根据技术栈可能的提问
1、聊聊 java 中 static 关键字
点击看答案
一旦什么东西设置为 static ,数据或者方法就不会同那个类的任何对象实例有联系。例如以下类:
1 | class StaticTest{ |
尽管我们可以给StaticTest 类new 出 2个对象来,但是 StaticTest.i 仍然只有一个存储空间,即两个对象共享同样的i,此时,其中一个对象执行 ++i 后,另一个对象的 i值 也会变为 48。
静态的变量或者方法,可以通过对象引用,也可以直接通过类引用,如以上的i,可以使用如下两种方式引用:
假设st 是 StaticTest 类的对象: st.i = 4 或者 StaticTest.i = 4
2、Kotlin 相关
点击看答案
Kotlin 中的协程用过吗?聊聊?
简单使用过,但是仅仅用于线程切换,对协程有一些简单的了解:
- 协程是编译器级别的,进程和线程是操作系统级的
- 线程根据os的调度算法,当分配的时间片用完后,保存当前上下文,之后被强制挂起,开发者无法精确控制它们
- 协程可以看做是轻量级的用户态线程
- 协程实现的是非抢占式的调度,由当前协程控制什么时候切换到其他协程
- 每个协程池里都有一个调度器,这个调度器是被动调度的,即当前协程主动让出cpu时调度
- 目前的协程框架一般设计成 1:N 的模式,即一个线程作为容器,里面包含多个协程
优点
协程轻量,创建成本小,内存消耗小
协作式的用户态调度器,cpu上下文切换开销少
进程/线程 切换需要在内核完成,而协程通过用户态栈实现,速度更快,但协程也放弃了线程中优先级的概念
减少同步加锁,整体性能提高
协程基于事件循环,减少同步加锁的频率。但若存在竞争,该上锁的地方仍需要加上协程锁
可以按照同步思维写异步代码,即用同步的逻辑,写由协程调度的回调
协程可以减少callback 的使用,但是不能完全替代callback,基于事件驱动的变成用callback更合适
缺点:
- 协程中不能有阻塞操作,否则整个线程被阻塞(协程是语言级别,线程是操作系统级别)
- 需要特别关注全部变量、对象引用的使用
- 协程擅长处理IO密集型程序效率问题,但处理cpu密集型不是它的长处
假设线程中有个协程是cpu密集型,但是没有io操作,也就是一时半会不会主动触发调度器调度,从而其他协程得不到执行
适用场景:
- 高性能计算,牺牲公平性换区吞吐量;
- 在 IO 密集型程序中。由于io密集型的程序中往往需要 CPU 频繁切换线程,带来大量性能浪费。但是协程可以很好地解决这个问题:比如把一个IO操作写成一个协程,当触发IO操作时就自动让出cpu给其他协程,协程间的切换是很轻的。
- 流式计算。消除Callback Hell。
Kotlin 优势
按照官网上的说法:
- 简洁。语法简单,代码很少。判空、getter、setter 方法、命名传参(动态改变参数)无需重载,可能结合anko 之类的更加简单
- 安全,减少空指针等错误、类型判断过后,自动类型转换
- 兼容java,可以混编
缺点
- lateinit,也容易引起空指针,即还未初始化
- 直接使用 ArrayList 之类的list 是不能直接添加元素的,得使用 MutableList 才行
- 引入了kotlin 支持库,apk包体积增加
- 如果某个变量设置为可空的,那么即使你在初始化后,已经不空了,你也只能使用 ? 或者 !! 操作来使用它,感觉会有点乱
kotlin如何实现空安全
- 可空类型和不可空类型
- 使用 ? 进行安全调用
- 入参可以指定可空和非空类型
- 安全的类型转换,如 a as? Int
- 可以方便过滤非空元素,如: val intList: List
= nullableList.filterNotNull()
一定能避免空指针问题吗?我认为是不能,因为有 lateInit 变量存在,有可能这个变量还没初始化,就会导致是空的
3、有自定义view的经验,那如何理解 MeasureSpec?
点击看答案
MeasureSpec 的含义是:父View传递给当前 View 的一个建议值。MeasureSpec 是个int 类型的数字,转换成二进制后,前2位代表模式(mode),后30位代表数值(size)。模式总共分为3种:
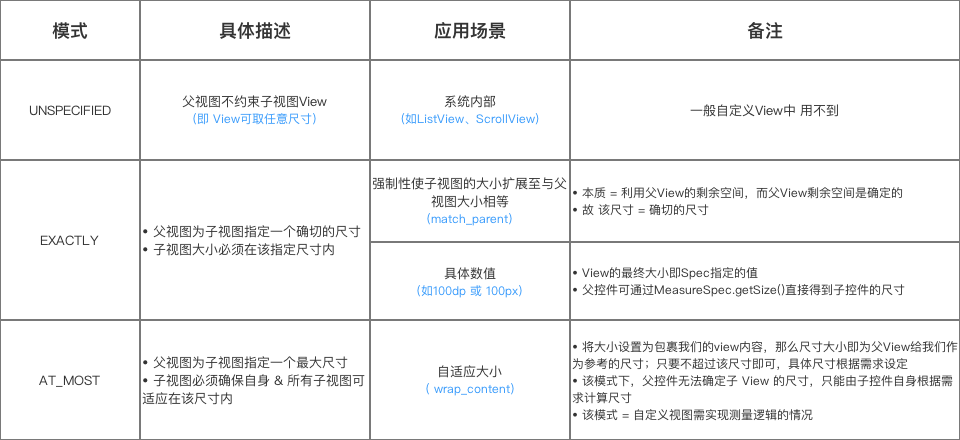
measureSpec & MODE_MASK 即可获得mode的值;而 measureSpec & ~MODE_MASK 即可获得数值。
那么,measureSpec 的值到底是如何计算得到的?view的 measureSpec 根据view 的布局参数(LayoutParams) 和 父容器的 MeasureSpec 值计算得到的,计算方法如下图所示:

由于UNSPECIFIED模式用于系统内部多次measure 的情况(如listview、gridview 等),很少用到自定义view上,因此我们很少讨论。以下总结的规律也不讨论:
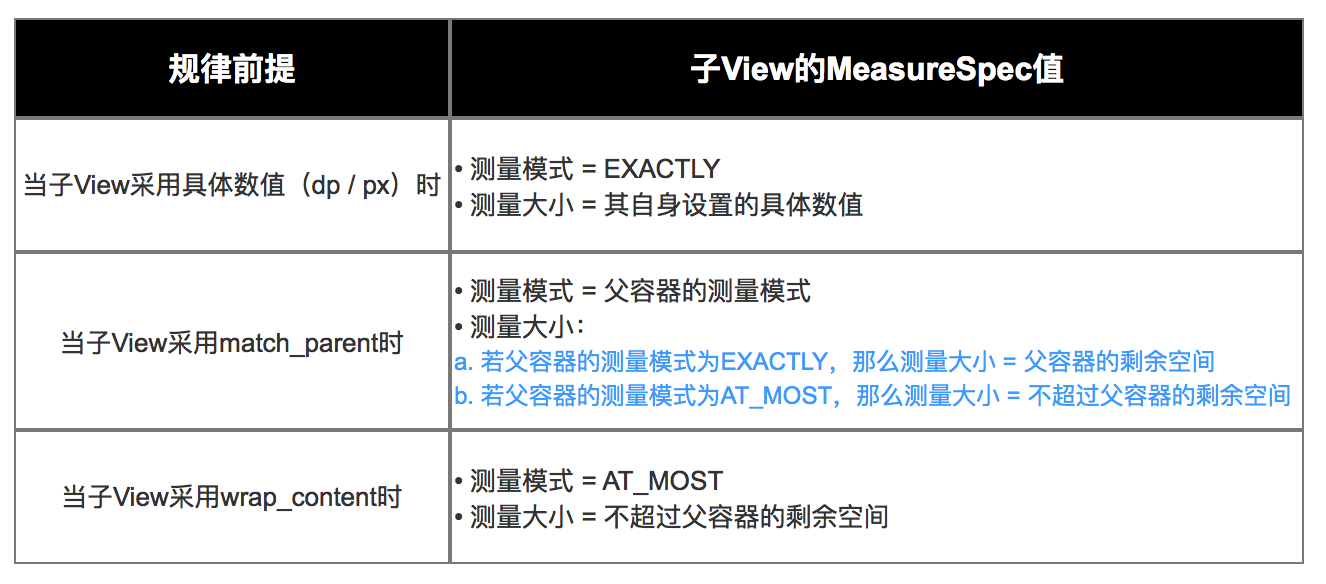
以上总结中,父容器的剩余空间指的是父容器除了padding之外的所剩余的空间,至于父容器的剩余空间与大小不超过父容器的剩余空间,看代码和看图都没能理解,后续再理解吧
以上内容部分参考自这个链接
4、聊聊 Android 中事件分发机制?
5、如何处理手势冲突?
点击看答案
有外部和内部两种方式处理手势冲突。
外部拦截:由上面的事件分配可知,点击事件都会经过父容器拦截处理,如果父容器需要此事件就拦截,否则此事件就不拦截,这样就可以解决事件冲突。外部拦截法需要重写父容器的onInterceptTouchEvent,比较符合事件分发机制。
这里要注意的是,还是上面的原则,在 onInterceptTouchEvent 中,首先是ACTION_DOWN 这个事件,父容器必须返回false,即不拦截,因为一旦拦截了 ACTION_DOWN ,后续的 ACTION_MOVE 和 ACTION_UP 都没法再传递给子view了; 接下来的内容辩证看待:ACTION_MOVE根据需要是否拦截;ACTION_UP 必须返回false,因为如果返回true,那么子view 是接受不到 ACTION_UP 事件,onClick 事件就无法响应。
内部拦截法:
可以利用view事件分发的原则,在适当的地方拦截就行。
当然,也可以让父空间不拦截,如果是ViewGroup的话,可以在 onInterceptTouchEvent 方法中请求忽略外层容器拦截事件:getParent().requestDisallowInterceptTouchEvent(true) 。如果是View的话,那么把getParent().requestDisallowInterceptTouchEvent(true) 写在setOnTouchListener 方法中可能更合适。
6、如何优化App性能?
点击看答案
一、精简资源
- lint检测,删除无用的资源
二、减轻Application的负担
- 将非紧急操作,放在子线程中处理
- 只在主进程中初始化app内容(因为接了百度地图等,会开启多个进程)
三、UI绘制优化
- 布局优化,尽量使用 ConstraintLayout 减少布局层次(因为深度遍历)
- 布局复用,比如底部的布局大体相似,都使用同一个 layout
- 避免过度绘制。排查移除叠加的背景
- 减少资源数目,因为shape很难复用,故shape换成 固定的控件: ShapedTextView、ShapedConstrainLayout 等
- 提高显示速度
使用 viewstub 延后显示。
四、内存相关优化
一言以蔽之: 开源节流
- webview 新进程
- 检查内存泄漏(LeakCanery)
- 正确地使用引用,尤其Activity的context(尽量替换成Application 的context,Activity 的Context 一律弱引用),以及强引用、弱引用、软引用的正确使用。
- 使用正确的容器,比如避免自动装箱(使用SparseArray等)、避免hashmap内存浪费(使用ArrayMap等)
- 枚举替换成注解。
五、cpu 相关优化
- 解析缓存数据一律放在子线程处理
- SharedPreference 存储json改动
- webview预加载
六、网络优化
- 域名替换成ip(选取响应速度最快的ip),避免劫持同时提升响应速度,webview 中的网络请求由网络框架接管。
七、结构
- mvp
八、避开高峰
- 不要同时,充分利用IdleHandler,快速滑动的时候不加载图片
具体优化方式:
1、内存从经常性的 380M 左右降低到 330M 的水平(adb shell dumpsys com.esun.ui,现在可以使用profile)
2、页面秒开(talkingdata数据显示,优化前88%左右,93%的收集数据显示1秒以内打开,从onCreate 到onResume)
3、过度绘制(优化前几乎所有主要页面都是红色-蓝、绿、粉、红 分别代表过度绘制 1,2,3,4 次,优化后基本上都是蓝绿,粉色的比较少,红色的可能只有极少数小块)
4、App启动速度加快,冷启动,从3.5秒左右降低到1秒左右(录屏,记录从启动到展示flash页面,多次时间取平均值)
5、网络连接,网络的错误率4%(按次数统计出的)左右,dns加速后,网络错误率基本上保持,主要集中在网络超时、网络无连接两种异常,其中网络超时占了40%左右
引申-adb shell dumpsys meminfo com.esun.ui 中各数据含义
点击看答案
Native Heap: Native对象malloc得到的内存
Dalvik Heap: Java对象new得到的内存
Dalvik Other: 类数据结构和索引占据的内存
Stack: 栈占用的内存(栈空间使用,如函数调用、局部变量等)
Pss Total: 在硬盘上实际占用的空间大小
Heap Size: Heap总共内存大小 = Heap Alloc + Heap Free, HeapSize 有限制,超出阈值就oom
Heap Alloc: 应用所有实例分配的内存,包括应用从Zygote 共享分享的内存(只是分配的虚拟空间,并没有实际占用,比如:new long[1024*1024],此时alloc就会新增了8M,但是由于没赋值,所以物理内存上并没有占用,如果针对每个元素赋值,则pss total 就会增加8M)
Heap Free: 堆空闲的大小
Objects: 统计App内部组件对象的个数,其中Views、ViewRootImpl以及Activities个数,在Activity的onDestroy之后应该都会清零,如果未清零,就可能发生了内存泄露
Private Dirty: 私有的脏内存页(还在使用中)
Private Clean: 私有的干净内存页(现在未使用了)
Private Dirty + Private Clean 便是应用曾经申请过的内存空间大小
以上内容参考自简书上的博客
7、引申-ArrayMap的原理、SparseArray原理
点击看答案
ArrayMap
ArrayMap 相对HashMap 而言是以时间换空间。它使用两个数组,一个整数型数组存储 key 的 hashCode,另一个Object[] 类型的数组存储 key-value键值对,如下图所示:
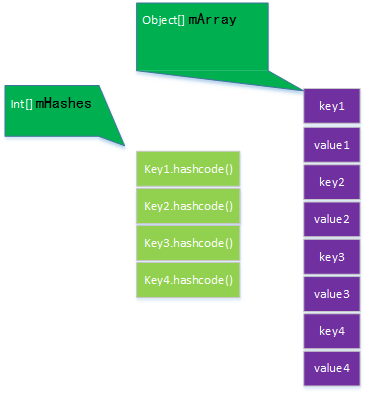
这样的结构避免了为每个key创建额外的对象,也即避免了自动装箱(如需要将int包装成 Integer) ,每次put新元素时,key的hashcode 在hashCode的数组中按照顺序存储,object数组中存储key和value。查询元素时,首先获取key的hashCode,然后用二分法查找该hashCode 在第一个数组中的index,则在object 数组中,key的位置在 index<<1 处,而value在 index<<1 + 1 处,如果此时的key并不是当前的key,则认为发生了冲突,此时以该key为中心点,分别上下匹配,直到匹配到为止。
在插入删除元素时,由于是数组组织形式,因此需要移动相关的元素,因此效率并不高;但是在数据量相对较少的情况下(有些博客说是1000条数据以下),ArrayMap 带来的时间开销并不明显,但是节省的内存却十分可观。
SparseArray
SparseArray 用于key为int类型,value 为 Object 的情形,与HashMap 相比,它避免了Integer 自动装箱,并且没有依赖entry 数据结构,因此更高效。它的结构如下图所示:
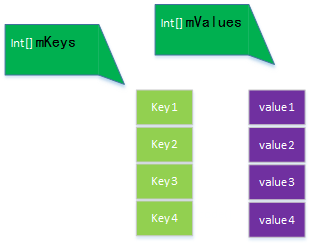
因为key是int类型,所以也就不需要什么hash值来计算index了,只要int值相等,就是同一个对象。插入和查找也是二分法,所以原理与ArrayMap 基本上一致,所以不多说。为了提升性能,删除元素时,并不需要马上将元素置为空,而是先将其标记为一个需要删除的元素,等真正需要删除时,才清空处理。即如果要插入新数据,如果数组已经填满了,则尝试垃圾回收一下,把标记为DELETE 的对象回收,然后重新寻找key值对应的索引,并插入。
** 除了SparseArray 可以替代 HashMap<Integer,V>外,还有 SparseIntArray替换HashMap<Integer,Integer>、SparseLongArray替换HashMap<Integer,Long>、LongSparseArray 替换 HashMap<Long,V> **
以上内容可以参考这个链接
8、描述http 三次握手?为什么3次,2次或者4次不行?
点击看答案
首先,准确地说是TCP/IP三次握手。因为http本身是应用层协议,只是因为目前http的传输层确实是TCP/IP,所以可以这么说。但是http并不依赖于tcp/ip。
TCP发起连接的一方A,会随机生成一个32位的序列号,比如是1000,以该序列号为原点,对自己每个将要发送的数据进行编号,连接的另一方B会对A的每次数据进行确认,如果A收到B的确认编号是2001,则意味着 1001~2000 编号已经安全到达B。握手的示意图如下所示:
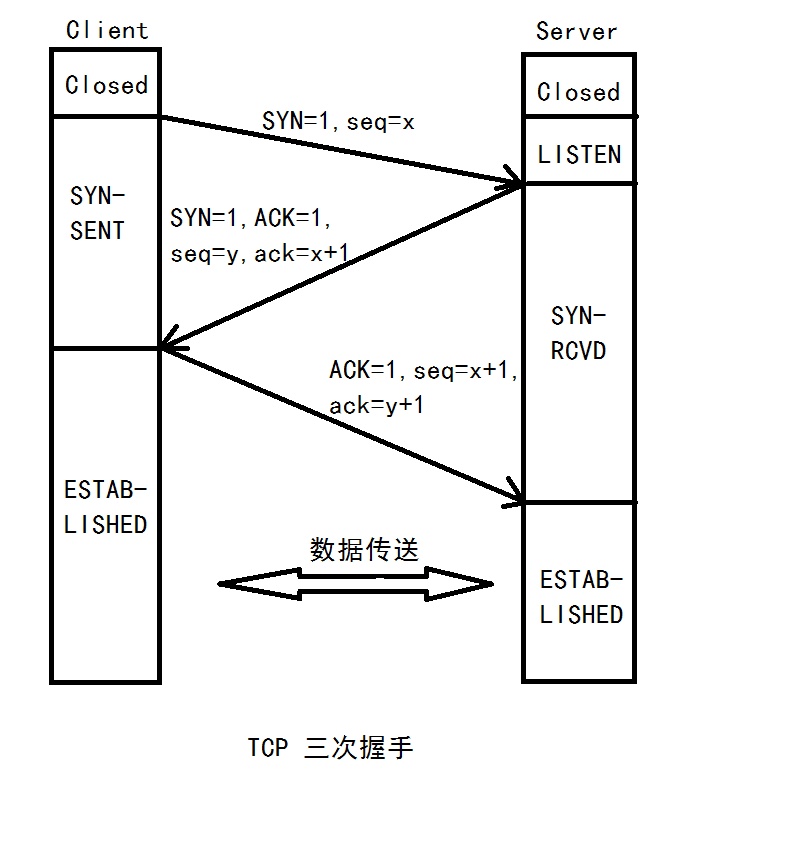
所以我们可以总结,TCP 连接握手,握的是啥?其实就是告知双方数据原点的序列号。那为什么是3次握手呢?个人认为有两个原因:
- 确认通信双方的 接收/发送 能力是正常的。第一次握手,B可以知道自己的接收能力、A的发送能力是正常的;第二次握手,A可以知道双方的收/发能力是正常的;第三次握手,B知道双方的收/发能力都正常。
- 节省资源。我们知道,等3次握手结束后,服务端才给这条链接分配必要端口、缓存等资源。如果是2次握手,那么在收到客户端的请求后服务端就得分配资源了,如果第2次握手由于超时丢失,那么客户端会认为服务器还未响应,可能造成两端都在等。或者客户端等到放弃这次请求,而服务端之前分配的资源会被浪费。
因此,3次握手是必需的,更多的请求次数可以,但是浪费资源,没必要。
以上内容有部分是参考知乎中的内容
9、延伸-http 使用80端口,如果客户端一个tcp/ip在连接,那么就无法建立其他tcp/ip连接,因为80端口在占用?
点击看答案
不是的,80端口一般只是http应用的默认监听端口,就是说新的连接都是发送到80端口的。但是监听80端口的程序会给新建立的连接分配一个可用的端口,所以实际的这条连接可能是机那里在服务端的 10010端口,客户端的8888端口上的。而80端口会继续监听是否有新的连接到来。
10、描述4次挥手,3次行不行?为什么?
点击看答案
tcp/ip 是全双工的,client 端在没有数据需要发送给server的时候,就发送FIN 信号告知Server ,然后终止对server 的数据传输,但是server 可以继续对client 发送数据包,这时候就是4次来终止连接,过程如下图所示:
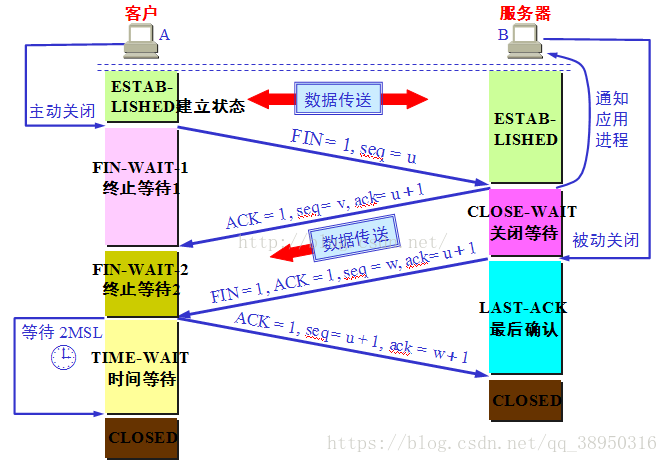
但是,如果Server 收到client 的FIN 包之后,再也没有数据要发给Client 了,那么对Client 的ack 包和 Server 自己的FIN 包就能合并成一个包发送出去,4次挥手就能变成3次挥手。
关于图中的 time_await ,它的作用主要是1、为实现TCP全双工连接的可靠释放;2、为使旧的数据包在网络因过期而消失。更详细的解释可以参考以前的这篇文章
11、了解哪些设计模式?写个单例模式?
点击看答案
- 单例模式
- 建造者模式
- 工厂模式
- 适配器模式
- 装饰模式
- 观察者模式
1 | //线程安全的单例模式代码 |
以下针对项目可能的提问
12、了解多线程使用,聊聊锁可以分为哪些种类
点击看答案
大体可以分为,这不全部指锁的状态,有的指锁的特性,有的指锁的设计:
- 乐观锁/悲观锁
- 公平锁/非公平锁
- 偏向锁
- 轻量级锁
- 自旋锁
- 可重入锁
具体可以参考以前写的这篇博客
13、引申-聊聊 HandlerThread
点击看答案
HandlerThread 继承了 Thread ,所以本质上是个workThread,只不过它带了个Looper,无需开发者自己去做Looper.prepare() 操作,可以看下其关键源码:
1 |
|
所以我们在使用的时候,首先new 出一个对象来,接着就要执行其start() 方法,以便完成 Looper 的初始化,其中,notifyAll() 主要用于方法 getLooper() 中通知 Looper 已经准备好,唤醒wait:
1 | public Looper getLooper() { |
在使用完成之后,需要手动退出Thread:mHandlerThread.quit(); ,其原理不用写也知道:
1 | public boolean quit() { |
从以上原理我们可以知道,HandlerThread 的使用场景就是:需要在子线程执行耗时的,并且可能有多个任务的操作(每个任务都开线程导致线程太多啊),比如多个下载任务(非同一个任务多线程下载),还有一个典型例子就是IntentService。
14、延伸-IntentService
点击看答案
我们知道,IntentService 使用非常简单,不需要自己建立线程,执行完毕后也无需我们自己关闭Service,只需要专心在 onHandleIntent(Intent intent) 方法中实现逻辑即可。IntentService 使用工作线程逐一处理所有启动请求,如果不需要在Service中执行并发任务,IntentService 是最好的选择。至于如何做到的,我们只要看关键源码即可:
1 | public abstract class IntentService extends Service { |
IntentService onCreate 中创建了 HandlerThread 实例,mServiceHandler 创建时使用了 HandlerThread 的 Looper,这决定了最终业务是在HandlerThread 中的子线程中执行的,在 handleMessage 方法中看到了熟悉的 onHandleIntent 方法调用,待 onHandleIntent 执行完毕后,马上执行Service 的 stopSelf(msg.arg1) 关闭自己。
这里使用 stopSelf(msg.arg1) 而不是 stopSelf(),而msg.arg1 即 startId,而这个 startId 就是 onStartCommand(Intent intent,int flags,int startId) 的最后一个参数。我们知道多次调用startService 来启动同一个Service ,只有第一次会执行 onCreate ,但是会多次调用onStartCommand,以及onStart(所以IntentService 中,在onStart方法里面发送Message到Handler),并且每次 startId 并不相同,且都大于0。而stopSelf() 最终会调用 stopSelf(-1)
。
stopSelf(int startId) 中的startId 与 onStartCommand 的startId 是一一对应的关系,所以,当我们调用stopSelf(int startId)时,系统会检测是否还有其它startId 存在,有的话就不销毁当前service,没有的话则销毁。
所以,为什么是调用stopSelf 而不是调用 stopSelf(int startId),从上面的比较我们得出:这是为了提高 IntentService 的利用率,如果在 onHandleIntent 方法执行完毕前,又调用了startService 启动了同一个 IntentService ,那么我们就没必要销毁当前service了,直接继续使用当前service 对象执行任务即可,这样有利于减少对象的销毁及创建。再提及一句,由于是使用HandlerThread ,所以多个任务只能是串行方式依次执行。
以上内容参考俗人浮生 的博客,以及 IntentService 官方源码
15、volatile 关键字有了解吗?
点击看答案
讲解之前,首先了解 原子性、可见性 以及 有序性 的基本概念:
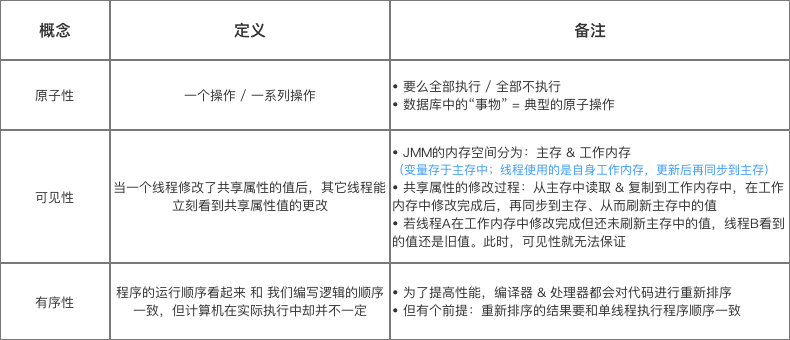
一言以蔽之,volatile 保证可见性、有序性,但是不保证原子性。
保证可见性:多个线程共享一个volatile变量k,如果一个线程在工作内存中修改k的值会立即刷新到主存,同时将其他线程中的该值设置成已过期,其他线程在下次使用k值时,需要从主内存刷新获取。在k值更改前就已经在使用的情形,比如k值在做加法的途中,如果k值改变,则是不受影响的,必须是下一次再次使用k的时候,才会从主存去刷新。还有要注意的是,子线程使用成员变量都会将变量从主存中拷贝一份,而不是直接使用。
保证有序性:我们知道为了提高性能,cpu或者编译器会对代码重排序,代码的执行顺序不一定和我们写的顺序是一致的,它们只保证最终结果一致。volatile 保证读/写volatile 属性时,其前面的代码必须已经执行完成,它后面的代码也不能排到前面来执行。
不保证原子性:也即前面提到的,比如在做加法途中,这个k值改变了,是无法改变正在做的加法中的k值的。这也是volatile 修饰变量并不是线程安全的原因。
如果还不太了解,可以参考以前写的这篇读书笔记、还可以参考这篇文章,讲得很透彻
16、什么是大接口?
点击看答案
大接口就是所看到的整个页面,都是由一个接口数据决定的。当时基于的背景有几个:
- 这个行业决定,如果有需求,可能会要求某个版本不让用户使用了。
- 还是行业决定,页面要求能灵活变动,随时可能某个模块没有了,或者某个tab没有了。
- 减少接口数量,减轻后台压力,我们知道,频繁的、少量数据的接口请求对后台不友好,可能握手、header 等就能占用很大一部分资源。
怎么做的:
本地有若干指定的view映射,根据后台返回,可以动态添加这些view。一般view都是占满一行,左右两边的边距确定。
17、怎么防止劫持?
点击看答案
背景:当时有用户反馈,我们的 webview 打开慢,并且有时候弹出广告,可我们自己并没有添加广告,因此初步认定可能是运营商劫持,事实上我们在百度上搜索一下运营商劫持,就有一大把的搜索结果,看来并非我们一家。在这个基础上,分析应该是通过dns 污染导致的。
所以解决方案就是不使用运营商的dns,而使用119(腾讯的 119.29.29.29) 和 114(114.114.114.114) 的dns,参考网上的方案,自己写了个实现。在获取到的ip 中,随机选中一个缓存起来,缓存有效时间为15分钟。
在 API 的http 请求中,拦截请求,查询是否缓存该host的ip,如果有,判断是否过期。如果没有缓存或者过期,则会通过上面步骤获取ip,并把host 换成ip直连。
针对webview的http 类型的get请求,在WebviewClient 的 shouldInterceptRequest 回调中(执行在子线程),使用自定义构建的网络请求(根据WebResourceRequest 的 url 以及 headers 构建 okhttp 的 okHttpRequest,其中headers也加入okHttpRequest 的headers 中)。该请求会在可能的情况下,将url替换成ip直连,获取结果后,自行重新组装 WebResourceResponse 对象return。
https的ip直连会碰到一些问题,具体可以参考别人的博客
18、一般走查哪些代码?
点击看答案
关键代码,比如容易出现死循环的重试机制、错误上报机制、安全检测机制
19、如何文档归档
点击看答案
使用wiki,wiki内容包括:
- 后端接口以及参数说明
- 前端支持的协议以及支持的格式
- 关键逻辑的边界和参数,如自动登录尝试的次数,防止出现死循环;网络超时时长
其他部门做业务的时候只需要看wiki就行,不用找具体的技术人员查看客户端代码
20、聊聊这个内部sdk的设计?
点击看答案
以前没有做过sdk,貌似也没地方可以参考,还有时间也很紧急,所以在技术上直接采用500里面的技术,并没有什么新意,做完之后,有小需求做的同时慢慢重构,自己得出一些经验吧:
- 控制调用权限。只暴露几个类给用户即可,其余的类不允许用户调用。
- 确定回调方式。1、调用接口中需要传递 activity,业务中使用用户的activity 执行activityForResult 接受业务返回数据。 2、如果使用广播,则使用本地广播
- 防止资源名称和宿主app冲突,资源名称添加特定前缀
- 传入的参数各种各样,需要注意判空、检验数据格式合法性等
- 尽量不使用第三方的类库,目前sdk中使用第三方类库,接sdk的时候要求用户添加依赖
21、最有成就感的项目?最棘手的问题?
点击看答案
最有成就感的可能就是xx app吧,接触得比较多,虽然目前的流畅度还是一般般,但是做了比较多的努力:
- 性能优化
- 大接口试验
- 在以前的基础上动过网络框架和图片框架
- 在安全上也做了一些努力
22、引申-如何重新设计网络框架?
点击看答案
- 调用方式改变,不需要传递2次的 responseClass
- 采用kotlin 的线程调度(GlobalScope.launch()) 而不是rxjava 进行线程间的切换
23、引申-安全做了哪些努力
点击看答案
- 在native层做app签名校验
- 广播统一改为本地广播
- LeakCanary防止内存泄漏
- SharedPreference加密
- allowBackUp = false
- 某些key生成在native代码中做
- https证书本地验证。
24、讲一讲你看过的第三方框架的源码?
点击看答案
可以讲讲 LeakCanary 和 阿里的框架 alpha
25、逛哪些论坛?
点击看答案
有逛csdn,gank.io(不过gank.io有时候更新得比较慢),apkbus,androidweekly.cn 啊 等等。
26、平时关注什么技术?
点击看答案
目前关注的就是 flutter 了
27、有什么想问我的
点击看答案
如果是hr初面:
这个岗位是新开设的还是原岗位人离职了?
这个岗位可以为公司带来什么价值?
想了解以下公司的培训机制和学习机制
如果是技术人员:
你觉得我能胜任这个职位吗(看这一关是否通过了)?
感觉不好,就问:你觉得我还有哪些不足?
终面的话:
如果顺利,问下部门、公司的发展啦
如果觉得基本上没戏了,就问下自己的缺陷在哪
如果模棱两可,问下一步流程是怎么样的
