概述
在许多情况下,让计算机同事去做几件事情,不仅是因为计算机的运算能力强大了,还有一个很重要的原因是计算机的运算速度与它的存储和通信子系统的差距太大,大量的时间都花费在磁盘I/O 、网络通信或者数据库访问上。
硬件的效率与一致性
高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但也为系统引入了一个新问题:缓存一致性(Cache coherence)。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主存(Main memory),当多个处理器的运算任务都涉及同一块主内存区域时,可能导致各自的缓存数据不一致,此时,同步回到主存时以谁的缓存数据为准呢?
除高速缓存外,为了使处理器内部运算单元尽量被充分利用,处理器可能会对输入代码进行乱序执行(Out-Of-Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但是并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致。因此,如果某个计算任务依赖另一个计算任务的中间结果,那么其顺序性不能依靠代码的先后顺序来保证。
Java 内存模型
Java 内存模型(Java Memory Model, JMM) 是用来屏蔽各种硬件和操作系统的内存访问差异。
主内存与工作内存
Java 内存模型的主要目标是定义程序中各个变量的访问规则,此处的变量(Variables) 包括 实例字段、静态字段和构成数组对象的元素,但不包括局部变量与方法参数,因为后者是线程私有的,不存在竞争。
注意区别:如果局部变量是个refrence类型,它引用的对象在Java堆中可能被各个线程共享,但refrence本身在Java栈的局部变量表中,是线程私有的。
Java内存模型规定所有的变量都存储在主内存(Main Memory),每条线程还有自己的工作内存(Working Memory),这两个分别可以类比物理模型中的主内存以及处理器的高速缓存。线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量。
关于副本拷贝,假设线程访问一个10MB 的对象,那会不会也拷贝出来呢?虚拟机基本上不会这么实现,只有对象的引用、对象中某个在线程中访问到的字段是可能存在拷贝的。还有,这里所讲的主内存、工作内存 与 前面讲的Java堆、栈、方法区等并不是同一个层次的内存划分,二者并没有关系。
内存间交互操作
Java 内存模型中定义了以下8种操作来完成从主内存拷贝到工作内存,以及从工作内存同步回主内存:
- lock(锁定):对主内存变量标识为某一条线程独占。
- unlock(锁定):对主内存变量标识为解锁。
- read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存,以便后面的load操作。
- load(载入):作用于工作内存变量,把read操作从主内存得到的变量值放入工作内存的变量拷贝中。
- use(使用):作用于工作内存变量。把工作内存中一个变量的值传递给执行引擎。当虚拟机遇到一个需要使用到变量的值的字节码指令时执行这个操作。
- assign(赋值):作用于工作内存变量。把一个从执行引擎接收到的值赋值给工作内存的变量。当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存变量。把工作内存中一个变量的值传送到主内存中,以便随后的write操作。
- write(写入):作用于主内存变量。把store操作从工作内存中得到的变量的值放入主内存的变量中。
如果要把一个变量从主内存复制到工作内存,那就要顺序地执行 read 和 load 操作(只是顺序地执行,不保证连续执行,中间是可以插入其他指令的),如果要把变量从工作内存同步回主内存,就要顺序地执行 store 和 write 操作。并且,Java 内存模型要求执行上述操作必须满足下列条件:
- read 和 load、store 和 write 必须成对出现,不许单独出现。
- 变量在工作内存中改变了之后,必须要同步回主内存,即不允许丢弃它最近的 assign 操作;并且如果没有发生assign,则不允许同步回主内存。
- 对一个变量 use、store 之前,必须先执行过了 assign 和 load 。
- 一个变量在同一时刻只允许一条线程执行 lock 操作,但 lock 操作可以被同一条线程重复执行多次,多次 lock 后,只有执行相同次数的 unlock 操作后变量才能被解锁。
- 如果对一个变量执行 lock 操作,那会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作初始化变量值。
- 如果变量没有被 lock 锁定,那就不允许对它执行 unlock ,也不允许 unlock 一个被其他线程 lock 住的变量。
- 对变量执行 unlock 之前,必须把此变量同步回主内存中(执行 store、write 操作)。
对于 volatile 型变量的特殊规则
volatile 可以说是Java虚拟机提供的最轻量级的同步机制。这里首先以不正式但通俗易懂的语言来介绍这个关键字的作用,当一个变量定义为 volatile 后,它将具备两种特性:
- 第一是保证此变量对所有线程的可见性,这里的“可见性”是指当一条线程修改了这个变量的值,新值对其他线程来说是可以立即得知的。而普通变量是做不到这一点的。
- 第二个语义是禁止指令重排序优化。
关于volatile 变量的可见性,经常会有开发人员误解,认为 “volatile 变量在各个线程中是一致的,所以基于 volatile 变量的运算在并发下是安全的”,因为事实上我们不能得出“基于 volatile 变量的运算在并发下是安全的” 这样的结论,因为虽然volatile变量在各个线程的工作内存中不存在一致性问题(由于每次使用之前都要先刷新,所以执行引擎看不到一致的情况,所以可以认为不存在一致性问题),但Java里面的运算并非原子操作,所以导致 volatile 变量的运算在并发下一样是不安全的。通过以下简单代码可以演示:
1 | public static volatile int race = 0; |
注意:我个人运行这段代码的时候,并不能正常打印,因为while循环中的 Thread.activeCount() 一直是2,只有把 for 循环中的 System.out.println(race) 放开才能打印,我的环境是: Android Studio 3.5 + jre1.8 。,如果并发正确的话,最终输出结果应该是 200000,但实际运行的结果大概率会是一个小于 200000 的数字。为什么呢?问题出在 increase() 方法中的 race++ 操作上,我们可以使用javap命令反编译这个函数的代码得到如下的字节码:

发现只有一行代码的increase方法在class文件中是由4条字节码指令构成的(return 不是由 race++ 产生的),所以很容易分析出并发失败的原因了:当getstatic 指令把 race 的值取到操作栈顶时,volatile 可以保证 race 的值是正确的、最新的,但在执行 iconst_1、iadd 这些指令的时候,其他线程可能已经把 race 的值增大了,所以最后执行 putstatic 指令后可能把较小的 race 值同步回了主内存中。
客观地说,此处用字节码来分析问题仍然是不严谨的,因为即使编译出来只有一条字节码指令,也并不意味着这条指令就是一个原子操作,一条字节码在执行时,解释器往往要运行多行代码才能实现它的语义。如果是编译执行,一条字节码可能会转化成若干条本地机器码指令。但考虑阅读方便,并且字节码已经够说明问题,所以此处选用字节码分析。
以上代码说明volatile 在并发运行中可能出现的问题,但是如下代码场景就很适合使用 volatile 变量来控制并发,当shutdown 方法调用时,能保证所有线程中执行的 doWork() 方法都能停下来:
1 | volatile boolean stopThread; |
volatile 禁止指令重排序优化仍然不太容易理解,通过以下伪代码来看看为何指令重排序会干扰程序的并发执行:
1 | Map configOptions; |
这个场景十分常见,只是我们在处理配置文件时一般不会出现并发而已。如果 initialized 没有使用 volatile 修饰,就可能由于指令重排序优化,导致 initialized = true 被提前执行(指令重排序优化是机器级的优化操作,这里说的提前执行是指对应的汇编代码提前执行),这样线程 B 中使用配置信息的代码就可能出现错误,而volatile 可以避免此类情况发生。以下再举个例子来说明 volatile 关键字是如何禁止指令重排序优化的:
1 | public class Singleton{ |
编译后,这段代码对instance变量赋值部分如下代码所示:

可以对比 instance 有被volatile修饰和没有被修饰的编译后的代码,会发现,关键变化在于有 volatile 修饰的变量,在赋值(mov %eax,0x150(%esi) 这句就是赋值操作),之后会多执行一个 lock 操作,这个操作是一个内存屏障,令重排序时不能把后面的指令重排序到内存屏障之前的位置。只有一个cpu访问内存时,并不需要内存屏障;但如果有两个或更多cpu访问同一块内存,且其中有一个在观测另一个,就需要内存屏障来保证一致性。这操作也相当于做了一次 store 和 write 操作,引起其他cpu(或内核)对于这个变量的无效化,因此保证了 volatile 变量的修改对其他cpu立即可见。
在某些情况下,volatile 的同步机制的性能确实要优于锁,但是虚拟机对锁实行许多消除和优化,所以我们很难量化地认为 volatile 的同步机制比锁快多少。但是可以肯定的是:volatile 变量的读操作与普通变量几乎没差别,但写操作可能会慢一些,因为它需要需要在本地代码中插入内存屏障保证处理器不乱序执行。
long 和 double 型变量的特殊规则
long 和double 都是64位数据类型,内存模型允许虚拟机将没有被 volatile 修饰的64位数据类型的读写操作分为两次32位操作来进行,可能会导致某些线程读到”半个变量”的数据,不过这种情况十分罕见(目前商用Java虚拟机不会出现),所以了解这回事即可。
原子性、可见性 与 有序性
整体回顾一下Java内存模型,Java内存模型是围绕着在并发过程中如何处理原子性、可见性和有序性3个特征来建立的。
原子性(Atomicity):read、load、assign、use、store 和 write 操作是保证原子性的,基本数据类型的访问读写也是具有原子性的。如果要保证更大范围的原子性,Java 内存模型还提供了 lock 和 unlock 来满足这种需求。
可见性。可见性指一个线程修改了共享变量的值,其他线程能立即得知这个修改。除了volatile 之外,Java还有两个关键字能实现可见性,即 synchronize 和 final 。同步块的可见性是由 “对一个变量执行unlock操作前,必须把此变量同步回主内存中” 获得的。而final修饰的字段在构造器中一旦初始化完成,并且构造器没有把 “this”的引用传递出去(this引用逃逸是很危险的,其他线程可能通过这个引用访问到”初始化了一半”的对象),那在其他线程中就能看到 final 字段的值。
有序性。Java 程序中有序性可以总结为:如果在本线程内观察,所有操作都是有序的;如果从一个线程观察另一个线程,所有操作都是无序的。前者指“线程内表现为串行语义” ,后者指“指令重排序”和“工作内存与主内存同步延迟” 现象。Java 语言提供了 volatile 和 synchronized 来保证线程之间操作的有序性,前者本身包含了指令重排序的语义;后者通过 “一个变量在同一个时刻只允许一条线成对其进行lock操作”决定了持有同一个锁的两个同步块只能串行进入。
先行发生原则
这块理论性的总结性的内容,个人觉得就先不写了。
Java 线程
线程的实现
这块的内容在操作系统的内容中有描述:
- 使用内核线程实现(每个内核线程对应一个轻量级进程);
- 使用用户线程实现(创建销毁开销小,没有内核支援,处理诸如阻塞等问题异常困难);
- 使用用户线程+轻量级进程混合实现(即内核线程和用户线程一起使用,n: m 的关系)。
Java 线程调度
线程调度的方式主要有两种: 协同式线程调度(Cooperative Threads-Scheduling) 和 抢占式线程调度(Preemptive Threads-Scheduling)。前者靠线程自觉,线程执行时间由线程自己控制,后者每个线程由系统分配时间,Java 使用后者。
虽然Java线程调度是系统自动完成的,但是我们可以给线程设置优先级来“建议”系统给某些线程多一些时间。但给线程设置优先级还是不靠谱的,原因如下:
Java 线程是通过映射到系统的原生线程上来实现的,不同的系统上的优先级与Java的线程优先级等级基本上对应不上。可能你在Java中指定的2个优先级,在某操作系统上映射成同一个优先级。
优先级可能会被系统自行改变。
状态转换
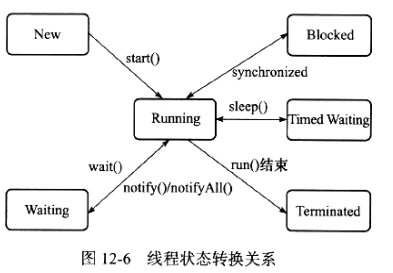
Java 语言定义了5种线程状态,在任一时间点,一个线程只能有且只有其中的一种状态:
- 新建(New):创建后尚未启动。
- 运行(Runnable):可能在执行,也有可能在等待 CPU 分配时间。
- 无限期等待(Waiting):这种状态下不会被 CPU 分配时间,要等其他线程显式地唤醒。
以下方法会让线程陷入无限期等待:
没有设置 Timeout 参数的 Object.wait() 方法。
没有设置 Timeout 参数的 Thread.join() 方法。
LockSupport.park() 方法。
- 限期等待(Timed Waiting):这种状态下不会被 CPU 分配时间,不过无需等待其他线程显式唤醒,在一定时间后由系统自动唤醒。
以下方法会让线程进入限期等待:
Thread.sleep() 方法。
设置了 Timeout 参数的 Object.wait() 方法。
设置了 Timeout 参数的 Thread.join() 方法。
LockSupport.parkNanos() 方法。
LockSupport.parkUtil() 方法。
阻塞(Blocked):阻塞状态是在等待获取一个排他锁。
结束(Terminated):线程已经执行结束。
线程状态转换图如下: