1、是否可以在子线程更新UI
点击看答案
今天看到网上有人较真,说Android中,你可以在子线程更新UI,于是我写了如下测试代码:
1 | override fun onCreate(savedInstanceState: Bundle?) { |
在子线程中更新EditText的文字居然成功!其实,在主线程修改UI,这属于一个“建议”而不是“标准”,因为如果在子线程定义UI的修改,无法预料到UI会被如何修改。
一言以蔽之:View之所以不能在子线程做UI操作,是因为在 ViewRootImpl 里面会做线程检测,而在onCreate 的时候,ViewRootImpl 还没初始化。
settext的调用流程大概会经历如下步骤:
- TextView 的 checkForRelayout() 方法
- TextView 的 invalidate() 方法
- View 的 invalidate() 方法
- View 的 invalidateInternal() 方法
- ViewGroup(ViewParent) 的 invalidateChild() 方法(不断loop取上一个节点的mParent,然后DecorView 的mParent 是 ViewRootImpl )
- 即一直调用到 ViewRootImpl 的 invalidateChild()
- 最终在 ViewRootImpl 中会 checkThread()检查线程
在ViewGroup 的 invalidateChild() 中,会判断 AttachInfo 是否为空,而在Activity 的 onCreate的时候,Activity 还在初始化,ImageView的mAttachInfo 是空的,所以在ViewGroup 中就直接没执行下去了,而settext 早就发生了,因此,就略过了检查线程这一阶段。
2、延伸-子线程更新UI骚操作-在子线程启动 Dialog
点击看答案
我们可以看下 ViewRootImpl 中的 构造函数 和 checkThread() 方法:
1 | //构造函数 |
可以发现,这里并不是要求什么主线程(UI线程),而是只要当前线程和ViewRootImpl/Window/View 的创建线程是同一个线程就ok,所以,只要在子线程中创建的View,就能在那个子线程更新UI,试试如下代码(我自己亲测可以运行):
1 | val runnable = Runnable { |
延伸-在子线程更新UI的另一个解释:
在子线程自己获取 WindowManager (MainActivity.this.getWindowManager) ,然后创建TextView并add到window中,就能展示的。因为呢,我们并不是说限制主线程,而是说要求更新ui的线程和 创建ViewRoot是否属于该线程
3、LruCache 原理
点击看答案
LRU(Least Recently Used,最近最少使用) 缓存算法就是为缓存设计的,它的思想就是当缓存满时,会优先淘汰那些最近最少使用的缓存对象。LruCache 就是Android 基于 LRU 算法给的一个缓存类。
LruCache 的核心就是维护一个缓存对象列表,其中对象按照访问顺序实现的,即一致没访问的对象,将放在队尾,首先被淘汰,最近访问的对象放在队头,最后淘汰。如下图所示:
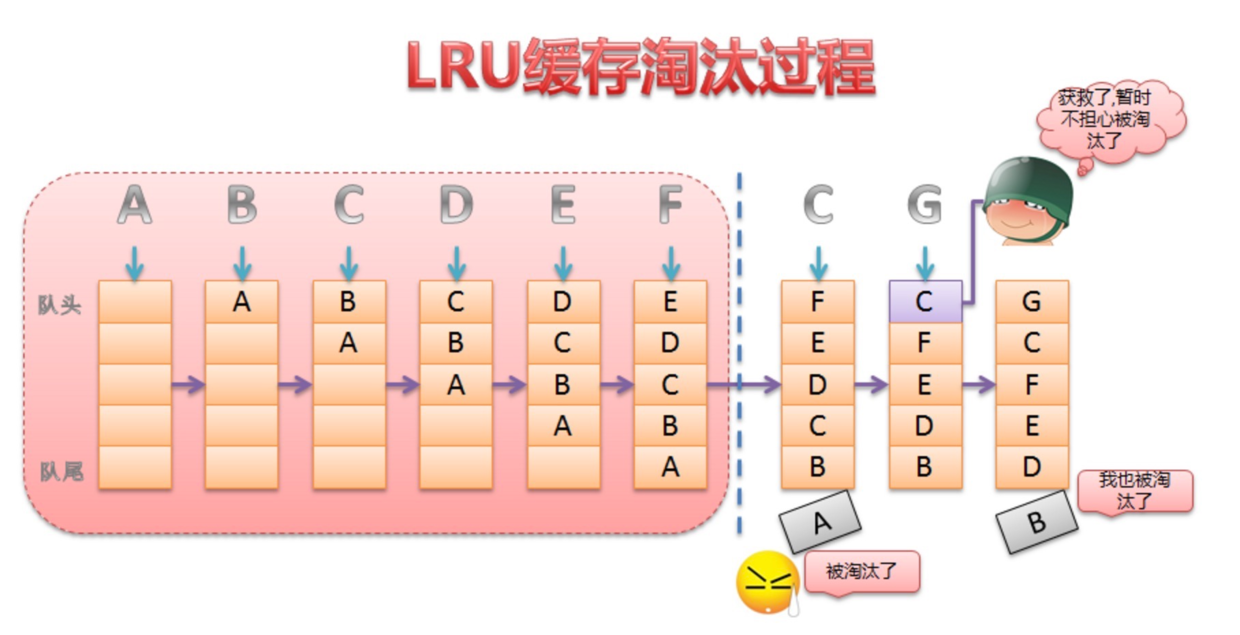
这里面的队列是由LinkedHashMap 来维护的,前面已经介绍过它的实现原理了,他有个构造函数是这样的:
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
最后一个参数 accessOrder 用来表示LinkedHashMap 中双向链表的顺序是插入顺序还是访问顺序,举个例子:
1 |
|
如果在构造LinkedHashMap 的时候,accessOrder 为false ,则会依次打印:
key = 0,value = 0
key = 1,value = 1
key = 2,value = 2
key = 3,value = 3
key = 4,value = 4
key = 5,value = 5
如果为true,则会打印:
key = 0,value = 0
key = 3,value = 3
key = 4,value = 4
key = 5,value = 5
key = 1,value = 1
key = 2,value = 2
这是因为为true时,会导致最近访问的最后输出,那么这就刚好满足LRU 缓存算法的思想,所以LruCache 的巧妙实现,就是利用了 LinkedHashMap 的这个功能。 所以LruCache 的构造函数为:
1 | public LruCache(int maxSize) { |
所以LruCache 后续的操作就比较好理解了:
- 在put 新元素的时候,首先判断 key 和value 都不能为空,之后更新缓存大小;如果之前这个key 有值,则替换这个值,由于已经先前更新过缓存大小,此时要把老的value所占缓存大小减去。最后调整缓存大小,如果缓存大小超过阈值,则依次取出LinkedHashMap 中取出key-value 删除,直到小于阈值为止。
- get 的时候,判断 key 是否为 null ,不能为 null 。get操作之后,接着把这个节点删除,再把这个节点添加(头插法,会插入到头部,这样保证顺序)。
4、聊聊handler机制? 一个线程是否只有一个Looper?如何保证一个线程只有一个Looper?
点击看答案
Handler 初始化的时候会通过 Looper.myLooper(实际上只是返回了 sThreadLocal.get()) 获取当前线程的Looper。之后通过 looper 获取当前线程的 mQueue 。
当然,如果在子线程中new Handler ,基本上会提示 您还未执行Looper.prepare();
Looper.prepare() 会判断当前 sThreadLocal.get()是否已经存在了,如果已经存在了,就会提示 “一个线程只能有一个Looper”(注意,就是在这里保证了一个线程只有一个Looper)。Looper.prepare() 只是执行了sThreadLocal.set(new Looper()),在这里给线程设置了Looper。
而在主线程中,ActivityThread 的main 方法中会执行 Looper.prepareMainLooper()来设置Looper,故我们可以直接new Handler,而在子线程中要手动Looper.prepare()才行,并且还要Looper.loop(),让消息循环。
接下来就是 handler 的 sendMessage 和post 方法,其实两个方法都是调用 sendMessageDelay 方法,只不过post方法首先将 Runnable封装成Message,变成Message的CallBack。
在最终send的时候,Message会持有handler的引用,叫做target,之后,message被丢到handler所持有的MessageQueue中。
之后,在主线程中,Looper一直在循环,取出queue中的Message,然后执行message.target.dispatchMessage,在这个方法中,最终会调用到我们写handler时候覆写的 handleMessage 方法。至此,整个流程走完。
5、Handler 的postDelay 是怎么实现的?
点击看答案
可能用举例子的方式容易懂一些:
- postDelay 一个10秒的 RunableA 到 MessageQueue,MessageQueue 会调用 nativePollOnce 阻塞线程。
- 接着post 一个 RunnableB 到 MessageQueue,由于 RunnableB 没有延时,因此when 时间比 RunableA 小,因此被插入在队头,然后调用nativeWake 方法唤醒 线程 。
- 唤醒后,MessageQueue.next() 方法继续执行,读取到第一个消息 RunnableB,由于没有延时,直接交给Looper。
- Looper 处理完B 后,再次调用 MessageQueue.next() 方法,这时候 RunableA 还没到时间,这时候调用 nativePollOnce 阻塞。
- 这个状态直到阻塞时间到或者下一次有Message 进队。
至于为什么 handler.postDelay并不是先等待一定的时间再放入到MessageQueue中,因为那样的话会需要多个定时器,增加开销。
以上内容源自阅读源码以及 网上博客
附:如何移除Handler的Message?有啥坑吗?
点击看答案
如果移除Message,有两种方式:
- 根据 Message 的 what 来移除:handler.removeMessages(what),handler.removeMessages(what.obj),当然,后者的obj如果为空,就会移除所有的 Message
- 根据token移除:handler.removeCallbacksAndMessages(token),当然,如果token为空,就会移除所有 Message (比如在Activity的onDestroy 中有时候为了避免内存泄露会移除),则只需要传入 null 即可。
handler 的延时操作有两种:
- handler.postDelayed(runnable, 10000);
- handler.sendMessageDelay(0, 10000);
但是,如果我们混合使用二者,在移除的时候可能会出现意想不到的问题,比如如下代码:
1 | //创建handler |
创建runnable:
1 | Runnable runnable1 = new Runnable() { |
执行:
1 | MyHandler handler = new MyHandler(); |
如果屏蔽最后一行,就会输出:
1 | run: 1 |
但是如果不屏蔽,就只会输出:
1 | handleMessage: 1 |
意味着两个Runnable 也被移除了!这是咋回事?原来,handler 的 postDelay 功能也是用 sendMessageDelayed 方法去实现的!这当然需要构造 Message 对象咯,然而也仅仅只是 Message m = Message.obtain();m.callback = r; 意味着会新建一个 Message ,而新建的 Message 的what值默认为0 !问题找到了,那么以后使用remove的时候需要注意什么呢?主要两点:
- 自定义Handler 处理 msg.what 的时候,what的值不要使用默认值0
- 同一个Handler 不要同时使用 postDelayed() 和 sendMessageDelayed()
以上内容参考自csdn的博客
6、RecyclerView 的性能优化
点击看答案
有以下几种方式能做到RecyclerView的优化:
数据处理与视图绑定分离。
bindViewHolder 方法是在ui线程执行的,而远端拉取数据肯定是要放在子线程的,所以我们在拉取数据之后做一些预处理后再丢给adapter,防止在 bindViewHolder 方法中再去处理时间比较、保留小数位数之类的操作。
布局优化
1、减少item布局层次 2、减少没必要的xml文件的inflate,可以使用new View()等方式(shape类型的xml 也一样)。
可能的话,为 RecyclerView 设置 setHasFixedSize(true)
这个方法的主要作用就是设置高度,来避免 rv 的 measure 和 layout 操作。比如一个垂直滚动的rv,height属性设置为 wrap_content,最初的数据集只有3条,全部展示出来也不能使rv撑满,如果我们通过notifyItemRangeInserted 添加数据,那么如果你设置了 setHasFixedSize 为true的情况下,rv高度是不会改变的。体现在diamante中就是requestLayout方法的调用。
减少itemView的监听器创建
我们无需对每一个item 都采用匿名内部类的方式添加监听,,而应该公用一个 xxListener 对象,通过id来区分不同操作,避免频繁创建对象带来资源消耗。
加大RecyclerView的缓存
通过设置 setItemViewCacheSize、setDrawingCacheEnabled 以及setDrawingCacheQuality 等方法增加缓存空间,以空间换时间,提升流畅性。
滑动过程中停止加载
使用 DiffUtil 工具
DiffUtil 工具类用来判断新数据和旧数据的差别,从而进行局部刷新,我们只需要在原来调用 mAdapter.notifiyDataSetChanged() 的地方改成下面这样:
DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(new DiffCallBack(oldDatas, newDatas), true);
diffResult.dispatchUpdatesTo(mAdapter);
最终,mAdapter 会通过调用 notifyItemRangeInserted、notifyItemRangeRemoved 等方法进行局部刷新。公用RecycledViewPool
在嵌套的 rv 中,如果子 rv 具有相同的adapter ,那么可以设置 :
RecyclerView.setRecycledViewPool(pool) 来公用RecycledViewPool。RecyclerView数据预取
默认是开启的,跟我们没关系。具体原理是,当上一帧交给gpu之后,cpu就一直处于空闲状态,需要等待下一帧才会数据处理,所以rv做了个预判,rv会取接下来可能要显示的item,在下一帧到来之前把数据提前处理好,不过呢,这个预判是不一定准确的。
7、引申-如何保存嵌套rv中的滑动装填
比如嵌套的rv这时候左滑到第三个,这时候外层的rv滑动很长距离,当前这个嵌套的rv已经看不见了,划出好远了,如何在嵌套rv再次可见的时候,恢复当时滑到的第三个。
其实 Linearlayoutmanager 中有对应的 onSaveInstanceState 和 onRestoreInstanceState 方法来处理保存和恢复机制。
8、图片加载优化
- 假设通过ImageView 显示图片,很多时候ImageView 没有原始图片尺寸那么大,把整个图片加载进内存再设置给ImageView则没必要,这时候可以在加载图片时采用低采样率加载进来。
- 与后端配合,在url 后面接上需要的图片尺寸。(目前就是这么做)
9、Activity生命周期
点击看答案
- onCreate():当 Activity 第一次创建时会被调用
- onRestart():表示Activity正在重新启动。一般情况下,当当前Activity从不可见重新变为可见状态时,onRestart就会被调用。
- onStart(): Activity已经出现了,但是还没有出现在前台,无法与用户交互。这个时候可以理解为Activity已经显示出来,但是我们还看不到
- onResume():表示Activity已经可见了,并且出现在前台并开始活动。需要和onStart()对比,onStart的时候Activity还在后台,onResume的时候Activity才显示到前台
- onPause():表示 Activity仍可见,只是不可交互
- onStop():表示Activity不可见,位于后台
- onDestory():表示Activity即将销毁,这是Activity生命周期的最后一个回调,可以做一些回收工作和最终的资源回收
10、延伸-生命周期几种普通情况
点击看答案
从 A 页面Activity 跳转到 B 页面Activity:
一、 启动过程会经历:
A:onPause-> B:onCreat-> B:onStart-> B:onResume-> A:onStop
所以我们可以得出结论:
- 在A 的onPause 中不要执行耗时操作,否则会影响新打开的B,因为当前A 的 onPause 必须执行完,B 的onResume 才会执行。
- 等 B 的onResume 执行后,A 才完全被覆盖看不见,故,B的onResume 调用完后,A的Stop 才调用。
二、按返回键返回到A:
B:onPause-> A:onRestart-> A:onStart-> A:onResume-> B:onStop-> B:onDestroy
我们得出结论:
- B 首先让出交互权力
- A 到前台(onResume)后 ,B才退到后台,B才调用 onStop
三、按Home 键:
onPause -> onStop,即让出交互,退到后台
反之,此时再点击图标唤起:
onRestart-> onStart-> onResume,即Activity 还在,只需要重新可见即可
11、Activity的启动模式
点击看答案
- standard:标准启动。
- singleTop(栈顶复用模式):在当前栈顶就复用,否则新建。
- singleTask(栈内复用模式):在当前栈存在有实例,如果在栈顶,直接使用;如果不在栈顶,将该实例之上的Activity全部出栈。
- singleInstance(单例模式):只要有这个实例,不管在哪个栈,都复用之;否则,在新的栈创建实例。
12、Fragment 为何不推荐使用构造方法传递参数?
因为activity 给fragment 传递数据时是通过 setArguments 来传递。如果采用构造方法传递,在诸如横竖屏切换的时候会调用fragment 的空的构造函数,造成数据丢失。
13、Context 理解
参考以前写的博客:https://glassx.gitee.io/2019/12/06/Android%E8%BF%9B%E9%98%B6%E8%A7%A3%E5%AF%86-%E7%AC%AC5%E7%AB%A0/
14、Android 全局异常处理
在Application 中为 Thread 设置ExceptionHandler 即可。
参考:全局异常处理
15、谈谈你对Application类的理解
点击看答案
说说对什么的理解,就是考察这个东西会不会用,重点有没有什么坑。有以下几点需要注意:
- Application 在一个虚拟机里面只有一个实例。这里不是说一个App只有一个实例,因为一个App 可能有多个进程,也就是多个虚拟机,这种情况下,每个虚拟机中都会存在一个Application 对象。
- Application 本质是一个Context ,继承自 ContextWrapper。
- Application 有 MultiDexApplication 子类,这个子类可以用来解决 65535 问题,完成多Dex 打包配置相关工作。
- 在Application 的onCreate 方法中我们会进行各种初始化,如图片加载库、log 等,但是最好别在里面进行太多耗时操作,这会影响App启动速度,可以使用异步、懒加载、延时加载等策略来减少影响。
- 通过Context.getApplicationContext ,不论是从Activity 中、Service中获取,都是同一个Application 对象。
- 在低内存情况下,Application 可能会被销毁,从而导致保存在Application 中的数据错乱,所以要注意判空或者选择其他方式保存数据。
- Application 中几个有用的回调如 onLowMemory(一般来说,这个回调的时候,background进程已经都被kill掉了) 、onTrimMemory(提供多个 Level 的告警,能够更精细化控制) ,在内存紧张的时候,在这些回调里面关闭数据库连接、移除图片缓存等方式来降低内存,降低被回收的风险。
- Application 的生命周期和虚拟机一样长,所以单例或者静态变量的初始化一定要使用Application 的Context 进行初始化,防止内存泄漏。
16、Android 中进程通信方式
可以翻看以前的读书笔记
17、Binder 原理
点击看答案
为什么要使用Binder
- 性能方面;Binder 数据拷贝只需要一次,而管道、Socket 等都需要2次,共享内存不需要拷贝,但是实现方式比较复杂。
- 安全方面;传统的进程通信方式对于通信双方没有严格限制,而Binder 机制从协议本身就支持对通信双方做身份校验,所以大大提升安全性。
IPC 原理
每个Android 进程,只能运行在自己进程所拥有的虚拟地址空间。例如,对应4G的虚拟地址空间,其中3G是用户空间,1G是内核空间,当然,内核空间大小是可以通过参数配置的。对于用户空间,进程间是不能共享的,而内核空间是可以共享的。Client 进程向Server 进程通信,恰恰是利用进程间内核空间来完成底层通信工作的。
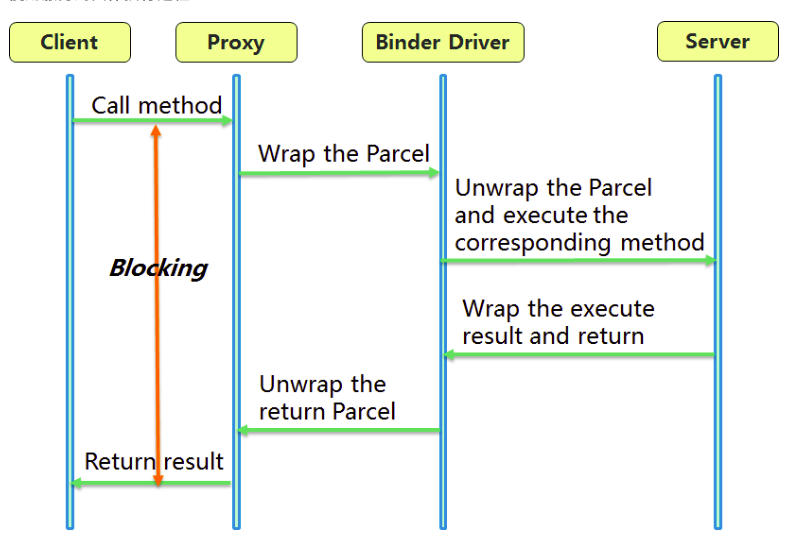
跨进程使用服务的流程
- Client 通过Server 的代理接口,对Server 进行调用。
- 代理接口中定义的方法与Server 中定义的方法是一一对应的。
- Client 调用某个代理中的方法时,代理会将Client 传递的参数打包成 Parcel 对象。
- 代理将Parcel 发送给内核中的 Binder Driver。
- Server 读取Binder Driver 中的请求数据,解包 Parcel 对象,处理并返回。
- 整个调用过程是一个同步过程,在Server 处理的时候,Client 将会Block 住。故Client 调用过程不应该在主线程。
整个流程示意图如下所示:
关于IPC,还可以参考以前的文章
以上内容参考自:进程间通信
以下内容摘自《深入理解Android:卷II》:
Binder 有两种调用方式: 阻塞调用方式 和 非阻塞方式。前者 调用方(客户端)会阻塞,直到服务端返回结果,这种方式和普通的函数调用是一样的;后者调用方只要把请求发送到Binder驱动即可返回,但一般还会向服务端发送一个回调(同样是跨进程的Binder调用),不用等待服务端的结果,一旦服务端处理了该请求,就会调用此回调函数来通知客户端处理结果。
Handler中looper会阻塞,唤醒的时候是通过 pipe 发送 w 来唤醒的
在2.3以前,我们只可以从Java层向 MessageQueue 添加消息,但在2.3以后,MessageQueue 的核心部分下移到Native层,所以有时候cpu并不是很忙,但是你的sendMessage 又是等了很久才被处理,这有可能就是在处理 Native 层的 Message。
18、延伸-Android为什么要设计出Bundle而不是直接使用HashMap来进行数据传递
点击看答案
- Bundle 内部是由ArrayMap 实现的,我们知道,ArrayMap 内部实现原理是两个数组,在添加、删除、查找 数据时,都会使用二分查找法,在数据量较小的情况下,相对 HashMap 而言,在效率相差不太大的情况下,更节省内存(HashMap的Entry Array 占用更多内存,并且没用到的会导致浪费)。而我们在Android中使用Bundle 传递数据都是比较少的,因此Bundle 更有效率。
- Android 中如果使用Intent 携带数据的话,需要数据基本类型或者是可序列化类型,HashMap 使用Serializeble 进行序列化,而Bundle 是实现了 Parcelable 进行序列化。在Android 平台中,更推荐使用 Parcelable 进行序列化,因为更少的 io 操作(但同时使用更加复杂)。
以上内容参考zhaokaiqiang的博客
19、Android中IPC通信的方式有哪些?使用场景是什么
参考以前写的读书笔记即可
20、SharedPreference 解析
点击看答案
获取SharedPreference 对象
大概有3种方式获取:
- 通过Context 的 getSharedPreference() 方法,指定name 和 mode;
- 通过 Activity 的 getPreferences() 方法,它其实最终还是调用的 Context 的 getSharedPreferences() 方法,只不过我们只需要传mode参数,因为已经在方法中将 Activity 的类名作为name了;
- 通过 PreferenceManager 的getDefaultSharedPreferences() 方法,目前基本上已经废弃
获取 SharedPreference 对象时,如果有没有存在这个xml文件,则创建,否则读取。在低于4.4 的版本上,如果name 为 null ,则会自动设置为 “null”。一直等这个 xml 文件加载解析完成,才会返回 SharedPreference 对象。
获取xml 过程中,首先会读取 ContextImpl 中的 sSharedPrefsCache 缓存:
private static ArrayMap<String, ArrayMap<File, SharedPreferencesImpl>> sSharedPrefsCache;
由于sSharedPrefsCache 是static 的,并且 Android 中所有系统都使用这一个 ContextImpl 类,所以对于所有的app而言,都公用这一个 sSharedPrefsCache,因此可以理解为,系统启动后,如果有哪个应用使用过 sSharedPrefsCache ,那么它一直会留在内存中,直到系统关闭或者重启。
根据packageName ,可以从 sSharedPrefsCache 中获取当前应用的 ArrayMap<File, SharedPreferencesImpl> 列表,我们知道,根据不同的name,在文件中都会生成不同的xml 形式的 file。我们知道,SharedPreference 的xml 文件存储在 data/{packageName}/shared_prefs 目录下,所以我们name 就能获得 file 文件的路径,进而获取到这个xml 的 File 对象。根据这个对象,我们可以获取到 SharedPreferencesImpl 对象。在SharedPreferencesImpl中存在 Map<String, Object> 类型的 mMap 保存了xml 中key-value值 (解析完xml 后将值存入其中)。所以我们在正式使用的时候,实际上是从内存中读取的。
在解析这个 xml 过程中,SharedPreferenceImpl(SharedPreference 接口的实现类) 一直都是加锁的,在这个锁定状态下,我们无法调用它的 commit 和 apply 方法(处于wait状态),直到这个解析完成,就会执行 notifyAll 方法。
SharedPreference 的值获取
我们以 getBoolean 方法为例:
1 | public boolean getBoolean(String key, boolean defValue) { |
可以看到在获取之前,首先加锁,因此这过程是线程安全的,之后 awaitLoadedLocked() 一直在等待(前面说的,在getSharedPreference() 过程中,在xml 解析完成return 之前,一直都会加锁的,完成后就会notifyAll),直到xml 文件解析完成。可以看看 awaitLoadedLocked 的源码,可以看到它的wait过程:
1 | private void awaitLoadedLocked() { |
SharePreferences内部类Editor
我们来看 SharedPreference 的 edit() 方法:
1 | public Editor edit() { |
可以看到,它也得 awaitLoadedLocked() 等待SharedPreference 准备完成。从这里还可以知道,每次 edit() 都会 new 一个 EditorImpl 对象,因此,不要频繁edit() 操作。 Editor 的具体实现是 EditorImpl 。我们可以粗略地看下它的源码:
1 | public final class EditorImpl implements Editor { |
可以看到,我们的put 、remove 之类的操作,只是修改了 hashmap中的值,并没有存入到 SharedPreference 中,通过我们平时使用知道,要在 commit 或者 apply 方法中来生效。
改动提交到 SharedPreference
1 | public boolean commit() { |
首先通过 commitToMemory 提交到内存,之后,直接在调用commit() 方法的线程中将数据写入文件。在真正写文件的时候,采用了数据库的事务思想,因为它有个 backfile 的备份文件。
接下来分析apply 方法:
1 | public void apply() { |
在子线程中提交了这个写任务,这个任务是通过handler去post的,而这个handler 初始化的Looper 是从 HandlerThread 中获取到的,所以最终还是相当于在一个个的apply 提交交给了HandlerThread 去操作,即在单线程的子线程执行。
使用时注意
- 不要存储超大的key或者value
获取一个sp的时候,会把它的整个xml 文件都加载进来,如果太大,比如说 100k,那就会耗费很长的时间。如果为了读取一个boolean 配置,要把整个100k文件加载进来,是很不合理的,会引起频繁gc,和大的内存占用,所以我们应该只要存储很轻量的数据。 还有,我们知道,在getBoolean 或者其他getXXX 方法的时候,会要等待SharedPreference 加载完成,况且,在xml 加载过程中,有多个地方加锁。在加载完成后,getXXX 操作才能执行,否则一直在等待,这过程的阻塞可能引起界面卡顿和掉帧。 所以我们可以在super.onCreate() 之前,可以先执行 getPreference。
- 不要在sp中存储 JSON 这种特殊符号很多的 value
这么做不是不可以,而是如果这个json很大,就会涉及很多转义(其实html 也会有这情况),带来很多&这种特殊符号,引发额外地字符串拼接以及函数调用开销。
- 多次edit() 和 apply()
通过以上的分析我们也知道了,每次 edit() 操作都会 new 一个 EditorImpl,这是一点。还有,经过上次我们知道,每次 apply 会往 HandlerThread 中post 一个 Runnable,然后他们会在单线程中依次执行。可能说到这里还没觉得有什么,但是我告诉你这会导致卡顿,不可思议吧?在子线程操作的,怎么可能导致卡顿呢?但是我们看 ActivityThread 源码,执行 handleStopActivity 的时候:
1 | private void handleStopActivity(IBinder token, boolean show, int configChanges, int seq) { |
就是在较老的Android版本(api 11 之前),会等待 apply 提交的那些 runnable 执行完了才能退出,如果这个时间过长,会导致anr。
- 不要用于跨进程
Android官方也不建议使用SharedPreference 跨进程(已经@deprecated),而建议使用provider。因为它并不是在所有进程上都是可靠的。并且,它通过 MODE_MULTI_PROCESS 这个标志位来实现多进程标记,其实也只是如果sp已经读到内存了,再次获取这个sp 时,如果有这个标志位,就会重新获取一遍文件。
总结一下
- 不要存放大的key和value,可能引起页面卡顿,频繁gc
- 毫不相干的配置项不要丢在一起,文件越大越慢。这样,用户没有到达的页面的sp可以不加载进来。
- 读取频繁的key和不易变动的key尽量不要放在一起。
- 不要频繁 edit 和 apply ,尽量批量修改一起提交
- 尽量不要存放 json 和 html ,防止不必要的转义
- 不要指望用sp 来跨进程通信
21、常见内存泄漏场景:
点击看答案
- 资源性对象未关闭
如 File、Cursor、stream等资源,他们的缓存不只存在java虚拟机内,还存在虚拟机外,仅仅把对象置为null而不关闭,就会引起内存泄漏
- 单例造成的内存泄漏
单例的静态性使得其生命周期跟app的生命周期一样长,如果使用不恰当(比如引用了非Application 的 Context)的话,很容易造成内存泄漏。
- 注册对象未注销
观察者模式的注册,在不使用的时候未注销,就会导致,如在Activity中监听电话服务,定义PhoneStateListener注册到TelphoneManager服务中,如果忘记注销,会导致Activity无法被Gc回收。
- 非静态内部类创建静态实例
首先,非静态内部类会持有外部类的引用。其次,创建的静态实例生命周期和应用的一样长。这样就导致了该静态实例一直会持有该外部类的引用,导致外部类内存资源不能正常回收。
- 匿名内部类和异步线程
1 | public class MainActivity extends Activity { |
上述代码中,ref2的内部类会持有MainActivity 的实例,此时引入一个异步线程,如果此线程与MainActivity 生命周期不一致,就造成MainActivity 泄漏。
- Handler造成的内存泄漏。
非静态Handler默认持有外部Activity的引用,退出Activity时,如果Looper中还有Message,就会导致Activity无法回收,可以(1)将Handler设置为静态,并且弱引用持有的对象 (2)Activity 的onDestroy的时候,一处消息队列的消息 来解决内存泄漏。
- 容器中的对象没有清理
容器里的对象在不需要的时候,要及时移除,使其正确及时地被回收。
以上内容参考自:内存泄漏场景
22、延伸-内存泄露检测工具
项目中使用 LeakCanary,参考以前的 LeakCanary 源码分析 即可
23、Android应用程序启动过程
点击看答案
参考以前的读书笔记即可
24、Apk 安装的步骤
点击看答案
分析PMS(PackageManagerService) 就能知道这个过程,总体而言有这几个步骤:
- 首先判断安装源,诸如adb/shell/all_user 等
- 将apk 文件复制到 /data/app 目录
- 解析apk 信息,包括签名校验、四大组件的注册等
- dexopt 操作,优化apk中的.dex文件,对于dalvik 虚拟机,dexopt 就是优化操作;对于art 虚拟机,dexopt 就是将.dex翻译成oat文件。
- 更新权限信息:将app所有权限几率下来更新到PMS 中,并判定是否授予该app 请求的权限。
- 安装完成,发送 Intent.ACTION_PACKAGE_ADDED 广播
以上内容参考自:apk安装步骤
25、ANR异常发生条件?如何分析ANR?
点击看答案
ANR 发生条件:
- 5s内没有响应用户输入事件
- 10s内广播接收器没有处理完毕
- 20s内服务没有处理完毕
ANR 时,系统做了什么
- 弹窗
- 将ANR 信息输出到 /data/anr/traces.txt 文件中(无需root 就能通过 adb pull 命令拷贝出来)
- 将ANR 信息输出到 Logcat 中(包含PID、Reason、CPU负载 等)
以上内容参考自: very_on
26、Android 热修复原理
点击看答案
- DexClassLoder 可以用来从 .jar 和 .apk 类型的文件内部加载classes.dex 文件。用来执行非安装的程序代码。
- 两个dex 中存在相同的 class 文件,则会从第一个dex 中找,找到了直接返回,第二个dex 中的class 永远不会被加载进来。
- 阻止引用类被打上 CLASS_ISPREVERIFIED 标志。
在虚拟机启动的时候,如果verify 选项打开,static、private方法、构造函数等 中的直接引用到的类都在同一个dex文件中,那么该类就会被打上 CLASS_ISPREVERIFIED 标志。
注意,是阻止引用这的类,也就是说,假设有类叫做 LoadBugClass ,在其内部引用了 BugClass,在发布过程中发现 BugClass 有编写错误,那么想要发布一个新的 BugClass ,那么就要阻止 LoadBugClass 这个类被打上 CLASS_ISPREVERIFIED 的标志。而这个标志是在 apk 安装的时候,优化成odex 的阶段被添加的。所以在生成apk之前就要阻止 CLASS_ISPREVERIFIED。
以上内容参考自:热修复原理
27、插件化技术原理
点击看答案
插件化就是让我们应用不必把所有的内容都放在一个apk中,可以把一些功能和逻辑单独抽出来放在插件apk中,然后主apk 按需调用。一来可以让主apk体积更小,二来可以做到热插拔,动态化。
插件化技术基础:
- DexClassLoader,想要实现加载外部的dex 来实现热部署,必然要把其中的class 文件加载到内存。DexClassLoader 能做到加载.jar 和 .apk 文件中的 class 文件。
- Java 反射:因为插件apk 与宿主apk 不再一个apk 内,那么一些类的访问必然要通过反射进行获取。
- 插件资源访问:res 里每个资源都会在R.java里生成一个Integer 类型的id,app 启动时会把R文件注册到当前的上下文环境,我们在代码中以R文件方式访问资源正是通过这些id访问。然而,插件的R.java并没有注册到当前的上下文,所以也就无法通过id使用。
我们可以通过 addAssetPath 方法重新生成一个新的 Resource 对象来保存插件中的资源,避免冲突。
- 代理模式:无论是通过activity代理还是通过DroidPlugin 去hook activity 启动过程来启动activity的方式,都是对代理模式的应用。在前一种方式中,虽然加载进来了Activity 等组件,但也仅仅是作为一个普通对象而存在,并没有在AndroidManifest中注册,没有生命周期回调。这时候通过代理即可。
以上内容参考自: http://www.androidos.net.cn/book/android-road/android/advance/plugin.html、virtualAPK 实现方式可以参考这里
28、轮播图实现原理?
点击看答案
原理:
如果只有一张图,则不作处理
如果有n张图,则在 ViewPager 的adapter中做如下处理:
- getAccount 返回 n * 10000
- instantiateItem 的时候,position 需要对 n 求余
源自项目代码
29、ListView 原理
点击看答案
ListView 原理主要要提及RecycleBin 机制,这是ListView 能够实现大量数据都不会 OOM 的一个重要原因。它包含两个数组:mActiveViews 用于存储当前显示在屏幕上的item,mScrapViews 用于存储已经不可见的item。
ListView 自己是没有覆写 onLayout 方法的,这个方法在父类 AbsListView 中实现。第一次 layout 操作:此时ListView 中还没有任何子 View,接着自顶至底填充ListView,这个填充过程首先尝试获取一个 active view,不过此时还没有缓存任何 active view,于是只能通过Adapter 的 getView 获取view(此时convertView 是空的,只能创建);之后,调用 addViewInLayout 将这个view 添加到 ListView ,将第一屏加载完成后,这个getView 动作就会停止。
第二次Layout:如果layout执行两次的话,那么ListView 就会存在一份重复的数据了。其实第二次layout的过程中,也会去获取 active view ,不过这时候有数据了,有view了,这时候首先执行 detachAllViewsFromParent ,将ListView 中所有的item 都清除掉,detach掉,从而保证第二次 layout 过程中不会产生一份重复数据。由于这些清除掉的item 在 active view 中会有缓存,所以不会重新执行 inflate 过程。之后又重新获取active view ,获取到再 attachViewToParent 就再次添加到 ListView 中。这样经历了 detach 又 attach 过程,ListView 所有子View 就显示出来了。
在滑动的时候,不可见的view会 detach 之后回收到 mScrapViews 中。滑动展示新的item的时候,会从 mScrapViews 废弃的view中获取一个view,再调用 Adapter.getView ,并且将获取到的废弃 View 当做 convertView 传过去,接下来就是我们在 adapter 中常用的写法了。
因此,整个Listview 中总共只有那么几个固定的 item ,滑动的时候就这几个 view 在倒腾(detach 和 attach),因此不论数据量多大,都不会导致oom。
以上内容参考自郭霖的博客
30、android 5.0, 6.0, 7.0, 8.0新特性
点击看答案
5.0
- Meterial Design
- ART 虚拟机
6.0
- 动态权限申请
- 移除了 Http Client 库
- Dozen 模式
如果用户未插接设备的电源,在屏幕关闭的情况下,让设备在一段时间内保持不活动状态,那么设备就会进入低电耗模式。在低电耗模式下,系统会尝试通过限制应用访问占用大量网络和 CPU 资源的服务来节省电量。它还会阻止应用访问网络,并延迟其作业、同步和标准闹钟。
参考官方文档
7.0
- 多窗口支持(分屏模式)
- JIT/AOT 交叉编译(取一个平衡,节约磁盘占用)。
8.0
- 画中画
- Notification 引入 channel 概念,必须设置
- TextView 自动调整文字大小
9.0
- 刘海屏支持
- 多摄像头支持
Q
- 折叠设备
- 深色主题
31、如何导入外部数据库
点击看答案
把原来数据库的文件放在 res/raw 目录下。
我们知道Android系统下数据库应该存放在 /data/data/(packageName)/ 目录下,我们所要做的就是把已有数据库传入那个目录下。操作方法是用FileInputStream 读原数据库,再用FileOutputStream 写入到那个目录。
以上内容参考自: 如何导入外部数据库
32、Android 消息屏障
点击看答案
Handler 中的Message 可以分为三类:同步消息、异步消息 以及消息屏障(消息屏障也是一种消息,只不过target为null)。同步屏障可以通过 MessageQueue.postSyncBarrier 函数来设置(该方法是私有方法,需要反射调用,新的api 貌似提供了public 的 postSyncBarrier方法):
1 | private int postSyncBarrier(long when) { |
乍一看,这里就是往MessageQueue 中放入了一个Message ,和Handler 的post 及postDelay 一样,但是我们知道,Handler 的post 或者postDelay 时,Message 的target 字段会引用这个Handler,而设置同步屏障的时候,没有设置target字段。
异步消息和普通消息一样,Message 中 setAsynchronous(true) 操作了。而通过 MessageQueue 的next() 获取需要处理的 Message 时,有没有target 会是截然不同的处理方式:
1 | Message next() { |
如果碰到没有 target 的 msg ,则会一直遍历是否有异步的消息,如果有,则马上处理,可以说设置了同步屏障后,Handler 只会处理异步消息(在达到目标后,要求手动调用 MessageQueue.removeSyncBarrier 来移除屏障)。
当messageQueue 中没有msg 或者最早的一个 msg 都要在一段时间之后执行,那么如果直接让线程空转有点浪费,在这个时候,系统会去调用这个IdleHandler 接口回调(如果有的话),如果上述代码返回false,说明只需要执行一次,在执行完了之后,将会被remove掉;如果返回true,则认为会执行多次。
使用场景:Android系统中存在Vsync 消息,主要负责 16ms 更新一次屏幕展示,如果同步消息在16ms内没执行完成,就会出现掉帧,用户感觉卡顿。假如在 Vsync 消息加入 MessageQueue 时前面还有 10个同步消息,每个消息执行10ms,那么总共也需要100ms ,这段时间会丢掉很多帧,为了解决这种排队等候,可以使用同步屏障+异步消息。如 ViewRootImpl 的 scheduleTraversals 方法就是这样:
1 | void scheduleTraversals() { |
以上内容参考自Handler之同步屏障机制、Android 源码分析 - Handler的同步屏障机制、同步屏障的使用示例可以参考Android中异步消息和同步屏障
33、引申-IdelHandler
点击看答案
通过以下代码可以添加IdleHandler (注意是Looper.myQueue,而不是Looper.myLooper:
1 | //getMainLooper().myQueue()或者Looper.myQueue() |
结合消息屏障中列出的代码可知,如果在 queueIdle 方法中返回false,则在方法执行完成之后,这个 IdleHandler 将会被移除,即只执行一次;如果return true,则会多次执行。
IdelHandler 的常用场景有:1、延迟执行:当Activity 启动时,需要延时执行一些操作,以免启动过慢,我们通常使用postDelay的方式执行,但是这个delay的时间不太好把握,这时候用 IdelHandler 会更优雅。 2、批量任务,只关心最终结果,例如开发im应用,通常情况下每收到一个消息都会刷新一下ui,短时间内收到多个消息,就会刷新多次界面,容易造成卡顿,影响性能,这时候可以通过子线程监听im消息,通过IdelHandler 刷新ui是比较理想的。
以上内容参考自张小凡凡
34、卡顿之-BlockCanary 原理
点击看答案
卡顿可以使用 BlockCanary 去监测,它需要你自己指定超时的阈值,超过这个阈值就展示出来。我们只知道这个功能,但是它的原理是啥呢?我们可以首先看下 Looper 的源码:
1 | /** |
我们整个进程就只有一个主线程,主线程只有一个 mainLooper ,所以不管多少Handler 与主线程相关,最终都会让这个 mainLooper 来处理,我们再来看下 mainLooper 处理事务的逻辑:
1 | public static void loop() { |
这个 Printer 类型的 mLogging,在每个 Message 处理前后都调用了一遍,printer 流程卡住了,不就是主线程卡住了吗?而我们只需要执行以下代码:
Looper.getMainLooper().setMessageLogging();
就可以设置自己自定义的 Printer ,这样当卡顿发生时,就能感知了。
以上内容参考自 BlockCanary作者的博客
35、Android 跨进程通信之 Binder
点击看答案
Linux 内核提供了丰富的进程间通信机制,如 管道(pipe)、信号(signal)、消息队列(Message)、共享内存(Share Memory) 以及 Socket 等。——摘自《Android系统源代码分析》
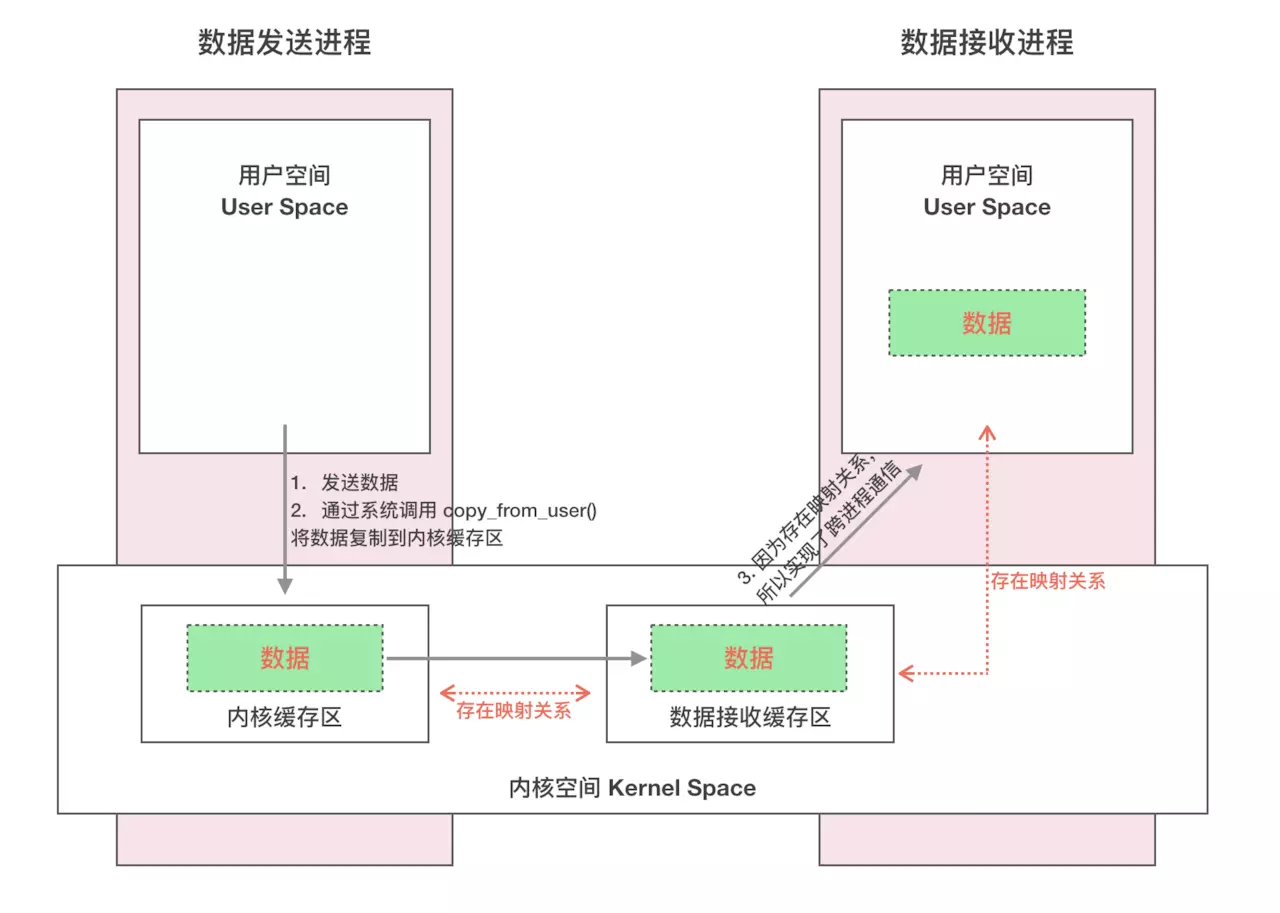
Android 中使用 Binder 进行多进程间通信只需要一次数据拷贝,效率上仅次于共享内存。Binder IPC 机制通过 mmap() 内存映射实现,内存映射简单讲就是将用户空间的一块内存区域映射到内核空间。Android 中Binder 进程间通信示意图如下:
Binder 通信中的代理模式
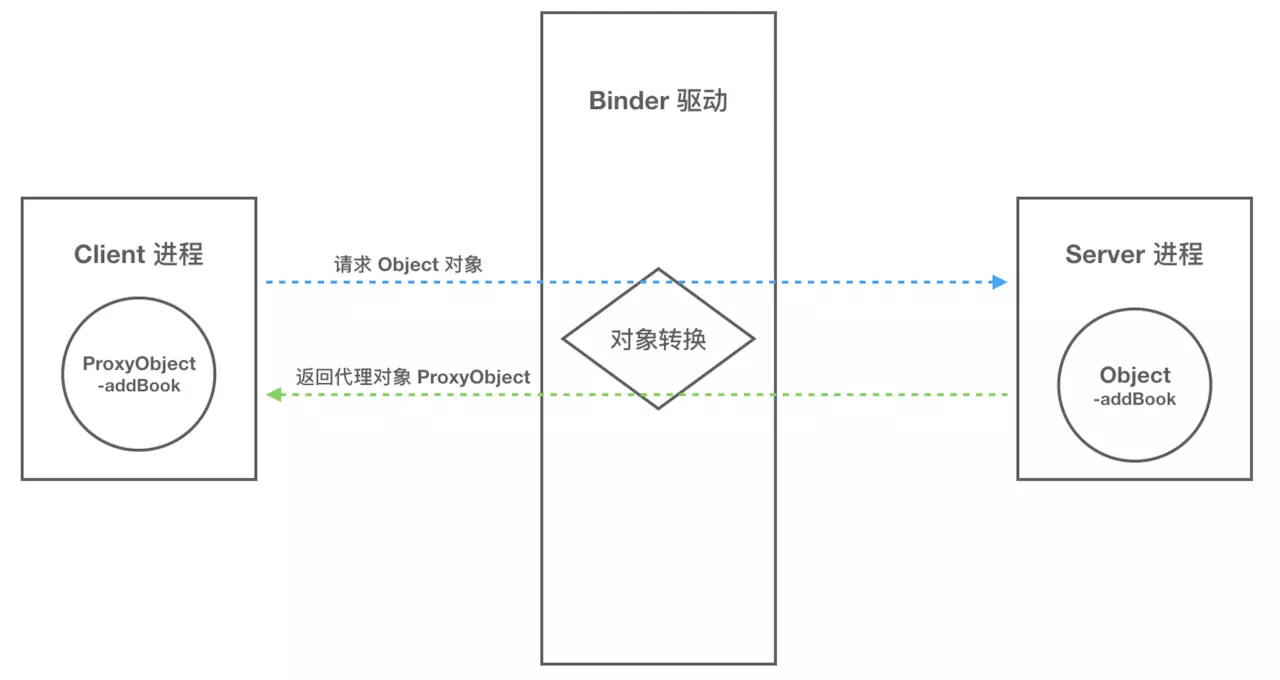
我们已经解释清楚 Client、Server 借助 Binder 驱动完成跨进程通信的实现了,但是还有问题让我们困惑:A进程想要B进程中某个对象(object) 是如何实现的呢?毕竟分数不同的进程,内存地址映射规则也不一样,A进程没法直接使用B进程中的object。
其实,数据流经过Binder驱动都会左一层转换。当A进程想要获取B进程中的object 时,驱动并不会真的把 object 返回给 A,而是返回一个与 object 看起来一样的代理对象 objctProxy,这个 objctProxy 有object 的所有方法,但是这些方法没有 objct 方法中的那些能力,这些方法的主要工作就是将请求参数交给 Binder 驱动,而对于A进程来讲,就和直接调用 object 对象一样一样的。
当Binder 驱动收到 A 进程的消息后,发现是 objctProxy ,接着查询自己维护的表单,发现它是B进程 object 的代理对象,于是就通知B进程调用 object 的指定方法,并要求将结果返回自己。之后Binder 驱动将结果转发给A进程,一次通信就完成了。具体通信过程如下图所示:
多进程通信方式选择
如果想进程间通信,但是无需多线程,可以使用 Messenger;如果需要进程间通信,并且还需要再服务中处理多线程,那就使用AIDL(其实Socket也是能实现的)。
顺带一提:App实现多进程有很多弊端,比如:静态和单例会失效(不是同一规则的内存映射)、sharedPreference 会不可靠 等
以上内容参考自Android进程间通信
36、事件分发
点击看答案
参考以前的事件分发专题 即可。
37、所谓的Android 开发高手课
点击看答案
Bitmap
bitmap 是烧内存大户,3.0~7.0中会将bitmap对象和像素数据统一放到Java堆中,不过还是会引起大量gc甚至导致oom。将Bitmap 内存放到Native 中可以做到和对象一起快速释放,Android 8.0 中提供 NativeAllocationRegistry 帮助将bitmap 放到 native 内存,同时还能满足与对象一起回收。
ANR
首先看主线程的堆栈,查看是否因为锁等待导致。接着看 ANR 日志中的 iowait、CPU、GC、systemt server 等信息,进一步确定是否是 io 问题,或者是 CPU 竞争问题,还是由于大量 GC 导致卡死。从 Logcat 中能够看到当时系统的一些行为,比如出现 ANR 时,会有 “am_anr”,App被kill 时,会有 “am_kill”。
Serializable
- 整个序列化过程使用了大量的反射和临时变量,而且在序列化对象的时候,不仅会序列化当前对象本身,还需要递归序列化对象引用的其他对象
- 因为存在大量反射和 GC 的影响,序列化的性能会比较差。另外一方面因为序列化文件需要包含的信息非常多,导致它的大小比 Class 文件本身还要大很多,这样又会导致 I/O 读写上的性能问题
- Parcel 序列化和 Java 的 Serializable 序列化差别还是比较大的,Parcelable 只会在内存中进行序列化操作,并不会将数据存储到磁盘里。
参考自别人的博客
38、Android 中大图加载
点击看答案
一般为了尽可能避免OOM,图片加载都会按照如下做法:
- 如果仅仅只需要读取大图的尺寸和类型,那我们没必要将其加载到内存,在解码的时候,指定 BitmapFactory.Options 中的inJustDecodeBounds 属性设置为true即可,这样避免为bitmap 分配内存,但是能读到图片的尺寸和类型。根据图片的大小以及ImageView 的大小,我们可以配置 BitmapFactory.Options.inSampleSize 来确定加载到内存中图片的大小。
- 对于图片显示,根据需要显示图片空间的大小对图片进行压缩显示(我们是提交给后台的链接中拼接了所需要的尺寸)
- 如果图片非常多,则会使用 LruCache 等缓存机制,将所有图片占据的内容维持在一个范围。详情可以参考郭霖的博客
但是,还有一种情况,如果单个图片非常巨大,并且还不允许压缩(如清明上河图、世界地图等),那么我们可以使用 BitmapRegionDecoder 来实现。
BitmapRegionDecoder 的原理是:给定一个矩形区域(Rect),然后通过 Bitmap bitmap = mDecoder.decodeRegion(mRect,opthions) 方法来获取这个区域的 bitmap 展示。因此我们大图展示过程中,都是一次次分割实现的。
39、关于Android绘制
点击看答案
原理
60帧的画面让人感觉不到画面的更新,因此Android系统中基本上是 60帧/s的刷新频率,也就是每16ms 发出一次 VSYNC信号触发对UI的绘制。当然,我们要明白,这个 16ms 不只是全用来绘制界面,而是会包括layout、measure。
整体的过程就是,cpu执行计算任务,即 layout、measure后将ui计算成多维图形(多边形、纹理),再经过OpenGL处理,之后交给GPU 进行栅格化后显示在屏幕上。 因此,16ms的时间主要被两件事情占用,第一件:将UI对象转换为一系列多边形和纹理;第二件:CPU传递处理数据到GPU进行栅格化
Frame Buffer中的数据是怎么来的
GPU 从Frame Buffer 中获取数据绘制,但其除了 Frame Buffer 外,还有缓冲的Back Buffer ,GPU 也会定时地切换这两个 Buffer 的角色(可能其中一个为Frame Buffer,另一个就为 Back Buffer),由于16ms 发出一次 VSYNC 信号,因此这个切换也是 16ms。
在系统将Back Buffer 交给应用填充数据时,实际过程是将 Back Buffer 锁定,讲一个指向它的引用交给你的应用,这个引用就是Canvas对象,View的onDraw 方法中接收到的Canvas就是它。我们知道,父view在onDraw的时候,会一直调用子View的onDraw方法,这个Canvas 就会一直传递下去给每一个View。当所有的View 都通过Canvas 绘制完成后,才算完成了一帧的绘制。
丢帧是怎么发生的
上面说GPU 会定期交换 Back Buffer 和 Frame Buffer ,但是有一个例外情况,当你的应用正在往 Back Buffer 中填充数据时,系统会将 Back Buffer 锁定,如果到了 GPU 交换两个Buffer 的时间点,你的应用还在往Back Buffer 中填充数据,GPU 会发现 Back Buffer 被锁定了,它会放弃这次交换(即发生Jank了),导致的结果就是手机屏幕仍然显示原来的图像,即用户在32ms内看到的是同一帧。
开发者如何避免
可以从两个方面考虑:
- CPU产生的问题:不必要的布局和失效
- GPU产生的问题:过度绘制(overdraw)
1、避免cpu 计算任务过重。1、减少在onDraw 方法中创建对象,尤其是复杂对象。 2、减少视图层次,尽量使用ConstrainLayout 等代替多层嵌套
2、避免cpu、GPU 任务过重,减少不必要的View的invalidate 调用(不invalidate可以让gpu最大限度使用缓存)
3、减少过度绘制。1、clipRect帮助识别可见的区域。2、去除View 中不必要的background,因为许多background 并不会显示在最终的屏幕上。比如ImageView,假如它现实的图片填满了空间,你就没有必要给它设置一个背景色。
40、屏幕尺寸变化适配有什么手段
点击看答案
- 使用 match_parent、wrap_content 等方式藐视控件大小
- 使用宽度限定符,如 layout-w600dp
- 屏幕方向限定符,如 layout-land、layout_port 来适配横竖屏
- 使用Fragment,将界面组件化
- 使用.9图片
41、像素密度
点击看答案
为了保证在密度不同的屏幕上看起来尺寸相同,必须使用密度无关的像素(density-independent pixels,简称 dp 或者 dip) 作为单位。1dp 是以中密度屏幕(像素密度(dpi,每平方英尺上的像素个数):160dpi)作为基准密度,在基准上1dp = 1px。不过在定义文本时,应该使用可缩放像素(scalable pixels,简称: sp)作为单位。默认情况下,dp 与sp大小相同,但是当用户在设置中调整文本大小时,sp就会变化了。还有,要注意的是,我们平时说的屏幕的尺寸是指的屏幕对角线长度。
以上内容参考自官方文档
42、彻底理解android 应用无响应机制
点击看答案
首先总结下ANR发生的情况以及阈值:
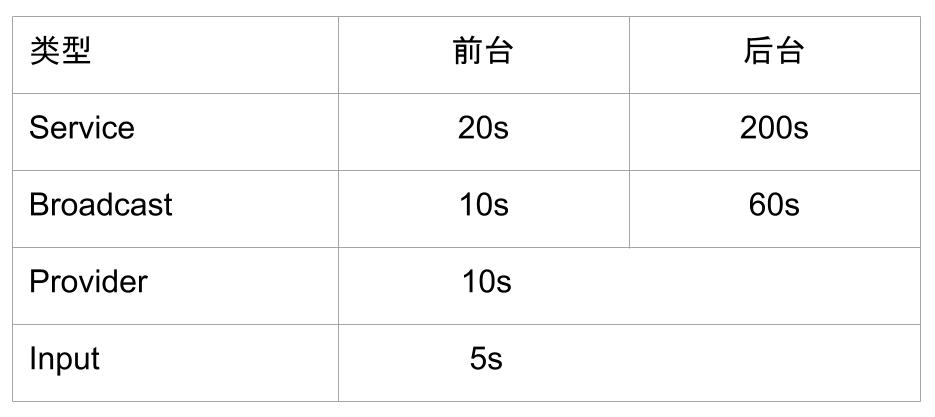
ANR的原理基本上都是执行某项操作task之前,通过Handler 发送一个延时 Message,如果在延时时间到达之前 task 执行完成,则通过handler removeMessage 将Message 移除,否则,在延时时间到达之后还未能完成,Handler 便会处理这个message,从而抛出ANR。尤其需要注意的有以下几点:
- 通过静态注册的广播(动态广播不用考虑)在完成前会检查 SharedPreference 是否已经完成同步到磁盘,如果没有,要等其完成才能告知系统已经完成。
- Provider 只有在进程首次启动的时候才会检测ANR,当provider 进程已经启动,再次请求provider 不会触发超时。
- Activity 退出也会检查 sp 是否已经同步到磁盘,未完成的话,也会等待。
回答有哪些路径会导致ANR
从handler 发送了 message 到 removeMessage 之前的任何一个环节都可能出现ANR,比如:service 的回调方法慢,比如主线程的消息队列存在耗时消息让service 的回调迟迟得不到执行,可能是sp操作缓慢,可以是system_server 进程的binder 线程繁忙,而导致 removeMessage 没来得及执行,也有可能是广播在等待sp操作,等等。
ANR 避免
- 主线程尽量只做UI相关操作,避免耗时操作,如过度绘制、IO操作
- 避免主线程与工作线程发生锁竞争
- 谨慎使用SharedPreference
以上内容参考自gityuan的博客、gityuan博客
43、为什么要使用Binder 机制进程间通信
点击看答案
Linux现有的IPC 方式
管道:信息复制2次。在创建时分配一个page大小的内存,缓存区大小比较有限;
消息队列:信息复制2次。额外的CPU消耗;不合适频繁或信息量大的通信;
共享内存:无须复制,共享缓冲区直接付附加到进程虚拟地址空间,速度快;但进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决;
套接字(Socket):信息复制2次。作为更通用的接口,传输效率低,主要用于同机器或跨网络的通信;
信号量:常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
信号: 不适用于信息交换,更适用于进程中断控制,比如非法内存访问,杀死某个进程等;
为什么采用Binder(从5个维度)
总结下:从性能的角度、从稳定性的角度、从安全的角度、从语言层面的角度、从公司战略的角度
- 从性能的角度:从拷贝次数看,仅次于共享内存。但是共享内存会遇到进程同步,太复杂。
- 从稳定性的角度:Binder 基于 C/S 架构,清晰明了,Client 端与Server 端相对独立。
- 从安全的角度:传统的Linux IPC 只能由用户在数据包里填入UID/PID,接收方无法获得对方进程可靠的 UID/PID ,从而无法鉴别对方身份。而Android 为每个安装好的应用都分配了自己的UID。此外,C/S架构有利于Server端根据UID鉴别访问权限。
- 语言层面:Binder 这种面向对象的思想与Android 开始的开发语言 Java 高度契合。
- 公司战略: 公司战略层面就不多说了
另外,Linux没有采用Binder 不是他们没想到,而是Binder 更适合Android这种手持设备而已。
以上内容参考自gityuan的csdn
44、Binder 机制
点击看答案
而一般的进程间通信方式(共享内存除外),需要Client端进程空间拷贝到内核空间,再由内核空间拷贝到Server进程空间,会发生两次拷贝。
Binder 进程间的高效率通信的秘诀在于 binder_mmap() ,如下图示意:
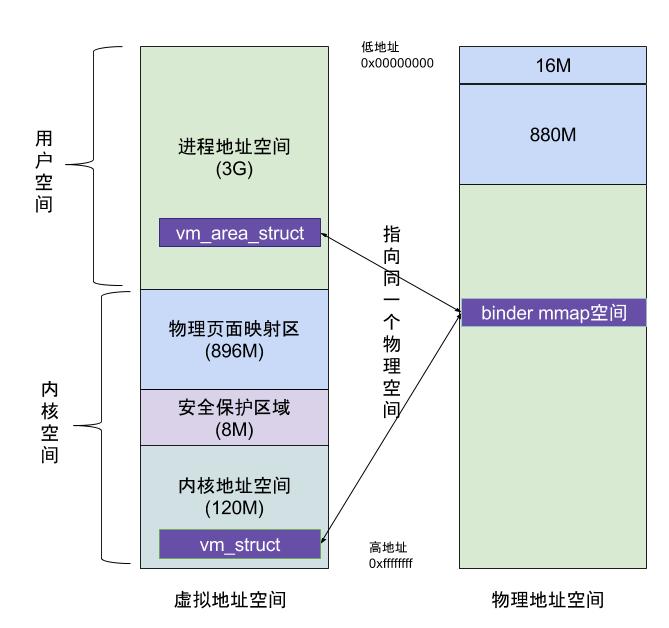
虚拟进程地址空间(vm_area_struct)和虚拟内核地址空间(vm_struct)都映射到同一块物理内存空间。当Client端与Server端发送数据时,Client(作为数据发送端)先从自己的进程空间把IPC通信数据copy_from_user拷贝到内核空间,而Server端(作为数据接收端)与内核共享数据,不再需要拷贝数据,而是通过内存地址空间的偏移量,即可获悉内存地址,整个过程只发生一次内存拷贝。
进程和内核虚拟地址映射到同一个物理内存的操作是发生在数据接收端,而数据发送端还是需要将用户态的数据复制到内核态。
下图展示了通过Binder 进行进程间通信:
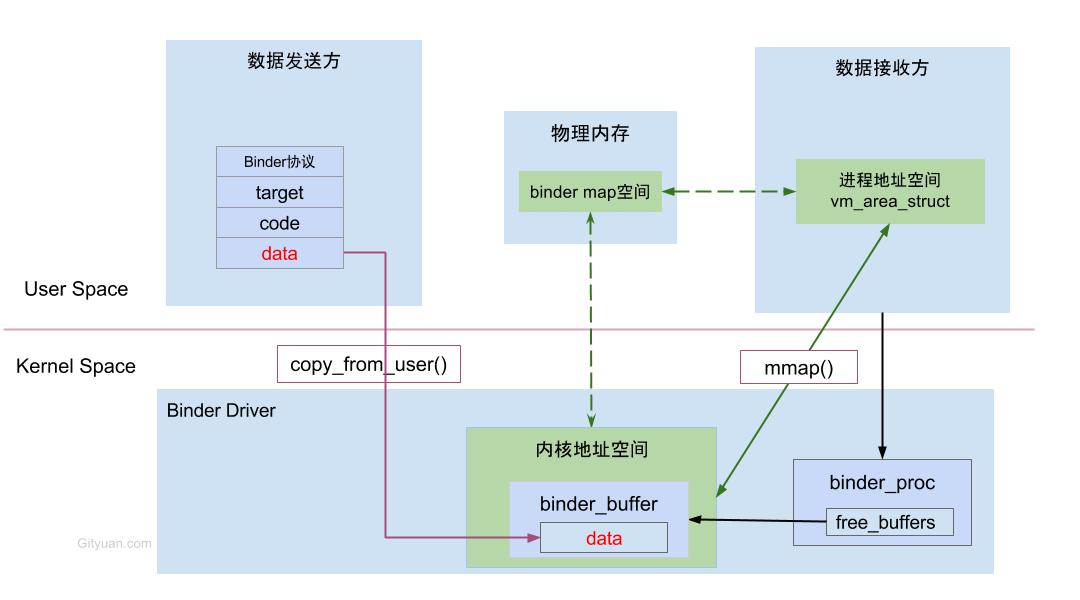
我个人理解,client 与server 双方都有进行 mmap 映射操作,但是在用户空间获取到的映射空间只能读,不能写。这样,双方发送数据时都只需要执行 copy_from_user 即可,在接收端通过地址偏移就能获取到数据
从universus的博客(据说这篇博客是介绍binder的神级存在)能看出来确实两端都有映射。
以上内容参考自gityuan的博客
45、动画
点击看答案
帧动画、View 动画(补间动画)、属性动画
- 帧动画就一帧帧播放
- View动画:指定开始状态和结束状态,中间的view会自动被补齐,主要支持 平移、缩放、透明度、旋转 四种基本效果。主要应用场景: view的动画 以及 Activity、Fragment 的切换动画。注意:View 动画执行到某个位置时,它的动作响应(比如点击)还停留在原来位置的,只有点击原来位置才有效,因为它不是真正改变View的属性。
- 属性动画:真正的视图移动,点击移动后的视图会有效果。
以上内容参考自会飞的鱼
46、关于Android绘制
点击看答案
原理
60帧的画面让人感觉不到画面的更新,因此Android系统中基本上是 60帧/s的刷新频率,也就是每16ms 发出一次 VSYNC信号触发对UI的绘制。当然,我们要明白,这个 16ms 不只是全用来绘制界面,而是会包括layout、measure。
整体的过程就是,cpu执行计算任务,即 layout、measure后将ui计算成多维图形(多边形、纹理),再经过OpenGL处理,之后交给GPU 进行栅格化后显示在屏幕上。 因此,16ms的时间主要被两件事情占用,第一件:将UI对象转换为一系列多边形和纹理;第二件:CPU传递处理数据到GPU进行栅格化
Frame Buffer中的数据是怎么来的
GPU 从Frame Buffer 中获取数据绘制,但其除了 Frame Buffer 外,还有缓冲的Back Buffer ,GPU 也会定时地切换这两个 Buffer 的角色(可能其中一个为Frame Buffer,另一个就为 Back Buffer),由于16ms 发出一次 VSYNC 信号,因此这个切换也是 16ms。
在系统将Back Buffer 交给应用填充数据时,实际过程是将 Back Buffer 锁定,讲一个指向它的引用交给你的应用,这个引用就是Canvas对象,View的onDraw 方法中接收到的Canvas就是它。我们知道,父view在onDraw的时候,会一直调用子View的onDraw方法,这个Canvas 就会一直传递下去给每一个View。当所有的View 都通过Canvas 绘制完成后,才算完成了一帧的绘制。
丢帧是怎么发生的
上面说GPU 会定期交换 Back Buffer 和 Frame Buffer ,但是有一个例外情况,当你的应用正在往 Back Buffer 中填充数据时,系统会将 Back Buffer 锁定,如果到了 GPU 交换两个Buffer 的时间点,你的应用还在往Back Buffer 中填充数据,GPU 会发现 Back Buffer 被锁定了,它会放弃这次交换(即发生Jank了),导致的结果就是手机屏幕仍然显示原来的图像,即用户在32ms内看到的是同一帧。
开发者如何避免
可以从两个方面考虑:
- CPU产生的问题:不必要的布局和失效
- GPU产生的问题:过度绘制(overdraw)
1、避免cpu 计算任务过重。1、减少在onDraw 方法中创建对象,尤其是复杂对象。 2、减少视图层次,尽量使用ConstrainLayout 等代替多层嵌套
2、避免cpu、GPU 任务过重,减少不必要的View的invalidate 调用(不invalidate可以让gpu最大限度使用缓存)
3、减少过度绘制。1、clipRect帮助识别可见的区域。2、去除View 中不必要的background,因为许多background 并不会显示在最终的屏幕上。比如ImageView,假如它现实的图片填满了空间,你就没有必要给它设置一个背景色。
47、Kotlin 优势
点击看答案
按照官网上的说法:
- 简洁。
判空、getter、setter 方法、命名传参(动态改变参数)无需重载,可能结合anko 之类的更加简单
- 安全
减少空指针等错误、类型判断过后,自动类型转换
- 兼容java
可以混编
48、多进程 webview
点击看答案
想着app只有一个 Cookies 的 db 文件,估摸着跨进程的 webview 能共享这个cookie数据。今天试了试,结果发现俩问题:
- 加上跨进程后,在一加6上(Android 10 系统)运行崩了,但是在魅族15上(Android 7.1.1系统)运行良好
- 主进程webview 的cookies 正常,但是新进程的webview 加载 cookies 缺失。
很奇怪的是,通过 adb shell ,run-as com.esun.ui ,获取app_webview 中的 Cookies 文件用sqlite3 打开,里面的 cookies 一条条又是正常的!初步断定是同步的问题,因为只有一个db文件,不可能不一样。
至于,一加手机不能正常使用,是因为Android P及以上的版本不支持从多个进程使用具有相同数据目录的Webview,官方的解决方法就是给不同进程的Webview 设置不同的数据目录(在Application中):
1 |
|
49、无需root,获取应用在/data/data{packageName}/里面的数据
点击看答案
在debug 包情况下,我们可以在未经授权的情况下获取 /data/data{packageName}/ 目录下的数据,比如:Cookies 的db 文件(虽然没有db后缀,但是就是个db文件)、SharedPreference 的xml 文件等。具体步骤:
- 执行 adb shell
- run-as {包名} ,例如: run-as com.example.haha
- 这时候 ls 命令能看到我们 app 在/data/data/ 目录下的所有文件了
如果需要将 Cookies 文件拷贝到电脑桌面的话,我们需要先将其拷贝到sd卡上:
- 首先,拷贝到sd卡上: cp app_webview/Cookies /sdcard/
- 其次,退出 shell 模式,执行: exit (多次执行,直到回到初始状态)
- 最后,使用adb pull 命令将文件拉出来
如果需要查看这个Cookies 的db 文件,可以使用以下指令即可查看:
sqlite3 /home/sample/Desktop/Cookies
.dump cookies
50、签名
点击看答案
APK Signature Scheme v1
解压一个签名后的 APK ,在 META-INF 目录下会有三个文件: MANIFEST.MF、CERT.SF、CERT.RSA。它们就是v1签名的关键。
其中,MANIFEST.MF存储了APK中的每个文件的文件名和摘要,类似如下形式(上面是文件名,下面是文件的 SHA256 消息摘要之后进行 Base64编码):
Name: AndroidManifest.xml
SHA-256-Digest: bWeqbdj+sLYqFQPe/j3kjv7hGZZYFm+YheK2AwGnW90=
CERT.SF 称为二次摘要文件。它的格式和 MANIFEST.MF 的一样,也是上面name,下面摘要,只不过摘要是对 MANIFEST.MF 中的摘要条目做摘要(对MANIFEST.MF摘要条目进行SHA-256摘要再base64处理,值得注意的是,CERT.SF中存储了 MANIFEST.MF 整个文件的 摘要值):
Name: AndroidManifest.xml
SHA-256-Digest: bQWn4Jvp6bjlQUQQ8cr1NO9nl9hrMXMTbVeXGULZwSI=
最后,CERT.RSA 文件与 CERT.SF 文件是相互对应的,二者的名字一样,它里面主要存储了证书的公钥、过期日期、发行人、加密算法、CERT.CF文件的签名(使用私钥对CERT.CF文件的签名)等。
从以上信息我们知道,使用不同的keystore进行签名时,除了 CERT.RSA 文件外,其余两个文件都是一样的。也就是说前两者主要保证各个文件的完整性,而 CERT.RSA 用来保证apk的来源即完整性。
v1 签名校验过程
- 检查apk中的文件对应的摘要值是否与 MANIFEST.MF 记录的一致
- 使用 CERT.RSA 文件检验签名文件 CERT.SF 文件是否被修改过
- 使用 CERT.SF 校验 MANIFEST.MF 文件是否被修改过
为什么这个顺序呢?假设一下,如果你改了apk的文件,那么在安装apk文件时,第一步通过 MANIFEST.MF 校验不通过;假如你改了文件重新计算摘要值,更新了 MANIFEST.MF 文件,那么必定与 CERT.SF 文件中计算的值不一样。最后的保障是
v1的缺点
- META_INF文件不在校验范围内,很容易绕过
- 单个文件的完整性校验在安装的时候比较耗时
APK Signature Scheme v2
v2签名不是针对单个文件,而是将apk分成 1M 大小的块,对每个块计算摘要(由于块摘要可以并行处理,因此可以提高校验速度),之后对所有摘要进行摘要得到顶级摘要,之后利用私钥对顶级摘要签名得到数字证书(即得到数字证书)。如下图所示:
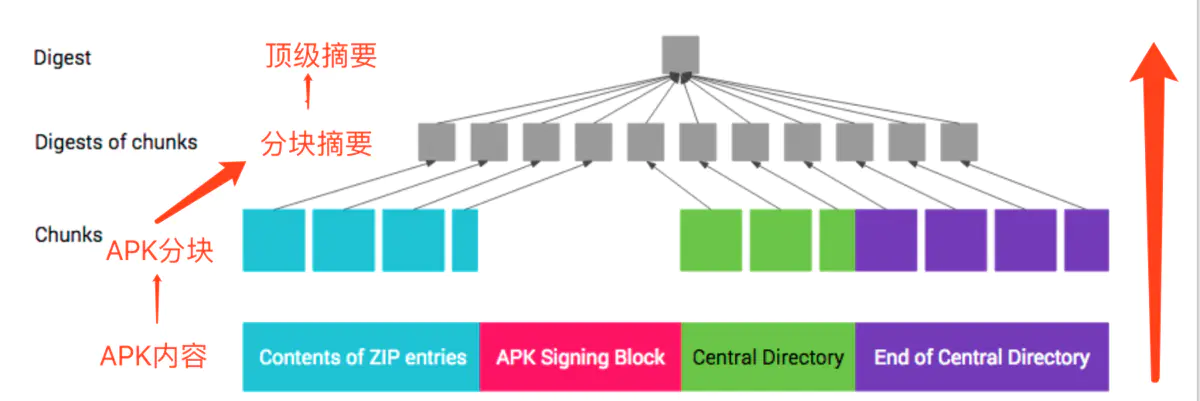
为了保护 APK 内容,整个 APK(ZIP文件格式)被分为以下 4 个区块:
- ZIP 条目的内容(从偏移量 0 处开始一直到“APK 签名分块”的起始位置)
- APK 签名分块
- ZIP 中央目录
- ZIP 中央目录结尾
可以看到,Android签名存放区域是zip文件的中央目录(central Directory)之前。v2对整个apk签名,因此如果需要对齐(zipalign)的话,必须先对齐后签名。
51、浅谈TouchDelegate的坑与用法
点击看答案
用于扩大点击区域
以上内容参考自简书
52、BitMap 内存管理
点击看答案
Android 2.3.3即更低版本
无需使用bitmap 的时候,调用其 recycle() 方法
Android 3.0 及更高版本
引入了 BitmapFactory.Options.inBitmap 字段,如果设置了此字段,那么采用 Options 对象的解码方法会在加载内容时尝试重复使用现有位图。不过,使用会有一些限制,尤其是4.4以前,仅支持大小相同的位图的复用。
原理:当Bitmap 从 LruCache 删除时,对其的软引用会防止在HashSet 中,以供之后通过 inBitmap 重复使用。
以上内容参考自官方文档
53、epoll
点击看答案
epoll机制提供了Linux平台上最高效的I/O复用机制,它的主要作用是I/O复用,即在一个地方等待多个文件句柄的I/O事件。
epoll的效率为什么比 select/poll高呢?有以下几个原因:
1、每次调用select 时,需要把感兴趣的事件都复制到内核中,二epoll 只在epll_ctl 进行加入操作的时候才复制一次
2、epoll内部用于保存事件的数据结构使用的是红黑树,查找速度很快,二select采用数组保存信息,不但一次能等待的句柄有限,并且在事件较多时查找起来速度很慢
以上内容参考自《深入理解Android:卷II》
54、杂
点击看答案
系统有个 framework-res.apk ,这个APK 除了包含资源之外,还包含一些Activity(如关机对话框) ,这些Activity 实际上运行在 system_server 进程中,从这个角度看,system_server 是一个特殊的应用进程
LoadedApk 用于保存一些和 APK 相关的信息(如资源文件位置、JNI 库位置等)
ActivityThread 中包含一个mLooper 成员,代表一个消息循环。mServices 用于保存 Service ,Activityes 用于保存 ActivityClientRecord,mAllApplications 用于保存 Appkication (注意,我们获取 ApplicationContext 的时候,首先从 LoadApk 中获取,没成功再从 ActivityThread 中获取)。
55、BroadCastReceiver
点击看答案
我们知道,在 BroadCastReceiver 的onReceive 中不能执行耗时操作,但是如果我们有这个需求的时候,怎么办呢?其实,如果这个处理比较耗时,可以采用异步的方式处理: 即先调用 BroadCastReceiver 的 goAsync 方法得到一个 PendingResult 对象,然后将该对象放到工作线程中处理,可以参考的代码如下:
1 | public void onReceive(final Context context, final Intent intent) { |
Sticky 的广播,一旦有接收者注册,系统马上将该广播传递给它们。
动态注册的非order广播,在 sendBroadcast 的时候,可以直接发送,不需要等待上一个Receiver 接收处理完成后才发送下一个。而静态注册的广播,则必须处理完一个接收者才能处理下一个接收者。这是因为需要避免惊群效应,动态广播的接收者的进程是肯定存在的(如果不存在肯定没法注册),而静态注册的广播接收者不能保证它已经和进程绑定了(进程可能还没启动),假如发送广播时,这些接收者进程都不存在,那么一下子就创建了多个进程,系统压力陡增。每次处理一个的recevier的坏处在于延时较长。
以上内容参考自《深入理解Android:卷II》
56、证书校验
点击看答案
主要是为了更进一步的安全,防止通过 fiddler 抓包
crt格式的证书保存在assets文件夹中,同时,也可以从后台获取证书,保存在sp文件中,从后台获取证书时,需要将tag(标记客户端当前已有证书的版本,由于本地默认在assets文件夹中有证书,所以默认也有个tag)传过去,如果tag为空,则后台肯定返回证书,否则,判断客户端不是最新证书的情况会返回最新证书。马上判断证书中是否包含请求证书这个接口的host,包括才算成功。如果asset中的证书未失效,那么下载的证书就下次使用;反之,得后台的证书下载下来马上就使用。通过 CertificateFactory 将crt文件格式的证书转换成 x.509 格式的对象,之后,对比本地证书的公钥和服务端返回的公钥的值是否一致来决定证书是否校验通过。
有个细节,获取证书的这个接口请求是通过ip请求的(首先通过 114 或者 119 获取host 的ip),然后将真正的host设置在 header 中,在从后台下载到证书后,验证证书里面是否包含有这个接口的host,包含了才算通过。
57、RecyclerView与ListView的区别
点击看答案
1、局部刷新。RecyclerView 可以局部刷新,而ListView不可以
2、ListView的ViewHolder 需要自己定义,并且不是强制要求的;而RecyclerView 是已经封装好了,是强制的
3、ListView 的Adapter 继承的是 BaseAdapter;RecyclerView 的Adapter 继承的是 RecyclerView.Adapter
4、ListView可以设置分割线;RecyclerView 只能自己些DecodeItem
5、ListView 可以针对Item直接添加点击事件,RecyclerView只能自己写回调
6、ListView的显示方式没有RecyclerView灵活,后者可以使设置成瀑布流、竖直的、横向的,网格的
7、缓存机制不同,缓存层级
58、BitmapFactory.Options 用于 Bitmap 内存优化
点击看答案
Options 的成员变量挺多的,类似 inBitmap、inMutable、inJustDecodeBounds、inSampleSize、outWidth、outHeight、outConfig… ,看规律可以发现有 in 和 out 两类命名风格,in 开头可以理解为设置参数,out开头可以理解为获取某些参数。
通过正确使用上述参数,可以很好操作 Bitmap ,减少资源滥用,减少Bitmap的内存占用。
通过 inJustDecodeBounds 获取图片信息
如果仅仅需要获取图片信息而不要实际使用 Bitmap ,可以为 Options 设置 inJustDecodeBounds 为 true,这样 bitmap 返回的是 null,但却可以获取图片的宽高等信息。
通过 inSampleSize 降低采样
很多时候,我们所需要的图片比原图小,这时候可以设置 inSampleSize 来减小图片宽高,当彩艳率(inSampleSize) > 1 时,长和宽对应变为原来的 1 / inSampleSize ,对应的 bitmap 也缩小为原来的 1/(inSampleSize^2)。同时强调解码器使用(我个人的理解,此处指的是inSampleSize)基于2的幂的最终值,任何其他值都将被舍入到最接近的2的幂次,示例代码如下所示:
1 | public class TestBitmapSize extends AppCompatActivity { |
通过 inBitmap 重用 Bitmap 内存复用
当需要多次重复创建 Bitmap 的时候,可以考虑使用 inBitmap 实现 Bitmap 的重用。
Bitmap 的复用的前提是,前一个 Bitmap 是可变的 mutable,即我们在设置 BitmapFactory 中 Options 的时候,inMutable 参数设置为true,之后,把前一个 bitmap 设置给 Options的 inBitmap,在后续的 Bitmap 创建时,如果也是使用同一个Options 的话,可以做到复用了。示例代码如下:
1 | // 测试bitmap复用 |
以上内容参考自CSDN上的博客
59、ListView 和 RecyclerView
点击看答案
如何选择
如果我们需要频繁地刷新列表数据且列表数据需要添加动画或者列表数据相差不太大的话,还是使用 RecyclerView,对于前后数据相差不大的情况,还可以使用 DiffUtil 来进行差分,这样,就能实现定向刷新和局部刷新。
除此以外,还是建议使用ListView ,不仅仅分割线之类的方便,它还有很多便捷的Adapter,CursorAdapter、ArrayAdater 等。
60、RecyclerView的缓存机制
点击看答案
RecyclerView 缓存ViewHolder 有4个等级,优先级从高到低有4个层次:
- mAttachedScrap: 缓存屏幕中可见范围的ViewHolder
- mCachedViews: 缓存滑动时即将与RecyclerView 分离的 ViewHolder,存有postion信息,如果需要复用,直接可以拿过去用,不需要改变数据。默认最多2个
- ViewCacheExtention: 用户自定义的扩展缓存,需要用户自己管理View的创建和缓存。
- RecycledViewPool:缓存池。在 mCacheViews 中缓存已满时,就会将旧的ViewHolder 放到RecyclderViewPool,如果 RecyclderViewPool 满了,就不会再缓存。从这里取出的缓存需要bindView 才能使用(本质上是一个SparseArray,其中key是ViewType(int类型),value存放的是 ArrayList< ViewHolder>,默认每个ArrayList中最多存放5个ViewHolder)。
61、到底在哪个阶段存储数据
点击看答案
官方文档说在Android 3.0 以后,应用只有等到 onStop 之后才能被杀死,官方还建议,应当在onPause方法中存储那些持久性的数据,比如用户输入等,onSaveInstanceState 将在Activity 转入后台状态之前被调用,能让我们存储一些Activity 的动态的状态值(比如组件的宽高之类的)到Bundle对象中,onSaveInstanceState 方法在onStop 方法之前调用,但是它跟onPause 回调没啥关系,但是还有一点要注意的是:onSaveInstanceState 并不是Activity的生命周期中的回调方法之一,所以,在Activity 被杀死的时候,不能保证百分百执行的!
所以,个人总结以上的内容,
- 如果要100%可靠,就要在onPause 中保存数据(一般就是保存在sp当中)
- onPuase 中保存持久化的数据,比如用户输入
- onSaveInstanceState 一般建议保存Activity的动态状态值(比如组件宽高)、允许丢失的数据
以上内容参考CSDN文章
62、如果不给view设置id,会对状态保存有什么影响?
点击看答案
首先看focus:
1 | // save the focused view id |
再看View的保存:
1 | protected void dispatchSaveInstanceState(SparseArray<Parcelable> container) { |
可以看出,如果没有设置id,那么在在Activity调用 onSaveInstantceState 时,就没法保存它的状态到SparseArray中(这个SparseArray再保存到Bundle中),并且,如果当前它是焦点View,也没办法将焦点状态保存到 记录在 Bundle 中。
但是,如果同类的view,在使用相同的id时,在取状态值的时候,就可能会出现问题,比如:你在应用中使用两个ScrollView,且都指定一样的id,那么在onSaveInstanceState时,后调用的那个则会覆盖掉之前的那个ScrollView的Scroll的值,导致在之后取出的时候,会让两个ScrollView的滑动进度总是一样。
以上内容参考自CSDN
63、adb工具有哪些主要功能
点击看答案
1、常见的可能就是adb install、adb uninstall
2、通过 adb pull 从手机拉取文件,或者 adb push
3、常用的adb功能就是 dumpsys 的功能,比如 activity、meminfo、电池、cpu安装包信息
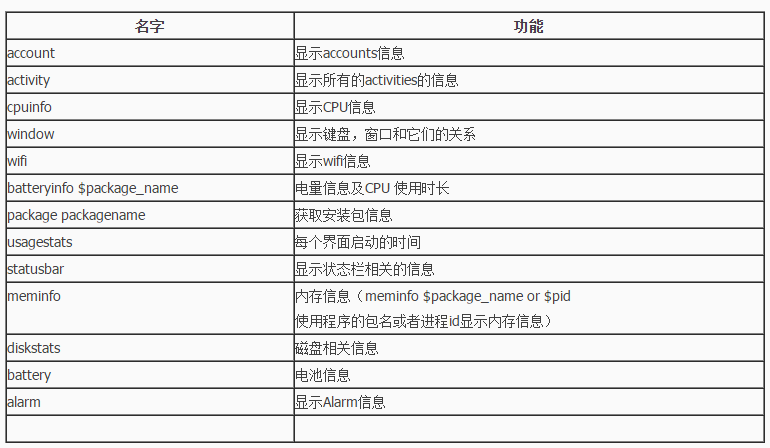
4、 adb shell ,很大的一个命令,run-as 可以在debug状态查看应用的存储空间
以上内容参考自csdn的博客
64、Android与 JS 通过 Webview 交互
点击看答案
这个交互其实就是Android 与 JS 互相调用的过程,即: 1)Android 调用 JS 代码;2) JS 调用Android代码
Android调用 JS 代码
- 通过Webview 的 loadUrl()
- 通过 Webview 的 evaluateJavascript()
示例如下:
1 | // html 文件 |
Android 端调用:
1 | public class MainActivity extends AppCompatActivity { |
两种方法比较:
| 调用方式 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| loadUrl | 方便 | 效率低,获取返回值麻烦 | 不需要获取返回值,对性能要求低 |
| evaluateJavascript | 效率高 | Android 4.4 以上才可用 | Android 4.4以上 |
注意,js代码调用一定要在 onPageFinished() 回调之后才能调用,否则不会调用
JS 调用 Android 代码
- 通过 Webview 的 addJavascriptInterface()
- 通过 WebViewClient 的 shouldOverrideUrlLoading 方法拦截 url
- 通过 WebChromeClient 的 onJsAlert()、onJsConfirm()、onJsPrompt() 方法回调拦截 JS 对话框 alert()、confirm() 、prompt() 消息
其中,addJavascriptInterface 方式和 shouldOverrideUrlLoading 拦截方式就不提了,主要比较下第三种:
| 方法 | 作用 | 返回值 | 备注 |
|---|---|---|---|
| alert | 弹出警告框 | 无 | 在文本加入\n可换行 |
| confirm | 弹出确认框 | 两个返回值 | 返回 布尔 值 true表示确认,false 表示取消 |
| prompt | 弹出输入框 | 任意设置返回值 | 点击“确认”,返回输入框中的值,点击取消,返回null |
以上内容参考自 简书上的博客
65、Webview 缓存及预加载方案
点击看答案
Webview 存在的问题
- 页面资源加载缓慢,H5页面的资源会比较多,并且,请求都是串行的
- js 解析渲染慢
- 产生很多的网络请求,耗费流量
解决方案
其他的都先不说,我个人感兴趣的是自身构建缓存:
- 事先将更新频率较低、常用 或 固定的 H5 静态资源文件(如 JS、CSS文件、图片等)放到本地
- 拦截 H5 页面的资源网络请求,并进行检测
- 如果检测到本地具有相同的静态资源,就直接从本地读取进行替换,而不发送该资源的网络请求到服务器
具体实现:重写 WebViewClient 的 shouldInterceptrRequest 方法,当向服务器访问这些静态资源是进行拦截,检测到是相同的资源,则用本地资源替代:
1 | // 假设现在需要拦截一个图片的资源并用本地资源进行替代 |
这里可以参考文中的例子写一下
以上内容参考自简书上的博客
66、远程执行漏洞
点击看答案
漏洞描述
Android API level 16 及以前的版本存在远程代码执行安全漏洞,该漏洞源于程序没有正确限制使用 WebView.addJavascriptInterface 方法,远程攻击者可以通过使用 Java Reflection API 利用该漏洞执行任意 Java 对象的方法。简单地说就是通过 addJavascriptInterface 给 Webview 加入一个 JavaScript 桥接口,JavaScript 通过调用这个接口可以直接操作本地的 Java 接口。
漏洞执行原理
我们平常使用 addJavascriptInterface 为 webview 提供一个 java 对象,供其与 Java 端通信:
1 | mWebView = new WebView(this); |
但是,如果web页面并不干正经事,那么它就可以利用反射机制调用 Android API getRunTime 执行 shell 命令!看代码:
1 | <html> |
此外,还能执行很多类似这样的操作,比如打电话、发送短信、安装木马 Apk等。
解决方案
API Level = 17 的Android系统
在高版本上,这个漏洞已经被修复,只有添加了 @JavascriptInterface 注解的方法才能被调用了。所以,在这个版本层次,我们只需要记得添加这个注解即可。
API Level <= 17 的Android系统
这就不建议使用 addJavascriptInterface 接口,以免带来不必要的安全隐患。如果一定要用,请注意:
- 如果采用 https ,应进行证书校验防止访问的页面被篡改挂马
- 如果使用 http 协议,应进行白名单过滤、完整性校验等防止页面被篡改
- 如果加载本地html,应将html内置在Apk中,以进行完整性校验
移除Android系统内部的默认内置接口
Android 系统中 webkit 中默认内置的一个 searchBoxJavaBridge_ 接口同时存在远程代码执行漏洞,建议开发者移除:
1 | removeJavascriptInterface("searchBoxJavaBridge_"); |
以上内容参考自腾讯云上的博客
