1、Java 多态
点击看答案
多态存在的三个必要条件:一、要有继承关系 二、要重写方法 三、父类指向子类对象。
多态就是指允许不同类的对象(如:父类的多个子类),对同一消息做出不同响应(同一个函数调用在不同子类中的行为不同)。
多态的实现:动态绑定(dynamic binding),即在执行期间判断所引用的对象的实际类型,根据实际类型再调用相应方法。
Java 中多态的表现:接口的实现、继承父类进行方法重写 以及 同一个类中进行方法重载。
以上内容参考自: Java多态
Java集合
2、ArrayList 与 LinkedList的区别
点击看答案
ArrayList的特点:
- 以数组实现,初始空间是10,节约空间
- 有容量限制,当超出限制时,新增50%容量,即容量变为原来的1.5倍,如果还不够,则直接扩充为需求值,之后将原来数据拷贝到新的空间中,比较耗时
- 按照数组下标访问元素——get(i)/set(i,e) 性能很高
- 按照下标插入、删除元素,需要移动受影响的元素,性能就会变差(remove操作可以理解为删除index为0的节点,并将后面的元素移到0处)
LinkedList的特点:
- 以双向链表实现,链表无容量限制,但是双向链表本身使用了更多空间
- 按下标访问元素——get(i)/set(i,e),要遍历链表将指针移动到位(如果i>链表的一半,会从末尾开始移动)
- 插入、删除元素时,只需要修改前后节点的指针即可。但如果是指定位置插入和删除,则还是需要遍历部分链表的指针才能移动到下标所指的位置。如果只是在链表两头的操作就能省掉指针的移动。
参考链接:ArrayList、LinkedList)
3、HashMap
点击看答案
根据官方描述,HashMap 基于 Map 接口实现,允许null 键/值,非同步、不保证有序(比如插入顺序)、顺序可能会随时间变化。
两个重要的参数
容量(Capacity)就是bucket大小,负载因子(Load factor)就是bucket填满程度的最大比例。若对迭代性能要求高,则capacity不宜设置过大,同时load factor也不宜设置过小;当buckets的数目大于 capacity * load factor 时,就需要调整buckets 的大小为当前的2倍。
hashMap的put函数实现
- 对key的hashCode 做hash,然后计算index;
- 如果没有碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets 后;
- 如果碰撞导致链表过长,达到某个阈值后,则把链表转换成红黑树;
- 如果节点已经存在,就替换 old value (保证key的唯一性);
- 如果bucket满了,就要resize;
- 注意,插入元素采用头插法,因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。
get函数的实现
- bucket里第一个节点,则直接命中;
- 如果有冲突,则通过 key.equals(k) 方式去查找对应的 entry。
若为树,则树中通过key.equals查找,时间复杂度为 O(logn);
若为链表,则链表中通过key.equals查找,时间复杂度为 O(n)。
hashmap细节
- hashmap的初始长度是16,并且手动初始化或者每次自动扩展时,长度必须是2的幂。
这里主要强调是2的幂,至于为什么是16,主要是为了让key到index的映射更加均匀。前面提到,index = Hash(key) ,如何实现一个尽量分布均匀地hash函数。有人说可以通过求余的方式: index = hashCode(key) % length ,不过求余的方式虽然简单,但是效率不高,Hashmap中采用了位运算方式,其公式为:
index = hashCode(key) & (length - 1)
以具体例子来说,假如某个key 的 hashCode(二进制) = 101110001110101110 1001,hashmap的默认长度length = 16 ,则 length - 1 为15,二进制数据为 1111,把两个二进制数据做位与操作得到 1001,即十进制的 9 ,所以index = 9。所以这里,index的结果完全取决于hashCode的最后4位(当然,java8中,会将这个hashCode的高16位不变,低16位和高16位做异或操作作为低16位的值,之后才与 length -1 做位与,这样避免只有低4位是有效位,从而进一步降低碰撞,因为参与的位数多了)。
所谓为什么要是2的幂,也即如果不是2的幂会怎样?比如hashMap的长度是 10,还是以上面的例子:hashCode(二进制) = 101110001110101110 1001,length - 1 = 9 ,即 1001,则index 也还会是1001(因为hashCode的后4位也是1001),单独看这里没什么问题,但是从此我们可以推断:如果hashCode的后 4 位是 1001、1101、1111,1101等等,它们的结果都会是 1001,因为相当于只有第1位和第4位在起作用,这不符合index均匀分布的要求。那如果是2的幂呢?则length - 1后,所有的位数都是1,则每位都会起作用。
Hashmap的容量是有限的,当容量达到一定的饱和度的时候,Key映射位置发生碰撞的概率会上升,这好理解,因为如果每个坑都差不多有entry在了,无论你index是多少,都会碰撞,所以元素越多,越容易发生碰撞。java中的条件是 : hashmap.size >= capacity * load factor 的时候,就需要resize,需要经历两个步骤,1、扩容,创建一个新的Entry数组,长度是以前的2倍,2、ReHash,遍历原来的 Entry数组,把所有的Entry 重新hash到新的数组,因为数组长度变化了,hash的规则也会改变,所以需要rehash。这里不需要重新计算hash,只需要判断原来的hash值新增的那位是0 还是1,如果是0的话,索引还是没变化,如果是1,则索引变成 “原索引 + oldCapacity”。
举个例子拉说,如果以前的capacity 是 8,则resize后变成16,以前的length - 1 为 111 现在则变成了 1111,多了一个有效位,所以只要判断 hashCode 的对应新增的那位的值是0还是1了,0的话,整个index还是不变,1的话,就在index的基础上加上老的容量 8 即可。
前面提到,key和value都可能为null,如果key为null,则直接从哈希表的第一个位置table[0]对应的链表上查找。记住,key为null的键值对永远都放在以table[0]为头结点的链表中。
Hashmap的线程不安全如何体现?
- 如果多个线程同时使用put添加元素,如果发生碰撞,最终只有一个线程值被保存,因为另一个的会被覆盖。
- 由于resize操作存在,hashmap在多线程的情况下,可能会出现死循环,具体参考:小灰的解释
参考链接: 知乎链接、hashmap介绍链接
4、HaShMap 链表元素到达8的时候转红黑树的若干问题
点击看答案
首先,得满足两个条件才会转红黑树:一个是链表长度到8,一个是数组长度到64
为什么到8才转成红黑树?首先根据统计节点数>=8概率是很小的(千分之一),并且到8的时候,会引起性能下降,且因为转红黑树消耗性能,所以到 8 才转。
会根据红黑树状态以及红黑树节点总数到6这个阈值来将红黑树退回链表,这主要是是因为 8 和 6 这两个数字相差2,不至于插入删除一个元素导致来回转换
为什么不一开始就采用红黑树?因为红黑树是有额外的空间开销的,并且红黑树涉及左旋右旋等操作(我自己臆测的,也没看到有好的说法)
以上问题参考自hashmap转红黑树的两个条件 、HashMap的问题、cnblogs的博客、
5、HashTable
点击看答案
HashTable 类似于HashMap ,它同样基于hash表实现,每个元素也是key-value 对,也是通过单链表解决冲突,容量不足时,也会resize,二者区别是:
- HashTable 的key和Value 都不能为null,而HashMap允许。
- HashTable 默认大小是 11,扩容方式是 old*2 + 1,而HashMap 默认大小是16,要求数组大小是2的幂,扩容时,直接扩为2倍。
- 获取index的方式不一样,Hashtable 采用除余的方式,而HashMap采用 位与的方式,效率更高。
- HashTable 保证方法调用的线程安全,因为在每个方法前都有synchronize 关键字。而HashMap 没有,因此在线程安全条件下效率更高。
上文的参考链接
6、ConcurrentHashMap
点击看答案
想要避免HashMap 的线程安全问题有很多办法,比如采用 HashTable 或者 Collections.synchronizedMap ,但是这两者有共同的问题:性能,因为无论是读还是写操作,它们都会给整个集合加锁,导致同一时间的其他操作阻塞。如下图所示:
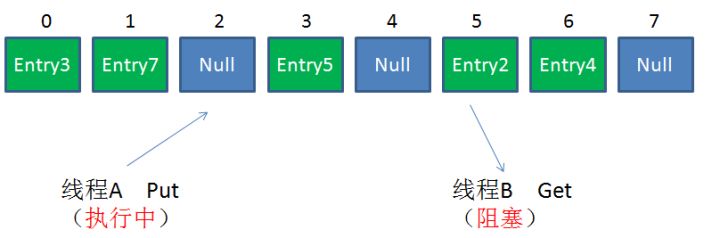
此时,ConcurrentHashMap应运而生,理解 ConcurrentHashMap 关键要理解一个概念: Segment 。Segment 本身就相当于一个 HashMap 对象,Segment 包含一个HashEntry 数组,数组中每个 HashEntry 既是一个键值对,也是一个链表的头结点,如下图所示:
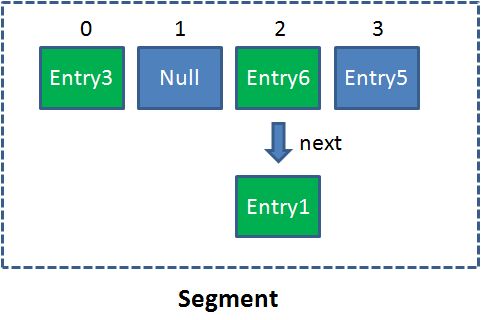
这样的Segment 在ConcurrentHashMap 中有2 的N 次方个,共同保存在一个名为 segments 的数组中。因此,整个 ConcurrentHashMap 的结构如下:
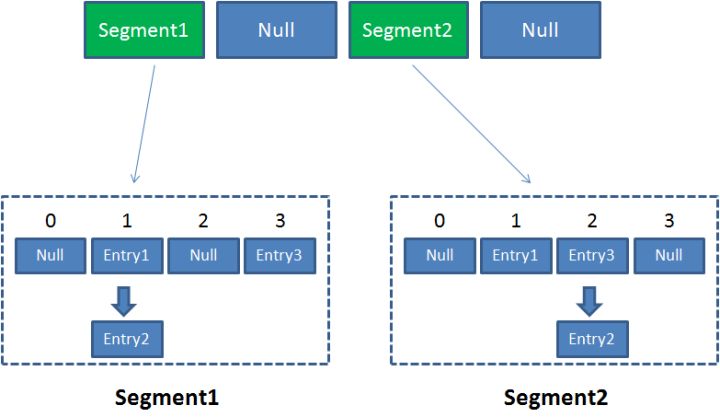
这个二级结构,和数据库的水平拆分有些相似。采取这样的结构就是锁分段技术,每个segment 就好比一个自治区,读写操作互不影响。所以,ConcurrentHashMap 操作会有以下几种可能性:
- 不同Segment 可以并发写入。
- 同一 Segment 可以同时读和写。
- 同一个 Segment 并发写入时,只有一个线程可以执行,其他的线程阻塞。因为 Segment 的写入会加锁。
通过以上分析我们知道,ConcurrentHashMap 中每个 Segment 各自持有一把锁。在保证线程安全的情况下,降低了锁的粒度,让并发操作效率更高。
get 方法
- 为输入的key做 Hash 运算,得到hash值。
- 通过hash值,定位到对应的 Segment 对象。
- 再次通过 hash 值,定位到 Segment 中数组的具体位置。
put 方法
- 为输入的key 做Hash 运算,得到hash 值。
- 通过hash值,定位到 Segment 对象。
- 获取可重入锁。
- 再次通过 hash 值,定位到 Segment 当中的具体位置。
- 插入或者覆盖 HashEntry 对象。
- 释放锁。
size 方法
获取 ConcurrentHashMap 总元素数量,自然要把各个 Segment 的元素汇总起来,但是如果在统计过程中,已经统计过的 Segment 瞬间插入新的元素,这时候怎么办呢?其实,这个size调用过程的大体逻辑如下:
- 遍历所有 Segment。
- 把 Segment 的元素数量累加。
- 把 Segment 的修改次数累加起来。
- 判断所有Segment 的总修改次数是否大于上一次的修改次数,如果大于,说明统计过程中有修改,重新统计,同时尝试次数 +1;否则,说明没有修改,统计结束。
- 如果尝试次数超过阈值,则对每一个Segment 加锁,再重新统计。
- 此时,统计的结果肯定正确,统计结束,释放锁。
为了尽量不锁住所有的Segment ,首先乐观假设Size过程中不会有修改,当尝试一定次数后,才无奈转换为悲观锁。
以上文章参考小灰的分析
7、HashMap 、 HashTable 和 ConcurrentHashMap 的区别?
点击看答案
HashTable 是 HashMap 的线程安全实现,但是 HashTable在竞争激烈时效率低下,因为访问所有 HashTable 的线程都竞争同一把锁。ConcurrentHashMap 采用锁分段技术,将数据一段段存储,每段一把锁,当两个线程访问不同段数据时不受干扰,当然,contentValue和size等方法需要了解整体数据的情况下,还需要锁住整个表。
8、LinkedHashMap
点击看答案
LinkedHashMap 是Hash表和链表的实现,并且保存了记录的插入顺序。因为LinkedHashMap里面的Entry比HashMap多了两个字段:after和before,而以前的HashMap中的next 字段没有变化,从而额外构成一个双向链表,当然就可以在keySet()时按插入顺序输出,LinkedHashMap结构如下图所示:
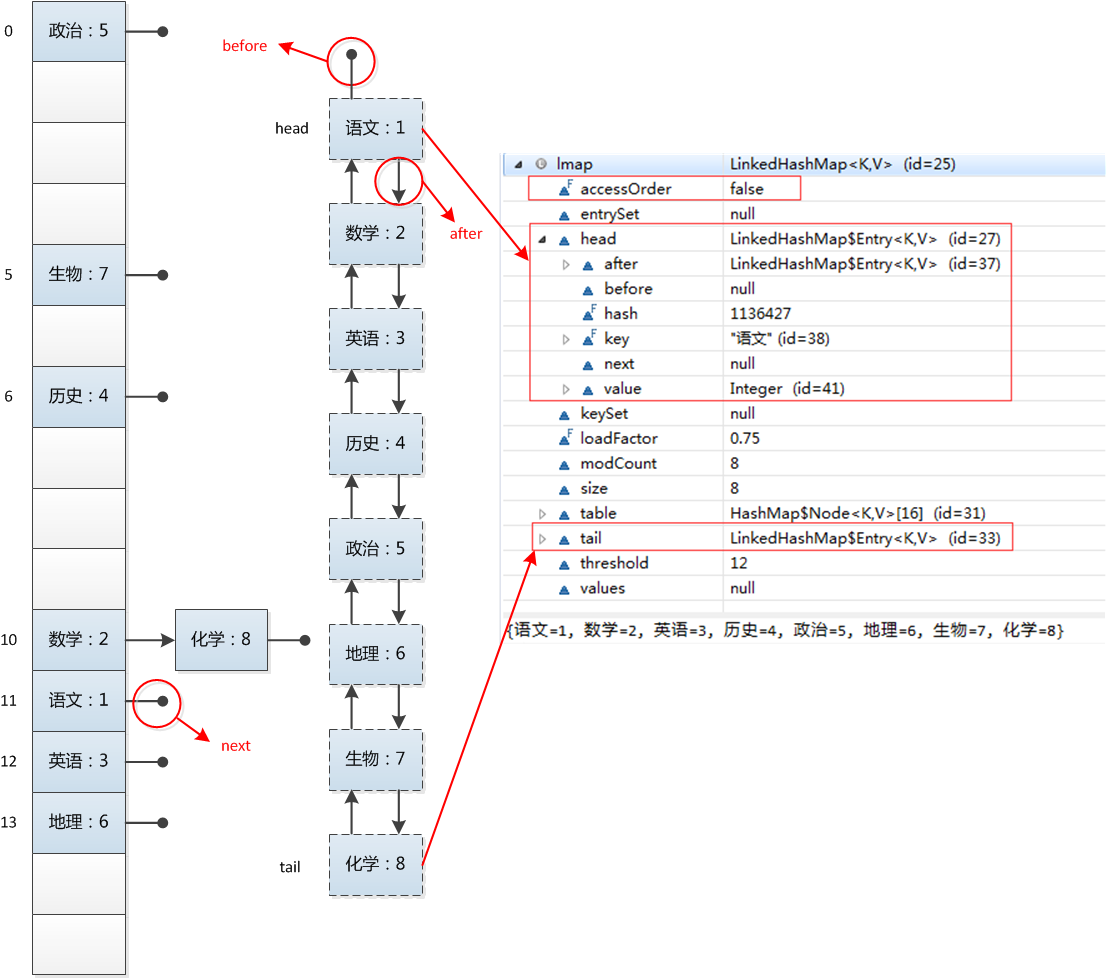
与HashMap的区别:1、保存了记录的插入顺序,遍历的时候,首先打印最先插入的记录。2、遍历的时候比HashMap慢,因为LinkedHashMap 遍历链表,而HashMap可以说是根据capacity 遍历链表。不过如果HashMap容量很大并且实际数据比较少的情况下,遍历起来可能比LinkedHashMap慢。3、HashMap的遍历速度和容量有关,而LinkedHashMap 遍历速度只和实际数据有关。
9、WeakHashMap
点击看答案
WeakHashMap,从名字可以看出它是某种 Map。它的特殊之处在于 WeakHashMap 里的entry可能会被GC自动删除,即使程序员没有调用remove()或者clear()方法。
更直观的说,当使用 WeakHashMap 时,即使没有显示的添加或删除任何元素,也可能发生如下情况:
- 调用两次size()方法返回不同的值;
- 两次调用isEmpty()方法,第一次返回false,第二次返回true;
- 两次调用containsKey()方法,第一次返回true,第二次返回false,尽管两次使用的是同一个key;
- 两次调用get()方法,第一次返回一个value,第二次返回null,尽管两次使用的是同一个对象。
遇到这么奇葩的现象,你是不是觉得使用者一定会疯掉?其实不然,WeekHashMap 的这个特点特别适用于需要缓存的场景。在缓存场景下,由于内存是有限的,不能缓存所有对象;对象缓存命中可以提高系统效率,但缓存MISS也不会造成错误,因为可以通过计算重新得到。
以上内容参考 知乎的大神
10、TreeMap
点击看答案
HashMap不保证数据有序,LinkedHashMap保证数据可以保持插入顺序,而如果我们希望Map可以保持key的大小顺序的时候,我们就需要利用TreeMap了。从官方的描述来看:
A Red-Black tree based {@link NavigableMap} implementation.The map is sorted according to the {@linkplain Comparable natural ordering} of its keys, or by a {@link Comparator} provided at map creation time, depending on which constructor is used.
TreeMap 是一个红黑树结构,每个key-value都作为一个红黑树的节点。它根据 key 排序(Comparable自然排序),但假如 key 没有实现 Comparable 接口,还可以通过构造函数中传入的 Comparator 来自定义比较。并且它还间接实现了 SortedMap 接口,因此它是有序的集合。
使用红黑树的好处是能够使得树具有不错的平衡性,这样操作的速度就可以达到log(n)的水平了。
关于根据 key 排序这个表述,可能直接看代码更容易懂:
1 | public V put(K key, V value) { |
省略了很多代码,如果有自定义的 comparator,则使用自定义的 comparator 比较;否则,将 Key 强转为 Comparable 类型,再做比较。当然,这个Key肯定不能为null,此外,官方也说明了,如果Key不是 Comparable 类型的,就会抛出 ClassCastException 异常。
以上文章参考java集合-TreeMap、oschina链接 还有这个大牛
11、Java泛型
点击看答案
Java 泛型主要关注几点:
类型通配符
顾名思义就是匹配任意类型。如如下写法:List<?> list ;
带限通配符
上限通配符:使用extends 关键字指定这个类型必须继承某个类或者实现某个接口,也可以是该类(接口)本身。如: List<? extends Shape> ,表示集合中所有元素都是Shape 类型或者它的子类。
下限通配符:使用super 关键字指定这个类型必须是某个类的父类,或者某个接口的父接口,也可以是这个类本身。如:List<? super Circle> ,表示集合中所有元素都是Circle 类型或者是其父类。
类型擦除
Class c1=new ArrayList
().getClass();
Class c2=new ArrayList().getClass();
System.out.println(c1==c2);
输出 true ,也就是说编译后的class文件中不会包含任何泛型信息,泛型信息不会进入到运行时阶段。
由于系统中并不会真正生成泛型类,所以instanceof运算符后不能使用泛型类
以上内容参考自Java泛型
12、Java抽象类和接口的区别
点击看答案
abstract class和interface是Java语言中对于抽象类定义进行支持的两种机制,正是由于这两种机制的存在,才赋予了Java强大的面向对象能力。
abstract class和interface之间在对于抽象类定义的支持方面具有很大的相似性,甚至可以相互替换,因此很多开发者在进行抽象类定义时对于 abstract class和interface的选择显得比较随意。
但是,对于它们的选择甚至反映出对于问题领域本质的理解、对于设计意图的理解是否正确、合理。
总结:
- 设计理念上,接口反映的是”like-a”关系,抽象类反映的是”is-a”关系,即接口表示这个对象能做什么,抽象类表示的是这个对象是什么(想象一下,人可以吃东西,狗也能吃东西,接口反映的是吃东西这个动作,而抽象类能反映的,可能就是人这个物种)。
- 抽象类与接口都不能直接实例化。
- 抽象类被子类继承,接口被子类实现。
- 接口中定义的变量只能是公共的静态常量(即 public static final),抽象类中是普通变量。
- 抽象类中可以没有抽象方法,接口中可以没有方法,但是有方法一定要有抽象方法。
- 接口可以被类多实现(类可以实现多个接口),抽象类只能被单继承。
- 接口中没有this 指针,没有构造函数,不能拥有实例变量或实例方法。
关于接口,再多啰嗦几句:
- 接口用于描述系统对外提供的服务,因此接口中的成员变量和方法都必须公开(public),确保所有使用者能访问。
- 接口仅描述系统能做什么,但不指名如何做,因此所有方法都是抽象(abstract)方法。
- 接口不涉及任何具体实例(this关键字)的相关细节,因此接口没有构造方法,没有实例变量,只有静态(static)变量。
- 接口中的变量是所有实现类公有的,既然公有,肯定是不变的东西,所以变量是不可变(final)的。
通俗讲,你认为是要变化的东西,就放在你自己的实现中,不能放在接口中。接口对修改关闭,对扩展开放,是开闭原则的体现。
以上内容参考自:Java抽象类和接口的区别、程序媛想事
13、Java transient关键字
点击看答案
Java序列化时,transient关键字用于属性前时,该属性就不会被序列化。它的使用可以总结为下面几点:
- 变量被 transient 修饰时,变量将不会是对象持久化的一部分。
- transient 只能修饰变量而不能修饰方法和类,并且也不能修饰本地变量。
- 静态变量不管是否被 transient 修饰,均不能被序列化。
附:父类实现了Serializable,子类没有,
父类有int a = 1、int b = 2、int c = 3
子类有int d = 4、int e = 5
序列化子类的时候,d和e会不会被序列化?(答案:会)
反过来父类未实现Serializable,子类实现了,序列化子类实例的时候,父类的属性是直接被跳过不保存,还是能保存但不能还原?(答案:值不保存)
以上内容参考自:Java transient关键字
14、Java finally与return执行顺序
点击看答案
首先探讨下,try-catch-finally 块中的语句是否一定被执行?答案是否定的,原因有2个:
- 如果try 语句没有被执行(比如在try 之前就return 了),finally就不会执行。
- 如果try 块中有 System.exit(0)这样的终止Java 虚拟机的语句的话,finally就不会执行。这可以理解,连JVM 都停止了,啥都没有了。
关于finally 与return 的执行顺序,过程比较复杂,可以分为如下情况:
- 正常情况下,finally 语句在return 语句执行之后,return 返回之前执行的。
1 | public class FinallyTest1 { |
会输出:
try block
return statement
finally block
after return
可以看出,try 中的return语句先执行了,但是值没有立即返回,等finally执行结束后再返回值。
- 如果finnaly 块中有return 语句会覆盖 try 中的 return 返回。
- 如果finally语句中没有return语句覆盖返回值,那么原来的返回值可能因为finally里的修改而改变也可能不变(int 类型和 Map 类型)。
- try 块里的return 语句在异常情况下不会执行,怎么返回看情况。
以上内容参考自:Java finally与return执行顺序
15、两个对象的 hashcode 相同,是否对象相同?equal() 相同呢?
点击看答案
- hashCode是所有java对象的固有方法,默认返回的是该对象在jvm的堆上的内存地址,不同对象的内存地址肯定不同,所以这个hashCode也就肯定不同了。如果重载了的话,由于采用的算法的问题,有可能导致两个不同对象的hashCode相同。
- hashCode和equals两个方法是有语义关联的,它们需要满足:
A.equals(B)==true –> A.hashCode()==B.hashCode(),但是反之不能说hashcode相等就equals
因此重载其中一个方法时也需要将另一个也重载。- 此外,请注意:hashCode的重载实现最好依赖于对象中的final属性,从而在对象初始化构造后就不再变化。一方面是jvm便于代码优化,可以缓存这个hashCode;另一方面,在使用hashMap或hashSet的场景中,如果使用的key的hashCode会变化,将会导致bug,比如放进去时key.hashCode()=1,等到要取出来时key.hashCode()=2,就取不出来数据了。
综上所述,hashCode相同或者equals相同并不能说明对象相同。
16、延伸-Java 中 hashcode 的作用
点击看答案
官方文档的定义就是:
hashcode 方法返回对象的哈希码值,支持该方法主要是为了支持基于哈希机制的Java 集合类,如HashMap、HashSet、HashTable 等。
hashcode的常规约定是:
Java程序运行期间,同一个对象上多次调用 hashcode ,必须一致地返回相同的整数,而从某一应用程序的一次执行到同一程序的另一次执行,该整数无须保持一致。如果两个对象相等,那么两个对象中的每个对象上调用 hashcode 方法都必须生成相同的整数结果。
以上内容参考自:OUYM
17、延伸-为什么重写了equals 方法,要求必须重写hashcode 方法?
点击看答案
根据前面的内容,总结就是:为了满足常规约定-如果两个equals 满足,就一定要求返回相同的 hashcode。举个例子,如果重写了 equals 方法,对象中 num 和data 参与了equals 比较,那么 num 和data 也要参与生成hashcode,这是为了遵守上述约定。
18、生成hashcode 注意的事项
点击看答案
- 返回的hash值是int型,防止溢出
- 不同对象返回的hash值尽量不同(为了hashmap 等集合减少碰撞)
- 无论何时,对同一个对象调用hashcode()都应该产生同样的值
最后一点是很重要的,也是容易出隐形bug的地方,如果将一个对象put() 到HashMap 时产生了一个 hashcode 值,而 get() 取出时却产生了另外一个hashcode,那么就无法获取该对象了。所以,如果hashcode() 方法依赖于对象中易变的数据,那就要当心了。
以上内容参考自:OUYM
19、下面代码输出的结果?
点击看答案
1 | //题目1 |
20、延伸-类的初始化步骤
点击看答案
没有父类的情况:
- 类的静态属性
- 类的静态代码块
- 类的非静态属性
- 类的非静态代码块
- 构造方法
有父类的情况:
- 父类的静态属性
- 父类的静态代码块
- 子类的静态属性
- 子类的静态代码块
- 父类的非静态属性
- 父类的非静态代码块
- 父类构造方法
- 子类非静态属性
- 子类非静态代码块
- 子类构造方法
以题目深化理解:
1 | public class Singleton { |
上述代码将输出:
counter1 = 1
counter2 = 0
根据类初始化步骤,由于 Singleton 并没有被加载过,所以首先执行类加载步骤,在“准备”阶段,首先给静态变量赋初默认值:
singleton = null
counter1 = 0
counter2 = 0
加载和连接完毕,再进行初始化工作,依照代码写的顺序依次执行,首先执行 singleton = new Singleton();这样就会执行构造方法的内部逻辑,即此时 counter1 = 1; counter2 = 1;
接下来,由于counter1 只进行了定义,并没有初始化,所以counter1的值仍然为1 ;接下来,counter2 进行了定义并且赋值 0 ,则初始化阶段后,counter2 的值为0;
初始化完毕,要调用Singleton.getSingleton() ,由于singleton 的值已经初始化过,此时直接返回即可。因此输出 counter1 = 1,counter2 = 0。
反之,如果将静态变量初始化的顺序改变下:
1 | public static int counter1; |
则会输出 counter1 = 1,counter2 = 1 了,按照上述推理应该能够理解。21、constructor 是否一定要与类名同名,方法名是否一定不能与类名同名?
点击看答案
constructor 是一定要与类名同名的,但普通的类方法是可以和类名同名的,它与构造方法唯一的区别就是构造方法没有返回值。
22、数据溢出与非法数据问题
点击看答案
存在使i + 1 < i的数吗?答案是肯定的,比如i是int 类型,那么当i 是最大的整数时,i+1就溢出了,就可能< i
。
是否存在 i>j || i<= j 不成立?答案是肯定的,比如:Double.NaN 或者 Float.NaN
以上内容参考自程序媛想事
23、Java 的参数传递
点击看答案
在讨论之前,首先看下如下代码的输出情况:
1 | public class Example { |
上述代码输出good and gbc 。在Java 中没有引用传递,只有值传递,这个值指的是实参的地址的拷贝,得到这个值(地址拷贝)后,你可以通过它修改这个地址的内容,因为此时这个内容的地址和原地址是同一个地址,但是你不能改变这个地址本身使其重新引用到其他对象。以上的意思说明仅仅只是值传递。具体过程如果使用图示的话,如下所示:
str的传递:
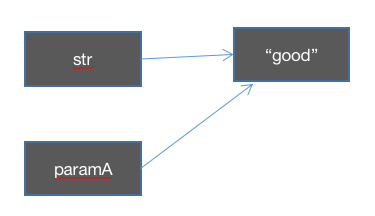
在change方法中重新为paramsA 赋值:
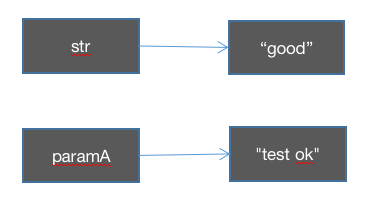
ch的传递:
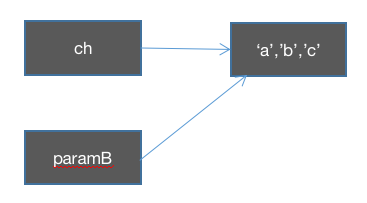
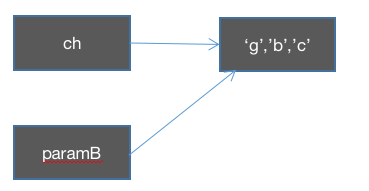
在change方法中更改paramsB 的元素值:
24、静态属性和静态方法是否可以被继承?是否可以被重写?以及原因?
查看以前写的这篇读书笔记即可
25、String、StringBuilder、StringBuffer、CharSequence 区别
点击看答案
CharSequence 是一个接口,String、StringBuilder、StringBuffer 都实现了这个接口,它们三个的本质都是通过字符数组实现的。
StringBuilder、StringBuffer 的char 数组开始的存储空间是16,如果append() 过程中超过这个容量,将会申请新的空间,并把老的数组一起复制过去。
StringBuffer 的每个处理方法都加上了 synchronized 关键字,因此可以说它是线程安全的。
26、Java 中String 为毛要设计成不可变?
点击看答案
为什么说String 是不可变的
首先我们看源码:
1 | public final class String implements Serializable, Comparable<String>, CharSequence { |
类使用final 修饰,说明不可继承;存放内容的 value 是个char[]数组,也是final修饰,创建以后就不可改变。说明一下,这个 value 是stack 上的一个引用,数据本身还是在heap堆上。final 修饰value ,只能是说stack 指向的引用地址是不可变的,但是堆里面的数据本身还是可变的!举例理解下:
1 | final int[] value={1,2,3} |
通过以上代码相信就能理解上面描述的意思了。也许有人还认为String是可以变的,并且举例如下:
1 | String a = "abcd"; |
这其实不是String本身变化,只是变量a指向heap堆的指针发生了变化,而String本身并没有发生变化,示意图如下:
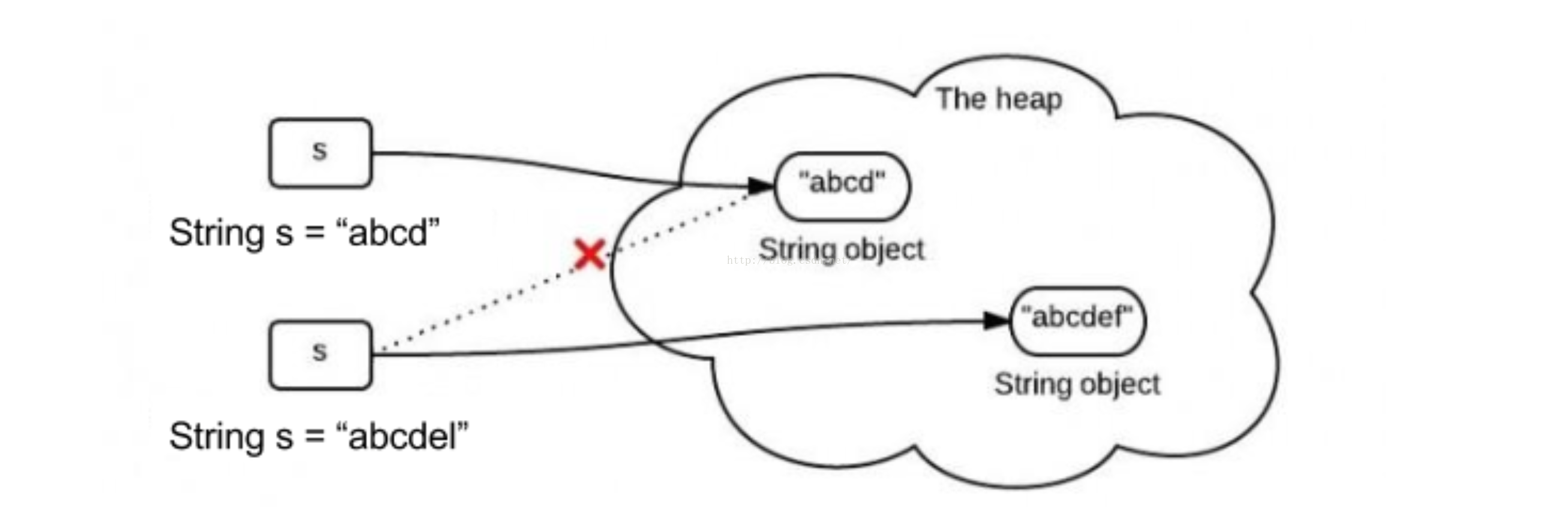
为什么要设计成不可变
首先,先得清楚 final 这个关键字。 final的出现就是为了为了不想改变,而不想改变的理由有两点:设计(安全)或者效率。
- 字符串常量池的需要。String 带有字符串常量池的属性,如果两个字符串one和two都指向 “something” 赋值,它们其实都指向同一个内存地址。这样在大量使用字符串的情况下,可以节省内存空间,提高效率。之所以能实现这个特性,String 的不可变是必要的(如果可变,那么一个改了,所有引用常量池这个string值都会改变)。
- 允许String对象缓存HashCode。String 对象的哈希码被频繁使用,比如在HashMap 中。
- 其次,为了安全。多线程安全:多个线程同时读一个资源,不会引发竞态条件,但是对资源做写操作就会有危险,这样保证String使用线程安全。url、反射所需要的参数等都是String类型,如果允许改变,会引起安全隐患(比如非法访问:如果String可变,那么可以在安全检测后,修改String值,导致非法访问)。
一定是不可变的吗?
由以上内容可知,String 是通过字符数组实现的,这个字符数组被final 修饰,因此不能重新指向其他内存区域,但是,我们可以针对这块内存区域改变值,即改变这个数组里面的内容,比如将 value[0] 的值由 ‘a’ 改成 ‘b’(当然这个过程要通过反射去实现)。
可能令你疑惑的操作方式
我们平日开发通常情况下少量的字符串拼接其实没太必要担心,例如:
String str = “aa”+”bb”+”cc”;
像这种没有变量的字符串,编译阶段就直接合成”aabbcc”了,然后看字符串常量池(下面会说到常量池)里有没有,有也直接引用,没有就在常量池中生成,返回引用。
如果String a = “123”;这种写法是会将 “123” 放入常量池的,但是如果使用 String b = new String(“123”); 则会在堆上分配空间存放。
但是如果:
1 | String str1 = "aaa"; |
则在编译的时候会优化成: StringBuilder sb = StringBuilder(String.valueOf(str1))).append(str2)
如果:
1 | StringBuffer sb = new StringBuffer(); |
则会输出4,因为如果是null的话,则会拼接 “null”。
以上内容参考自:qingmengwuheng1 以及 岚之山
27、成员内部类、静态内部类、局部内部类和匿名内部类的理解
点击看答案
成员内部类
成员内部类定义在另一个类的内部,它是依赖外部类而存在的,也就是说如果要创建内部类的对象,前提是必须存在一个外部类的对象,以下是两种内部类使用情况:
1 | class TestClass{ |
注意代码中典型用法和非典型用法成员内部类对象的创建,说明了内部类对象的创建是依赖于外部类对象的,尤其是: outBean.new InnerBean() 这种写法。
成员内部类可以用private、protected、public 及包访问权限修饰,如果成员内部类被private修饰,则只能在外部内的内部访问;如果使用public修饰,则任何地方都能访问;如果使用protected修饰,则只能在同一个包下,或者继承外部类的情况下访问;如果是默认访问权限,则只能在同一个包下访问。
成员内部类可以无条件访问外部类所有的成员属性和方法(包括private的和static的),不过如果内部类和外部类有相同名称的变量或者方法时,优先访问内部类自己的,如果要访问外部类的可以如下写法:
外部类.this.成员变量(方法)
局部内部类
局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于它的访问尽心阿玉方法内或者作用域内。由于类似于局部变量,所以并不能有 public、protected、private 或者 static 修饰符的。示例如如下代码:
1 | public People getWoman(){ |
匿名内部类
匿名内部类我们使用很多,比如在实现点击监听的时候:
1 | btnOk.setOnclickListener(new OnclickListener(){ |
匿名内部类是为一种没有构造器的类,大部分匿名内部类用于接口回调,一般来说,匿名内部类用于继承其他类或者接口,并不需要增加额外地方法,只是对继承方法的实现或者重写。
静态内部类
静态内部类定义在一个类里面,并且被static 修饰,并不需要依赖于外部类。这点和类的静态成员属性有点类似,并且它不能使用外部类的非static 成员变量或者方法。
深入理解内部类
1、为什么成员内部类可以无条件访问外部类成员?
因为编译器会默认为内部类构造器中添加一个参数,这个参数是外部类对象的一个引用,所以它能直接访问外部内的成员。这也从侧面说明成员内部类为什么要依赖于外部类的对象。
2、为什么局部内部类和匿名内部类只能访问局部final 变量?
我们首先看如下代码:
1 | public void test(final int b){ |
如果把变量a或者b任意一个final 去掉,代码就编译不过。至于为什么,我们首先考虑一个问题:当test 方法执行完成后,变量a的生命周期结束了,而Thread对象的生命周期可能还没结束,那么在Thread的run方法中继续访问a就实现不了了,但是又要实现这样的效果,怎么办?Java中采用了 复制 手段来解决,也就是将a复制到Thread对象中。
也就是说,如果局部变量的值在编译期间就能确定,则直接在匿名内部类中创建一个拷贝;如果局部变量的值无法再编译期间确定,则通过构造器传参的方式来对拷贝进行初始化赋值
内部类的场景和好处
- 每个内部类都能独立继承一个接口实现,所以无论外部类是否已经继承了某个实现,对内部类都没有影响。内部类使得多继承的解决方案变得完整。
- 方便将存在一定逻辑关系的类组织在一起,又可以对外隐藏
- 方便编写事件驱动程序(如实现点击监听)
以上内容参考自:Matrix海 子
28、多维数组在内存上是怎么存储的
点击看答案
Java 中的多维数组就是通过一维数组来实现的,只不过这个一维数组中的元素还是多维数组,比如如下声明:
1 | int[][][] array = new int[2][3][4]; |
它实际上大致等同于如下代码:
1 | int[][][] a = new int[2][][]; |
如果要自己用一维数组去实现二维(或者更多维)的数组,可以使用类似规律: k = j*(j-1)/2 + i -1 来计算出在一维数组中的下标 k 值。
以上代码参考自iteye中的博客
29、泛型
点击看答案
一个例子
一个很经典的例子,可以告诉我们为什么需要泛型:
1 | List list = new ArrayList(); |
上述例子for语句上面的操作都是合法的,但是在for语句里面,执行到i==1的时候,会报错(运行的时候报错):
java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String
为了能够在编译期间就能发现这种问题,就可以使用泛型,如下所示:
List
list = new ArrayList (); list.add(100);//编译阶段就会报错
所以,在被问到 ”我初始化一个List,但是没有指定类型,那么,我是不是可以添加任何类型的值?“,那么,答案是肯定的,可以添加任何类型的值,只要你能正确取出(在取的时候,知道每个位置存储的元素的类型),我自己写的例子如下:
1 | List list = new ArrayList(); |
特性
泛型只在编译阶段有效,运行阶段会将特定类型擦除:
1 | List<String> strList = new ArrayList<>(); |
泛型的使用
泛型有三种使用方式,泛型类、泛型接口、泛型方法。一个普通的泛型类如下:
1 | public class Test<T>{ |
然后,我们日常的使用就是类似如下代码:
1 | Test<String> testString = new Test<String>("123"); |
我们定义了泛型类,我们就一定要传入泛型类型的实参么?想想我们最开始的那个例子,很显然并不是这样的。在使用反省的时候如果传入泛型实参,则会根据传入的泛型实参做相应限制,此时泛型才会起到应有的作用;如果不传入泛型类型的实参,则可以为任何类型。看如下例子都是合法的:
1 | Test test1 = new Test("111"); |
这里要注意一点,泛型类型的参数只能是类类型,不能是简单类型。
泛型接口
泛型的接口示例如下:
1 | public interface Test<T> { |
泛型通配符
通配符一般使用 ? 代替具体的类型实参,注意这个 ? 是类型实参,不是类型形参。再直白一点,此处的 ? 和 Number、String、Integer 是一样的,都是一种实际类型,具体代码表示如下:
1 | public void showKeyValue(Test<?> test) { |
这样可以解决当具体类型不知道的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,那么可以用 ? 来表示未知类型。
泛型方法
泛型方法的定义相对复杂,泛型方法是指在调用方法的时候指明泛型的具体类型,如下所示:
1 | public <T> T func(Class<T> tClass) throws InstantiationException { |
静态方法与泛型
静态方法有一种情况需要注意,那就是在类的静态方法中使用泛型:静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
1 | public class StaticTest<T>{ |
泛型上下边界
List<? extends Animal>,?表示的类型可以是Animal类型本身和Animal的子类。可以把Animal称为这个通配符(?)的上限(upper bound)。
<? super Type> 通配符 ? 表示它必须是Type本身,或是Type的父类
30、谈谈Java集合中那些线程安全的集合 & 实现原理
点击看答案
暂无
31、注解
点击看答案
在JAVASE中的注解有3个它们分别是:@Overried 重写,@Deprecated 不建议使用,@SupperssWarning 去除警告信息 。
注解格式如下:
1 | public 注解名称{ |
如果说注释是写给人看的,那么注解就是写给程序看的。它更像一个标签,贴在一个类、一个方法或者字段上。它的目的是为当前读取该注解的程序提供判断依据及少量附加信息。比如程序只要读到加了@Test的方法,就知道该方法是待测试方法。
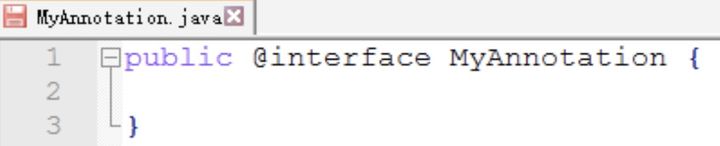
@interface和interface从名字上看非常相似,我猜注解的本质是一个接口(当然,这是瞎猜)。为了验证这个猜测,我们做个实验。先按上面的格式写一个注解(暂时不附加属性):
之后,反编译:
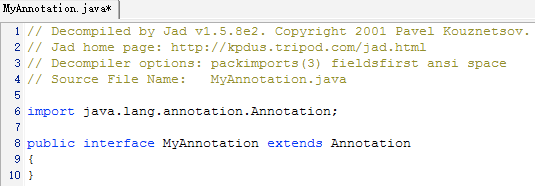
我们发现,@interface变成了interface,而且自动继承了Annotation !
为了探究原理,首先我们看一下Overried 注解的底层实现:
1 |
|
其中Overried注解的上面有两行代码其中一行的修饰符为@Target和@Retention这两个注解是元注解,元注解用来修饰注解,我们来看看这两个注解的底层实现:
1 |
|
Target注解的类里面有一个属性名叫value,他是个数组类型,我们再看看Target注解的用法:
1 |
|
Target表示注解修饰的地方,常用的有3个分别是加载在类上,方法上或者属性上。分别为:ElementType.METHOD,ElementType.TYPE,ElementType.FIELD
Retention表示什么时候读取到这个注解,RetentionPolicy.SOURCE代表源文件读取注解,RetentionPolicy.Class代表编译后读取注解,RetentionPolicy.RUNTIME 代表运行时读取到注解。
以下以一个完整例子展示如何使用注解:
1 | public class JavaMain { |
根据反射,可以获得各个位置的值,Class、Method、Field对象都有个getAnnotation()方法,可以获取各自位置上的注解信息。
32、序列化
点击看答案
关于构造函数
反序列化时,并没有通过 Person 类的构造函数,不管是有参的还是无参的,它是根据序列化的数据创建的
关于序列化的部分
被static和transient修饰成员无法按默认方式序列化。
父类也需要实现Serializable接口才能把父类属性序列化。
父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象
关于同一对象多次序列化
如果执行2次 ObjectOutputStream..writeObject(obj); 则第二次写入对象时文件只增加了 5 字节,并且2次反序列化后两个对象是相等的,这是为什么呢?因为Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用。
自定义序列化过程
虚拟机会试图调用对象类里的 writeObject ()和 readObject() 方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject() 方法以及 ObjectInputStream() 的 defaultReadObject 方法。由于可以自定义,使用writeObject()和 readObject() 方法,可以序列化static和transient修饰的成员
Externalizable完全定制序列化
以上内容参考自敲破苍穹的博客
