于TIME_WAIT
以下内容参考自博客:
https://blog.csdn.net/u013616945/article/details/77510925
描述
首先调用close()发起主动关闭的一方,在发送最后一个ACK之后会进入time_wait的状态,也就说该发送方会保持2MSL时间之后才会回到初始状态。MSL值得是数据包在网络中的最大生存时间。产生这种结果使得这个TCP连接在2MSL连接等待期间,定义这个连接的四元组(客户端IP地址和端口,服务端IP地址和端口号)不能被使用。
产生的原因
- 为实现TCP全双工连接的可靠释放
假设发起主动关闭的一方(client)最后发送的ACK在网络中丢失,由于TCP协议的重传机制,执行被动关闭的一方(server)将会重发其FIN,在该FIN到达client之前,client必须维护这条连接状态,也就说这条TCP连接所对应的资源(client方的local_ip,local_port)不能被立即释放或重新分配,直到另一方重发的FIN达到之后,client重发ACK后,经过2MSL时间周期没有再收到另一方的FIN之后,该TCP连接才能恢复初始的CLOSED状态。如果主动关闭一方不维护这样一个TIME_WAIT状态,那么当被动关闭一方重发的FIN到达时,主动关闭一方的TCP传输层会用RST包响应对方,这会被对方认为是有错误发生,然而这事实上只是正常的关闭连接过程,并非异常。
- 为使旧的数据包在网络因过期而消失
为说明这个问题,我们先假设TCP协议中不存在TIME_WAIT状态的限制,再假设当前有一条TCP连接:(local_ip, local_port, remote_ip,remote_port),因某些原因,我们先关闭,接着很快以相同的四元组建立一条新连接。本文前面介绍过,TCP连接由四元组唯一标识,因此,在我们假设的情况中,TCP协议栈是无法区分前后两条TCP连接的不同的,在它看来,这根本就是同一条连接,中间先释放再建立的过程对其来说是“感知”不到的。这样就可能发生这样的情况:前一条TCP连接由local peer发送的数据到达remote peer后,会被该remot peer的TCP传输层当做当前TCP连接的正常数据接收并向上传递至应用层(而事实上,在我们假设的场景下,这些旧数据到达remote peer前,旧连接已断开且一条由相同四元组构成的新TCP连接已建立,因此,这些旧数据是不应该被向上传递至应用层的),从而引起数据错乱进而导致各种无法预知的诡异现象。作为一种可靠的传输协议,TCP必须在协议层面考虑并避免这种情况的发生,这正是TIME_WAIT状态存在的第2个原因。
time_wait状态如何避免
首先服务器可以设置SO_REUSEADDR套接字选项来通知内核,如果端口忙,但TCP连接位于TIME_WAIT状态时可以重用端口。在一个非常有用的场景就是,如果你的服务器程序停止后想立即重启,而新的套接字依旧希望使用同一端口,此时SO_REUSEADDR选项就可以避免TIME_WAIT状态。
