1、okhttp的理解
点击看答案
首先看下okhttp 的整个工作流程:
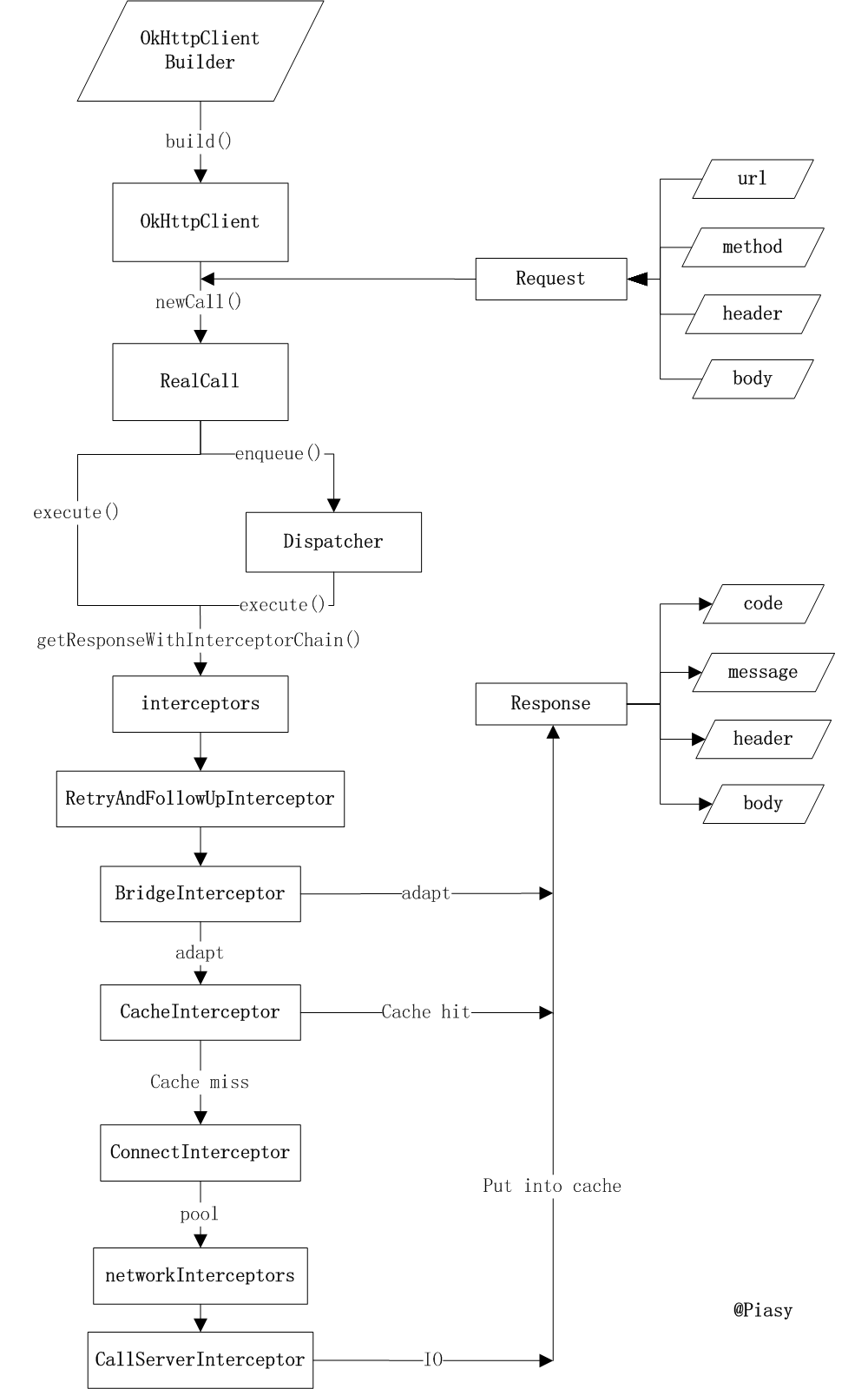
- 首先通过 Builder 创建 OkhttpClient 对象
- 根据设定的条件,使用Request.Builder 构建request 对象
- 根据 OkhttpClient 与 request 创建 RealCall
- 不论是通过execute 还是enqueue 方式异步执行,最终都通过 getResponseWithInterceptorChain 方式获取Http 的返回结果
- 步骤4中,通过Okio 封装的Socket 请求网络,并获取返回结果
Interceptor 是Okhttp 中最重要的一个东西,它不止拦截请求执行一些额外处理,实际上实际的网络请求、缓存、透明压缩等都是通过Interceptor 实现,它们一起连成 Interceptor.chain,每一个Interceptor 决定它自己能处理哪些事件,如果不能处理,则交给下一个Interceptor 处理,也就是责任链模式。这很类似View 中对点击事件的处理。
以上内容参考自:okhttp 解析
okhttp有几种发起请求的方式?
两种,分别是:
- 同步请求,将同步请求任务加入调度器的同步执行的双端队列(即runningSyncCalls,意为正在执行) ,然后直接调用 getResponseWithInterceptorChain 返回结果
- 异步请求,异步请求加入调度器,经历 readyAsyncCalls 和 runningAsyncCalls,之后调用 getResponseWithInterceptorChain
同主机任务最多支持5个并发,同时执行的任务不超过64个。注意,任务执行完成之后,不管同步还是异步,都会将任务从队列中清除
okhttp的interceptor怎么实现责任链?
- 实现 Interceptor接口,重写intercept方法
- 做自己需要的处理,比如更改header之后需要重新builder出request,如果不涉及这块,可以不用重新build
- 使用chain.proceed(request)将请求传到给下一级,并且会有response返回
- 可以对response进行处理,比如根据response重试之类的,如果不做处理就将response作为结果抛给上一级处理
okhttp的调度器
Dispatcher维护了三个队列,分别是: 同步正在执行队列、异步准备执行队列 以及 异步正在执行队列
有哪些拦截器
- CacheInterceptor:处理cache相关处理,如果本地有了可⽤的Cache,就可以在没有网络交互的情况下就返回缓存结果
- addInterceptor(Interceptor),就是我们自定义的一些拦截器,在所有的拦截器处理之前进行最早的拦截处理,比如一些公共参数,Header都可以在这里添加
- ConnectInterceptor,这里主要就是负责建立连接了,会建立TCP连接或者TLS连接
- networkInterceptors,这里也是开发者自己设置的,但是由于位置不同,所以用处也不同。这个位置添加的拦截器可以看到请求和响应的数据了,所以可以做一些网络调试。它对应 addNetworkInterceptor 方法
- RetryAndFollowUpInterceptor,这里会对连接做一些初始化工作,以及请求失败的充实工作,重定向的后续请求工作
- 。。。未完待续,下次做笔记写完整
okhttp的线程池怎么实现
查看Dispatcher类这个代码就可以知道:
1 |
|
将线程池的核心线程数设置为0;线程池容纳的最大线程数量为 Int.MAX_VALUE;超时时间设置为 60s ;队列设置为同步队列 SynchronousQueue ,先来先服务;
OkHttp线程池设计为核心线程为0是因为客户端可能在一段时间内不会有网络请求,为了避免浪费不必要的线程内存,所以不保留最低线程,同时最大线程设置为Int.MAX_VALUE为了防止同一时间有大量的请求进入,造成部分请求被抛弃的问题,设置60秒为线程空闲最大时间,在一段时间不使用的情况进行线程回收。
SynchronousQueue每个插入操作必须等待另一个线程的移除操作,同样任何一个移除操作都等待另一个线程的插入操作。因此队列内部其实没有任何一个元素,或者说容量为0。因此我们可以理解来了任务直接执行。
还有要注意的一点就是,如果异步请求中,runningAsyncCalls 的数量大于64后,就会加入到 readyAsyncCall 排队等待
okhttp用到什么设计模式
- 责任链模式(拦截器)
- 建造者(比如 Request 就是通过建造者模式建造出来的)
- 工厂模式(比如CacheInterCeptor中的策略工厂 CacheStrategy.Factory)
- 单例模式
2、谈谈对RxJava的理解
点击看答案
常用操作符
- map:将被观察者发送的数据类型转换为其他类型
- flatMap : 将事件序列中的元素整合,返回一个新的被观察者
- zip : 将多个观察者事件整合发送给观察者
如何实现线程切换
- Observer 最终会封装成 SubscribeTask ,这个类实现了 Runnable 接口。
- 最终在 Runnable 的run 方法中完成 观察者-被观察者的订阅关系
- 也即,这个run 在哪个线程执行,observer 方法就在哪个方法执行。
- 如果是 AndroidSchedulers.mainThread 的话,则会以Android主线程的Looper(Looper.getMainLooper())新建一个 Handler ,之后将上述Runnable 封装成Message ,通过Handler 发送到主线程。
- 如果是其他线程,则会丢给特定线程或者线程池处理。
以上内容参考自: rxjava2线程切换原理、rxjava使用与原理
3、fresco的理解
点击看答案
为什么使用fresco
- 部门决定采用webp 格式的图片,而fresco 对其支持
- 5.0 以下Android系统,使用 ashmem(匿名共享内存) 区域存储bitmap ,它的创建、释放都不会触发 GC,带来良好的性能。
fresco 使用ashmem 区域存储bitmap ,gc不会处理这块区域,并且也不会被”ashmem内置清除机制”回收,所以减少gc,提升性能。在ashmem 中,fresco 采用引用计数方式,自己管理内存。
- 使用了三级缓存,方便图片快速复用、加载:Bitmap 缓存 + 未解码缓存 + 硬盘缓存,前面两个是内存缓存,Bitmap 根据不同系统版本存放不同区域(5.0以下存放ashmem),未解码存放在堆内存。
- fresco 的设计,UIThread 只做从内存缓存中加载图片和显示图片两件事,其他诸如 图片Decode、缓存读写 都放在非 UI线程。
fresco 原理解析
典型的MVC模式应用:
- DraweeView : view 层,负责显示图片。它继承ImageView 的目的是使用它来显示 drawable ,其他的ImageView 方法都没有使用,也不推荐使用。
- Hierarchy: model 层,负责生成要显示的图片
- DraweeController: controller 层
DraweeView 把获得event 转给 controller,controller 决定是否隐藏或者显示什么图像,而这些图像存储在 Hierarchy,最后 DraweeView 直接通过 getTopLevelDrawable 获取要显示的图像。
DraweeView 不直接与 Hierarchy 及 DraweeController 打交道,而是通过 DraweeHolder 间接与他们打交道,因为 DraweeHolder 管理着 Hierarchy 与 Controller。
图片库的选择
Picasso
自己没有实现缓存,配合 Okhttp 在 Okhttp里面实现缓存
优点:
- 与Square系的库搭配较好,如okhttp、retrofit等
- 包小
- 功能简单
Glide
优点:
- 支持webp、gif、video
- 支持Memory和Disk缓存
- 默认RGB_565,开销小
fresco
优点
支持webp图片
native层缓存图片,减少oom
使用简单,几乎都能在xml上搞定
缺点:
- 太大
fresco 图片切换原理
DraweeHierarchy 内部维护着一个Drawable序列,这些个Drawable代表不同层次的图片,如果没有设置,这层Drawable就会为null,如果设置了但此时不应该展示它,比如 ActualImage 已经加载到了,不需要placeHold图片了,就把这层Drawable的 alpha 置为 0 。
准确地说是 FadeDrawable 中包含了上述的Drawable,在调用 FadeDrawable 的onDraw() 方法时,就会一层一层绘制,如果该层为null或者alpha为0,就不绘制,这样就实现了切换。
关于Ashmem
Ashmem不能被Java应用直接处理,但是也有一些例外,图片就是其中之一.当你创建一张没有经过压缩的Bitmap的时候,Android的API允许你指定是否是可清除的:
1 | BitmapFactory.Options = new BitmapFactory.Options(); |
经过以上处理,当 Android 绘制系统在渲染这些图片,Android 的系统库就会把这些 Bitmap 从 Ashmem 堆中抽取出来,而当渲染结束后,这些 Bitmap 又会被放回到原来的位置。如果一个被抽取的图片需要再绘制一次,系统仅仅需要把它再解码一次,这个操作非常迅速。
Fresco 如何将图片放到Ashmem中?Ashmem一般在应用层是无法直接访问的,除了几个特例之外,其中之一就是 decode bitmap。我们可以通过设置BitmapFactory.Options.inPurgeable = true 来创建一个Purgeable Bitmap,这样decode出来的bitmap是在Ashmem内存中的,GC无法直接回收它。当Bitmap在使用时会被pin住,这样就不会被释放,使用完之后就unpin,这样系统在未来某个时刻会释放这部分内存。如果unpin的图片后续又要使用,就得再次decode,如果是在ui线程执行decode,就可能掉帧,因此google建议使用 inBitmap 来尝试使用已经存在的内存区域,而不是新分配区域,不过,要使用inBitmap ,必须要求二者有相同的解码格式,比如都是8888或者都是 565 的。
Fresco 为了让inPurgeable的bitmap不被自动unpinned,可以使用jni函数 AndroidBitmap_lockPixels()来强制pin bitmap,这样避免在unpinned之后,重新decode 这个Bitmap 而引起掉帧,不过这样就需要自己来管理这块空间了,我们可以使用 AndroidBitmap_unlockPixels 来让bitmap 重新变为 unpinned 状态。这样,系统在内存不足的时候,就可以回收这块内存了。Fresco使用Ashmem这块的知识点详细参考这篇文章
4、ThreadLocal 详解
点击看答案
ThreadLocal 很典型的一个用处就是存储线程的 Looper,我们知道,子线程中初始化Handler 的时候,需要先执行 Looper.prepare ,这个操作就是新建一个Looper 并且将其保存到 ThreadLocal 中。
Thread 类中有个专门存储线程的 ThreadLocal 数据的结构,即 ThreadLocal.Values 。保存值时,首先通过 Thread.currentThread 获取到当前线程,再获取该线程的 ThreadLocal.Values ,这个 Values 中有个 Object[] table 的数组,ThreadLocal 对象就存在这个数组中。每个 ThreadLocal 对象根据自己的 hashcode 按照一定规则获取到在数组中的 index ,之后进行读取或者存储。
这样,每个线程通过同一个 ThreadLocal 获取到的是不同的值。各个线程可以相互独立地执行操作。
以上内容总结自源码,部分语言参考自任玉刚的博客内容
5、LocalBroadcastManager
点击看答案
LocalBroadcastManager 注册本地广播只能通过代码,不能通过xml静态注册。本地广播不会跨进程,不用跟system_server 交互。
原理分析
首先,LocalBroadcastManager.getInstance 是个单例,在初始化过程中,会根据 mainLooper 创建一个Handler:
1 | private LocalBroadcastManager(Context context) { |
其次,注册过程,其实可以理解成订阅某种消息,以便在符合条件的消息发送的时候,这里能接收:
1 | public void registerReceiver( BroadcastReceiver receiver, IntentFilter filter) { |
接着,发送广播,可以理解为,根据 sendBroadcast(Intent intent) 中 intent 的值获取 actions,再根据action 来查询相应的广播接收者,当然,如果当前receiver 正在处理其他广播,则跳过:
1 | public boolean sendBroadcast(Intent intent) { |
在 LocalBroadcastManager 的构造函数中我们初始化了这个以 mainLooper 建立的Handler,此时利用它 sendEmptyMessage,在handleMessage 中最终会调用 executePendingBroadcasts 方法(说明此函数也运行在主线程):
1 | private void executePendingBroadcasts() { |
通过以上的原理分析,我们知道本地广播只是在发送广播的时候,在主线程中挨个通知 action 符合的receiver,因此并不会超出进程范围,也不会超出 app 范围,只会在当前app 的当前进程发生。
以上内容参考自gityuan的分析
6、Java线程池ThreadPoolExecutor实现原理
点击看答案
ThreadPoolExecutor 构造函数参数非常多,有以下:
corePoolSize: 通过 submit 或者 execute 提交任务时,如果当前线程池的线程数 n < corePoolSize ,则创建一个新的线程处理任务,即使其他 core 线程是空闲的。
maximumPoolSize: 如果当前线程数 n > corePoolSize && n < maximumPoolSize ,那么不会创建新的线程;但是如果 n >= maximumPoolSize 时,就会创建新的线程。如果是个无界队列(LinkedBlockingQueue),那么不存在满的情况(n >= maximumPoolSize),也就不会创建新线程。
keepAliveTime: 如果当前线程池中的线程数 n > corePoolSize,那么如果在 keepAliveTime 时间内没有新的任务需要处理,那么就会销毁 corePoolSize - n 个线程。
handler :异常处理策略。即当任务提交失败的时候,调用这个处理器。
运行状态
ThreadPoolExecutor 使用一个 AtomicInteger 的前三位表示线程池状态,后 29 位表示线程数,因此是可以支持上亿的线程计数。线程池主要有几种状态:
- Running: 线程池正在运行,可以接收新任务。
- ShutDown: 不再接收新任务,但会继续处理队列中任务。
- Stop: 不接受新任务,也不处理队列中任务,并且中断正在处理的任务
- Tidying: 所有任务处理玩,线程数为 0(线程池为空)
- Terminated: 已经执行完毕(执行了 terminated)
submit 执行过程 就是将 Runnable 和 Callable 封装成 RunnableFuture 之后,最终提交给execute 执行。使用 HashSet 类型的 worker 来存储正在运行的任务,只要 worker.size() < corePoolSize,提交新的任务就马上开启新线程执行(上面提到过)。在提交过程中要检查线程池的状态,检查是否关闭了。
worker的数目也是通过 CAS的方式 增减的。
以上内容参考自github上的博客
7、延伸-Java 线程池的异常处理机制
点击看答案
- 如果是使用submit 提交的话,可以通过继承 ThreadPoolExecutor 再重写 afterExecute 方法,得到实际的异常 (包含 Runnable 和 Throwable)
- 如果是调用的execute 方法提交的话,那就会抛到 dispatchUncaughtException 里面去了,这时候我们只有对线程 Thread.setUncaughtExceptionHandler(UncaughtExceptionHandler) 来捕捉。即自己写 ThreadFactory (thread 工厂类),并为创建的线程 setUncaughtExceptionHandler
- 还有一种,就是对 Runnable 的 run 方法里面整个 try-catch
以上内容参考自并发编程网 或者它在github上的相同文章
8、AsyncTask 解析
点击看答案
AsyncTask 是个抽象类,必须子类实现才能使用。在构建的时候,需要指定三个泛型参数类型,分别是 Params、Progress、Result ,即类似 AsyncTask<Integers, Integers, ResponseBean> ,当然,如果某个参数不需要,类型可以写成 Void 。
其整体原理还是 将task丢给ThreadPool 在子线程执行,得到结果后,通过 Handler 的 sendEmptyMessage 的方式将结果切换到主线程
在 AsyncTask 使用的过程中需要遵守如下原则:
- 必须在UI线程中实例化
- execute 必须在UI线程中调用
- 不要人为调用 onPreExecute、onPostExecute、doInBackground 和 onProgressUpdate
- 一个 AsyncTask 实例只能执行一次,如果多次调用会报异常
AsyncTask 中有 static 的 ThreadPool ,意味着不管有多少个实例,都只有这个线程池,而在初始化这个线程池的时候,corePoolSize 在不同版本的值默认被设置为 1 或者 5 (Android 3.0以前是5,还不能改;3.0之后设置为1,但是可以自己设置Excutor ),并且 BlockingQueue 基本上是个无界队列(BlockingQueue 或 SynchronousQueue,队列不存在满的情况),根据 ThreadPool 的原理,我们每次最多只有一个线程或者 5 个线程在执行,意味着多的任务就要排队,并不能实时执行,并且在早期,我们不能设置自定义的 ThreadPoolExcutor,到后来才可以(貌似是Android 4.0以后)。
AsyncTask 存在的问题:
- AsyncTask 对象只能execute 一次,多次请求会导致多个对象创建
- 生命周期与Activity 的生命周期不一致,有可能导致内存泄露
- cancle 并不马上生效,因为它就是线程,在cancle之后,还得等它完成
以上内容参考自 系统源码、github上的博客、cnblogs的博客、csdn的博客
9、阿里Alpha原理
点击看答案
想象下有以下场景:
有6个任务需要在Application里面执行,其中Task1,Task4,Tas6需要在主线程执行,Task2,Task3需要在Task1执行完才能执行,Task4,Task5需要Task2和Task3执行完才能执行,Task6需要Task4和Task5执行完才能执行,Task4的耗时要大于Task5,是不是顿时就乱了?其实可以通过 PERT 图来捋一捋这个关系,涉及到具体实现的话,可以参考阿里巴巴的 alpha 框架。
Alpha是一个基于PERT图构建的Android异步启动框架
首先解决多进程疑惑,在start方法中就首先判断了 主进程任务、非主进程任务 以及 适用于所有进程的任务,这些任务是通过 public void addProject(Task project, int mode) 方法添加进去的。
在实际情况中,可能会有多个任务同时开始,并且也有可能多个任务作为结束节点,所以为了方便控制整个流程,alpha 设计了startTask 和 finishTask,标记流程的开始和结束,方便任务的监听
如果Task 是在主线程执行的,那么就通过Handler 将时间传递给主线程;如果是非主线程,则通过线程池去执行。
在一个Task执行完成后,就会遍历自己持有的 mSuccessorList(紧后任务列表,也就是当前任务执行完成之后可以执行的Task列表,这里面的Task会根据Priority进行排序),并依次执行里面元素的 onPredecessorFinished 方法。
mSuccessorList 列表中的Task 是通过 after 方法加入的:
1 | //紧后任务添加 |
意思是Task2要在Task1后面执行,这样,Task2就是Task1的紧后任务,同理,Task1也成了Task2的紧前任务,那这个紧前任务有什么用呢?试想一下,如果Task1、Task2、Task3的紧后任务都是 Task4,那么,在Task1执行完成之后,还要判断 Task2和Task3是否执行完成,然后才能决定是否执行Task4,这就是紧前任务的作用了。
以上文章主要参考自:积木zz的csdn博客, 有博客说,使用 Anchors 比使用 Alpha 更精细,后续再看
10、LeakCanary 原理
点击看答案
原理:
- 通过registerActivityLifecycleCallbacks 来监听 Activity 的生命周期 onActivityDestroyed。
- 即 lifecycleCallbacks 监听Activity 的 onDestroy 方法,正常情况下执行了onDestroy 后资源立即回收。
- 监察机制利用了 WeakReference 和 ReferenceQueue ,使用 WeakReference 对Activity 进行引用,在Activity回收的时候,就会将该WeakReference 引用放到 ReferenceQueue 中。
- 在onDestroy 之后,等待一段时间,再通过监测 ReferenceQueue 是否包含 WeakReference 就能检查 Activity 是否被正确回收。
- 如果Activity 没有被回收,就手动 GC 一次,等待若干时间,之后再次判断Activity 是否被回收,若未被回收,说明 Activity 已经泄露。
- 如果Activity 泄露了,则抓取 dump 信息显示出来。
以上要注意的是:
1、是使用WeakReference对Activity进行引用
2、LeakCanary可以配置忽略某些路径的内存泄漏
3、手动GC是使用的 Runtime.getRuntime().gc() 实现,代码中解释是这样触发gc的概率会比System.gc() 高一些: System.gc() does not garbage collect every time. Runtime.gc() is more likely to perform a gc.
4、 当Activity对象被回收时,会将 WeakReference(而不是Activity)对象放入 ReferenceQueue 中,自己写的测试代码如下:
1 | public class MainActivity extends AppCompatActivity { |
以上代码将会打印出以下结果:
testObject = com.example.myapplication.RecyclebleObject@86f4db5
referenceQueue 中的内容: null
GC 后,testObject = null
GC 后,referenceQueue 的内容: java.lang.ref.WeakReference@f6c4a,这个对象与objectWeakReference 相等吗? true
说明在回收后, WeakReference 对象会出现在 referenceQueue 中,而不是 testObject 本身出现在 referenceQueue 。
有意思的是,在 LeakCanary2 时,并不需要接入者手动初始化(LeakCanary.install(this);)了,而是只需要引入即可。其根本原理是:LeakCanary 写了个 ContentProvider 并在 AndroidManifest中注册了,并在 ContentProvider 的onCreate方法中执行了 install 操作!我们知道,ContentProvider 的 onCreate 方法会在启动App的时候自动执行,并且比 Application 的 onCreate 方法还要早,因此它自动执行完全没问题。
以上内容参考自JasmineBen的博客、CSDN上的博客、以及自己写的代码验证
11、Toast显示流程
点击看答案
首先,为了避免Toast显示冲突,会将要显示的Toast放在队列中,然后依次取出来展示
- makeText的时候,创建Toast对象和TN对象,Toast创建好后,加载布局,创建mNextView,然后 TN 是控制Toast的显示和隐藏以及取消的,它里面有个 Handler ,以当前线程的Looper来初始化,Toast的显示隐藏取消就是通过这个Handler来处理的。
- Toast对象创建完成就 enqueueToast 到NotificationManagerService 进程中去排队的(所以这中间是有跨进程通信这个概念的),在中间会判断是否要显示这个Toast(如果此Toast正在取消或者隐藏就不展示了),接着就开始排队,显示的话,就是不断从队列里面取出 ToastRecord ,然后调用 Toast对应的TN 的show 方法展示Toast。
- TN收到显示的消息,创建WindowManager对象,然后将第一步创建的 View 添加到 WindowManager ,之后Toast 就显示出来了。
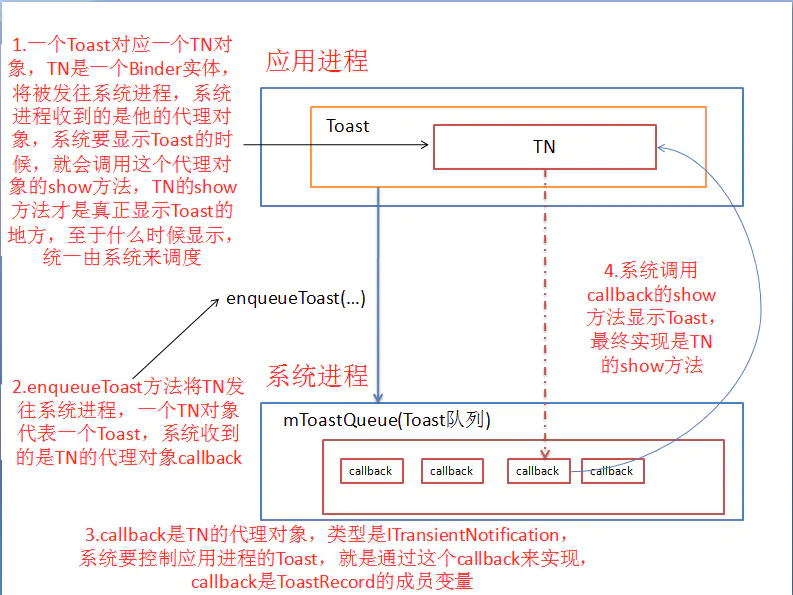
以上内容参考自简书上的博客
12、onTouchListener、onTouchListener 的onTouch方法、onTouchEvent、onClickListener、onLongClickListener 的执行顺序?
点击看答案
- dispatchTouchEvent 在 onTouchListener 之前发生,如果在 dispatchTouchEvent 的 down 事件就return 了 false,则后续的事件压根就不会传过来了,所以不会有什么故事。
- 但如果 down 事件返回了 true ,则事件虽然onTouchListener 和 onTouchEvent 会发生,但不会有点击事件了,即onLongClick 和 onClick 都不会响应了。
- onTouchListener 在onTouchEvent 之前发生, onLongClick 与 onClick 依赖于是在onTouchEvent 里面发生的,也就是说 click 事件是在 onTouchEvent 之后执行,并且 onClick 在 onLongClick 之后执行。
- 如果在 onTouchListener 的 onTouch 方法中返回true,则没有后面的 onTouchEvent 什么事了,更别提 click 事件
- 在onTouch 发生后,如果直接在 onTouchEvent 中返回true 或者false ,那就没有 click 什么事情了(因为click 是在super.onTouchEvent中)
- 如果TouchEvent 不做处理,那么在down事件发生后长按,则会响应 onLongClick 事件,之后up,如果之前的 onLongClick 返回false ,则还会接着 onClick,反之,如果之前的 onLongClick 返回true,则 onClick 不会执行。
13、Android 事件中 CANCLE 事件是怎么来的?它的作用是啥?
点击看答案
第一个问题:我们知道view如果处理了 Down 事件,则随之而来的 Move 和 Up 事件也会交给它处理,但是交给它处理之前,父View 可以拦截,如果被拦截了,就会返回 Cancel 事件,并且不会收到后续的 Move 和 Up 事件
第二个问题:
以上内容参考自 csdn上的博客
14、Handler 解析
点击看答案
构造函数
Handler 有多个构造函数,看下图:
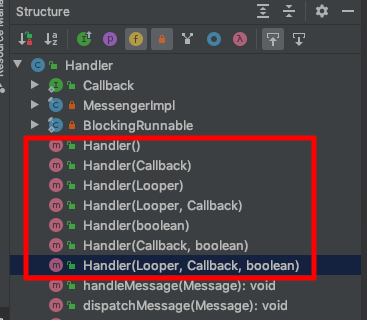
这些参数有几个需要解释下,callback:用于控制消息执行顺序的,具体参看Handler 的 dispatchMessage 方法。
1 | public void dispatchMessage( Message msg) { |
在执行时,如果 msg 设置了 callback,则优先执行,接下来,如果Handler 有设置了 callback ,则执行这个callback ,最后才是我们熟悉的 handleMessage 方法。因此,我们说 这个 callback 是控制执行顺序的。
Looper 参数表明的是,Handler 将在哪个线程执行,使用哪个线程的。
boolean 类型的 async 值是指 Handler 是否发送异步消息,这个异步消息要配合消息屏障使用。首先设置了消息屏障,之后 Looper 中只会执行异步消息了,直到消息屏障被 remove 。
1 | Message next() { |
15、ViewStub源码解析
点击看答案
首先,在构造函数里面有两个点值得关注:
1 | public ViewStub(Context context, AttributeSet attrs, int defStyleAttr, int defStyleRes) { |
构造方法里面就直接将ViewStub置为不可见,并且,设置为不会 draw ,因为ViewStub本身不展示,所以无需 draw 。然后,我们一般都是通过inflate 或者 setVisibility 来设置ViewStub的可见性:
1 | public void setVisibility(int visibility) { |
由以上代码可以看到,调用 setVisibility 时,如果以前有inflate出来真正的 view 了,那就直接对这个 view.setVisibility ;否则,如果 setVisibility 为 visible 或者 invisible ,都会触发 inflate 操作。
inflate 操作,如果没有指定真正的 view 的布局id (mLayoutResource),那会抛出异常,之后,将真正的 view 以 ViewStub的parent 作为 parent 先inflate 出来,接下来 replaceSelfWithView 其实就是将真正的 view 替换到原来 viewstub的位置(位置 index 和布局参数 layoutparams 都拿过去),而 原来的 ViewStub 会被remove 掉:
1 | private void replaceSelfWithView(View view, ViewGroup parent) { |
为何无大小不绘制
1 |
|
从源码可以直接看到,在 onMeasure 中,直接 setMeasuredDimension(0, 0) 即宽和高都变为 0 了,并且draw 和 dispatchDraw 都是空方法。
能inflate多次吗
还是看inflate 的源码:
1 | public View inflate() { |
能够看到,inflate 的时候,这里会获取 ViewStub 自己的 parent,然后呢,会判断 viewParent != null,由于前面说了,inflate 的时候已经将 ViewStub 从patent 中移除,所以这里肯定为 null ,因此,这就会报错啦。所以我们只能inflate一次
以上内容参考AS打开的源码,以及CSDN上的观点
16、事件传递顺序
点击看答案
首先,由源代码可知:
1 | public boolean dispatchTouchEvent(MotionEvent event) { |
首先执行 dispatchTouchEvent ,其次 执行 OnTouchListener.onTouch,如果返回true ,则不会执行后续的 onTouchEvent 了
其次,看 onTouchEvent 的源码:
1 | public boolean onTouchEvent(MotionEvent event) { |
由此可知,onLongClickListener 、onClickListerner 都是在 onTouchEvent 中触发的,前者是在DOWN事件中触发,后者是在UP事件中触发。如果 onLongClickListener 执行了,onClickListerner 就不会执行。
综上,dispatchTouchEvent -> onTouchListener -> onTouchEvent -> onLongClick -> onClick 的顺序
17、EventBus 原理
点击看答案
注: 本文的EventBus版本为 3.0
Subscrib 注解
自 3.0 以来,EventBus 使用 @Subscrib 注解来标记订阅事件的方法,方法命名随意。并不用像以前那样指定方法的命名:
1 |
|
这个注解的定义很有个性,可以看下:
1 |
|
其中有几种线程模式,有以下几种:
ThreadMode.MAIN:如在主线程(UI线程)发送事件,则直接在主线程处理事件;如果在子线程发送事件,则先将事件入队列,然后通过 Handler 切换到主线程,依次处理事件。
ThreadMode.ASYNC:与ThreadMode.MAIN_ORDERED相反,无论在哪个线程发送事件,都将事件加入到队列中,然后通过线程池执行事件
ThreadMode.POSTING:默认的线程模式,在哪个线程发送事件就在对应线程处理事件,避免了线程切换,效率高。
ThreadMode.MAIN_ORDERED:无论在哪个线程发送事件,都将事件加入到队列中,然后通过Handler切换到主线程,依次处理事件。
ThreadMode.BACKGROUND:与ThreadMode.MAIN相反,如果在子线程发送事件,则直接在子线程处理事件;如果在主线程上发送事件,则先将事件入队列,然后通过线程池处理事件。
注册
注册过程很简单:
1 | EventBus.getDefault().register(this); |
根据源码可以直到,这个方法就做了两件事情:
- 根据传入的参数object ,获取其 Class ,然后通过这个 Class 获取所有的方法(当然,首先看有没有缓存),查看经过 @Subscrib 修饰的方法,即这个类中所有的订阅方法(会做封装),生成一个list
- 遍历上述生成的 list ,给 2 个 Map 填充数据:subscriptionsByEventType以 event (订阅方法的参数)的类型(Class)为key,value 为订阅方法list(CopyOnWriteArrayList);typesBySubscriber 以register时传入的对象为key ,value 为 这个对象所有订阅方法所订阅的事件。
1 | //EventBus中变量的声明 |
反注册
反注册也很简单:
1 | EventBus.getDefault().unregister(this); |
刚才在注册时候,说了其中一个 map 为 typesBySubscriber,它以注册对象为 key ,value 为这个对象中所有注册方法所注册的event 类型的列表。所以在反注册的时候,
- 首先通过传入的对象,获取 注册的 event 的列表
- 遍历这个列表,获取 event 的类型,然后通过这个类型在 subscriptionsByEventType 查找(经过封装的)订阅方法,根据封装在里面的 注册对象 是否是当前 unregister 传入的对象来判断,如果是当前传入的对象,就移除这个经过封装的订阅方法
post 发布事件
post的使用也很简单:
1 | EventBus.getDefault().post(new Object()); |
注册的时候,说了有一个map 为 subscriptionsByEventType ,以 event 的类型为key ,存储了所有订阅了这中 event 的(经过封装的)方法。post 的时候,根据post发送的事件类型(post方法的参数的 Class )从 subscriptionsByEventType 这个集合中获取到所有的订阅方法。之后依次通过反射调用这些方法:
1 | void invokeSubscriber(Subscription subscription, Object event) { |
其中, subscription.subscriberMethod.method 是 Method 类型的,用过反射的话,就知道它可以直接 invoke ,它的定义是这样的:
1 | public native Object invoke(Object obj, Object... args) |
第一个参数 obj 指的是用 obj 这个实例来调用这个方法(因为一个类可能会有多个实例,非静态方法需要指定一个实例来调用这个方法),后面的 args 就是方法需要传入的参数。
所以,在 invoke 的时候,subscription.subscriber 我们应该很容易知道是 register 时传入的那个 Object !由此,我们一个消息就形成了闭环。
最后问题,支持跨进程吗?
先说结论:不支持跨进程,因为单例。经过上述分析,我们知道 EventBus 的注册、反注册、post 都是通过:EventBus.getDefault() 实现,我们看下它的代码:
1 | public class EventBus { |
所以我们都是基于一个 static 类型的 defaultInstance去做一系列操作,由于跨进程后,静态会失效,所以,EventBus 并不能跨进程。
18、ARouter 的原理
点击看答案
为了让业务逻辑彻底解耦,同时也为了每个module 都可以方便地单独运行和调试,上层的各个 module 不会相互依赖,而是共同依赖 base module,如下所示:
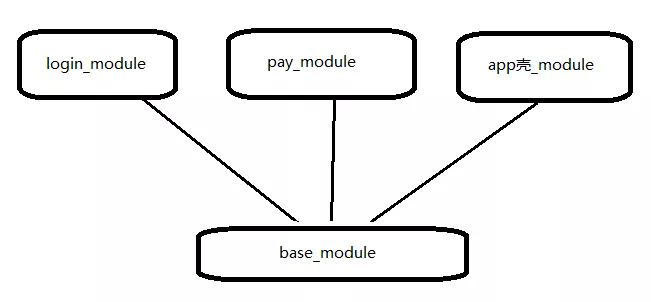
由于module之间没有依赖,那如何实现业务跳转呢? 首先,隐式跳转是一种可行的解决方案,但如果一个项目里面全是隐式跳转的,就会导致 Manifest 文件中有很多过滤配置,并且非常不利于后期维护。其实,在组件化中,我们通常都会在 base_module 上层再依赖一个 router_module ,这个 router_module 就是负责各个模块之间的页面跳转的。
ARouter 源码理解
用过 ARouter的都知道,每个需要对其他 module 提供调用的 Activity ,在声明的时候都会带有 @Router 注解,我们称之为路由地址,如下所示:
1 |
|
这个注解有什么用呢?路由框架会在项目编译期通过注解处理器扫描所有添加@Router注解的类,之后,将Router 注解中的 path 地址 和 Activity 的 class 文件映射关系保存到它自己生成的 java 文件中,示例如下:
1 | public static HashMap<String, ClassBean> getRouteInfo(HashMap(String, ClassBean) routes) { |
这样,我们想在app 模块之间跳转,就可以通过这个映射关系找到目标了,一般使用方法如下:
1 | ARouter.getInstance().build("/login/login") |
上述例子中,通过 /login/login 可以找到对应的class : LoginActivity.class ,最终会通过 ActivityCompat.startActivity() 方式启动目标Activity。
ARouter在初始化的时候只会一次性地加载所有的Root结点,而不会加载任何一个Group结点,这样就会极大地降低初始化时加载结点的数量。那么什么时候加载分组结点呢?其实就是当某一个分组下的某一个页面第一次被访问的时候,整个分组的全部页面都会被加载进去,这就是ARouter的按需加载。其实在整个APP运行的周期中,并不是所有的页面都需要被访问到,可能只有20%的页面能够被访问到,所以这时候使用按需加载的策略就显得非常重要了,这样就会减轻很大的内存压力。
其他细节略
