UI优化<上>-20讲
UI渲染的背景知识
ppi 像素密度,每英寸包含的像素数,这是物理参数,不可改
dpi 像素密度,指的是单位尺寸像素数量。这是可以人为调整的
density 密度,每平方英寸中包含的像素点数,density = dpi / 160
dp : px = dp * density
屏幕适配方案
使用dp
限制符适配
CPU 与 GPU
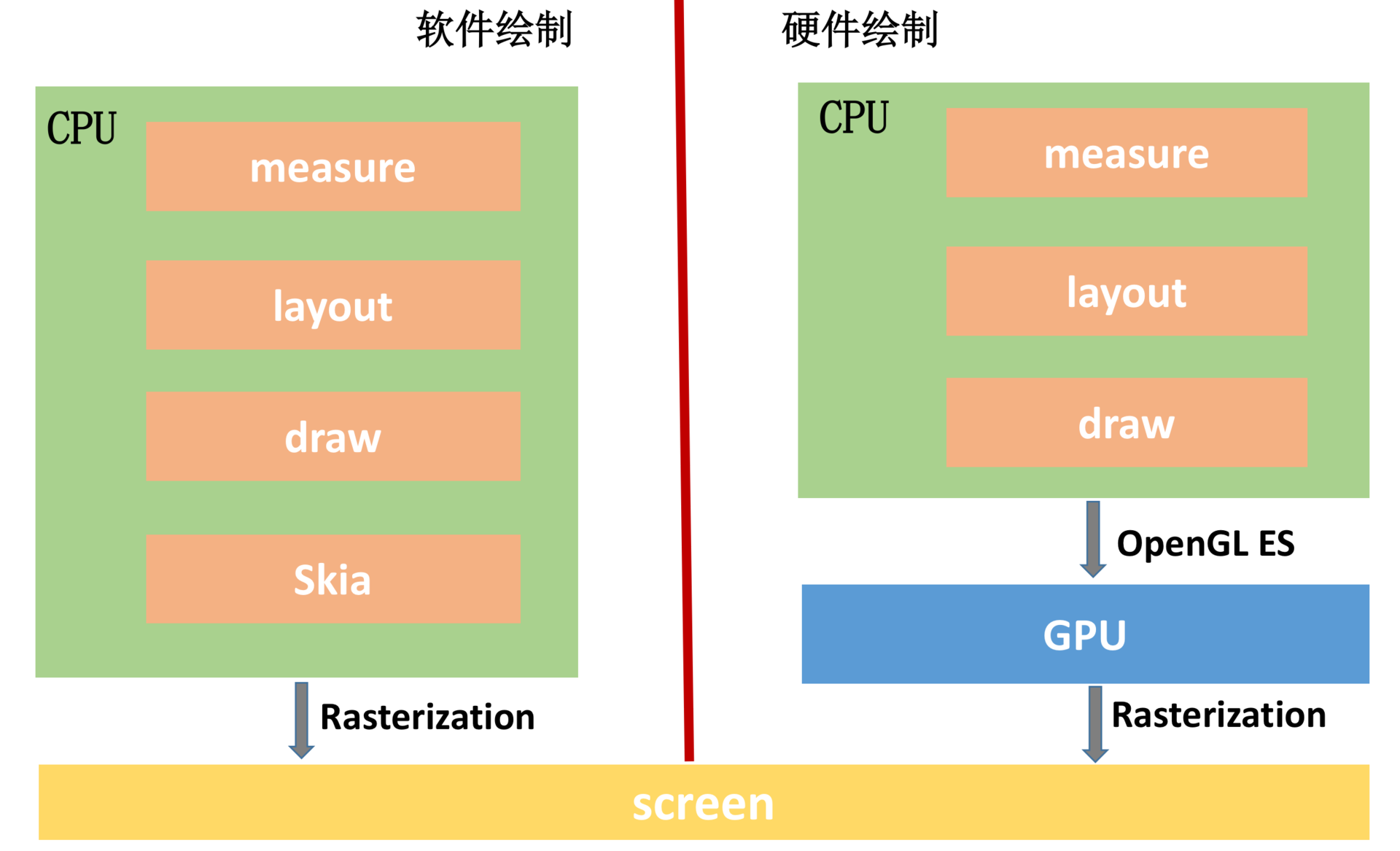
由上面的图可以知道,软件绘制使用的是Skia 库,硬件绘制是通过 open GL 之后在GPU 上实现的
在Android 7.0以后,添加了对 Vulkan 的支持,它比 OpenGL 功耗和多核优化上更优秀
Android 渲染的演进
可以通过下图整体看下Android 图形体系:
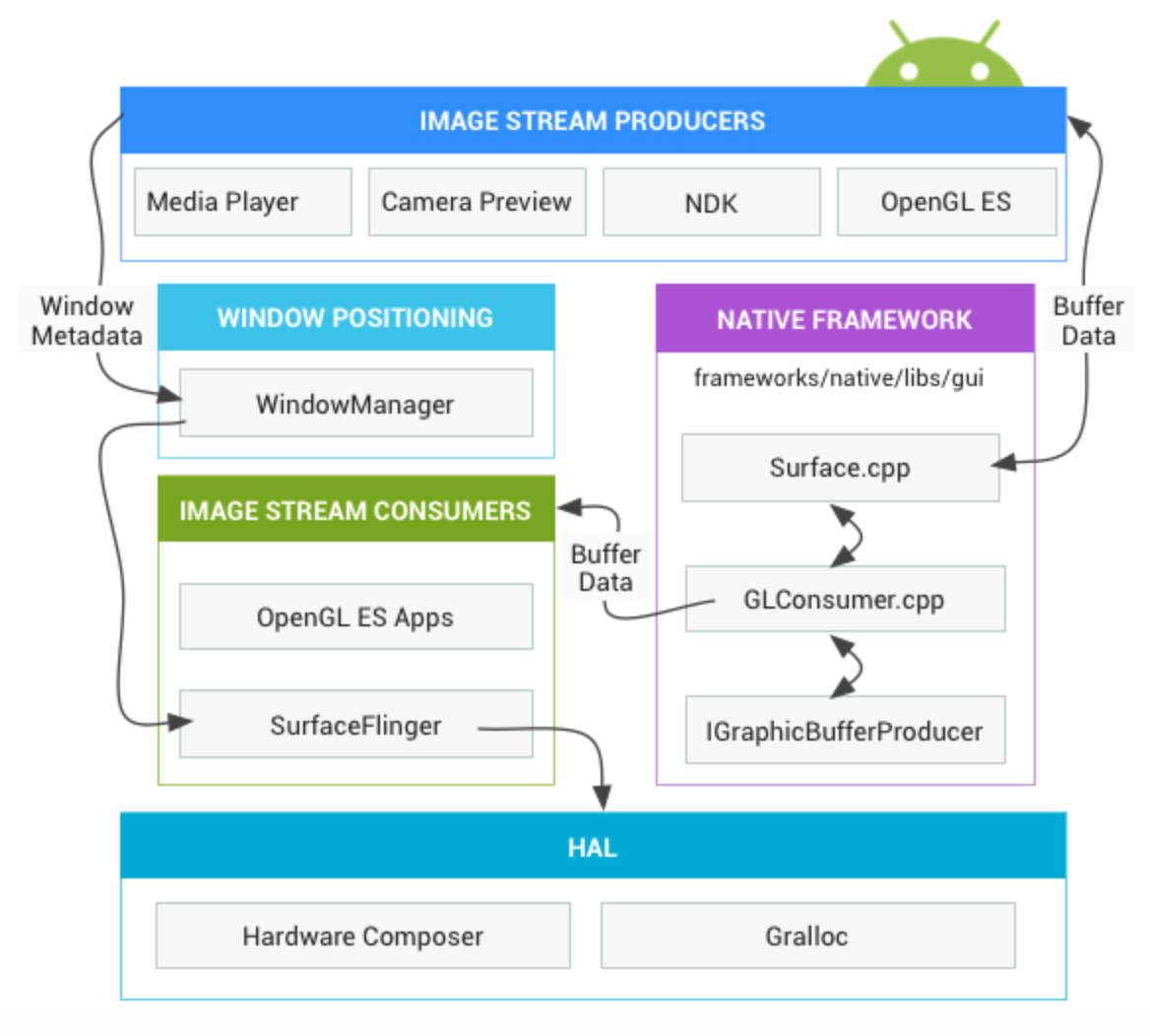
各个部分的功能可以比喻成以下内容:
- 画笔:Skia 或者 OpenGL 。Skia 使用CPU 绘制,OpenGL 使用 GPU 绘制
- 画纸:Surface。所有元素都在 Surface 这张画纸上绘制和渲染。在Android中,Window 是View的容器,每个Window 都会关联一个Surface。windowManager 负责管理这些 window ,并且把它们的数据传递给 SurfaceFlinger。
- 画板:Graphic Buffer。Graphic Buffer 缓冲用于应用程序图形的绘制,Android 4.1 之前使用的是双缓冲;4.1之后使用三缓冲
- 显示:SurfaceFliger 。将WindowManager 提供的所有 Surface ,通过Hardware Composer 合成并输出到显示屏
开启硬件加速
软件绘制流程图如下:
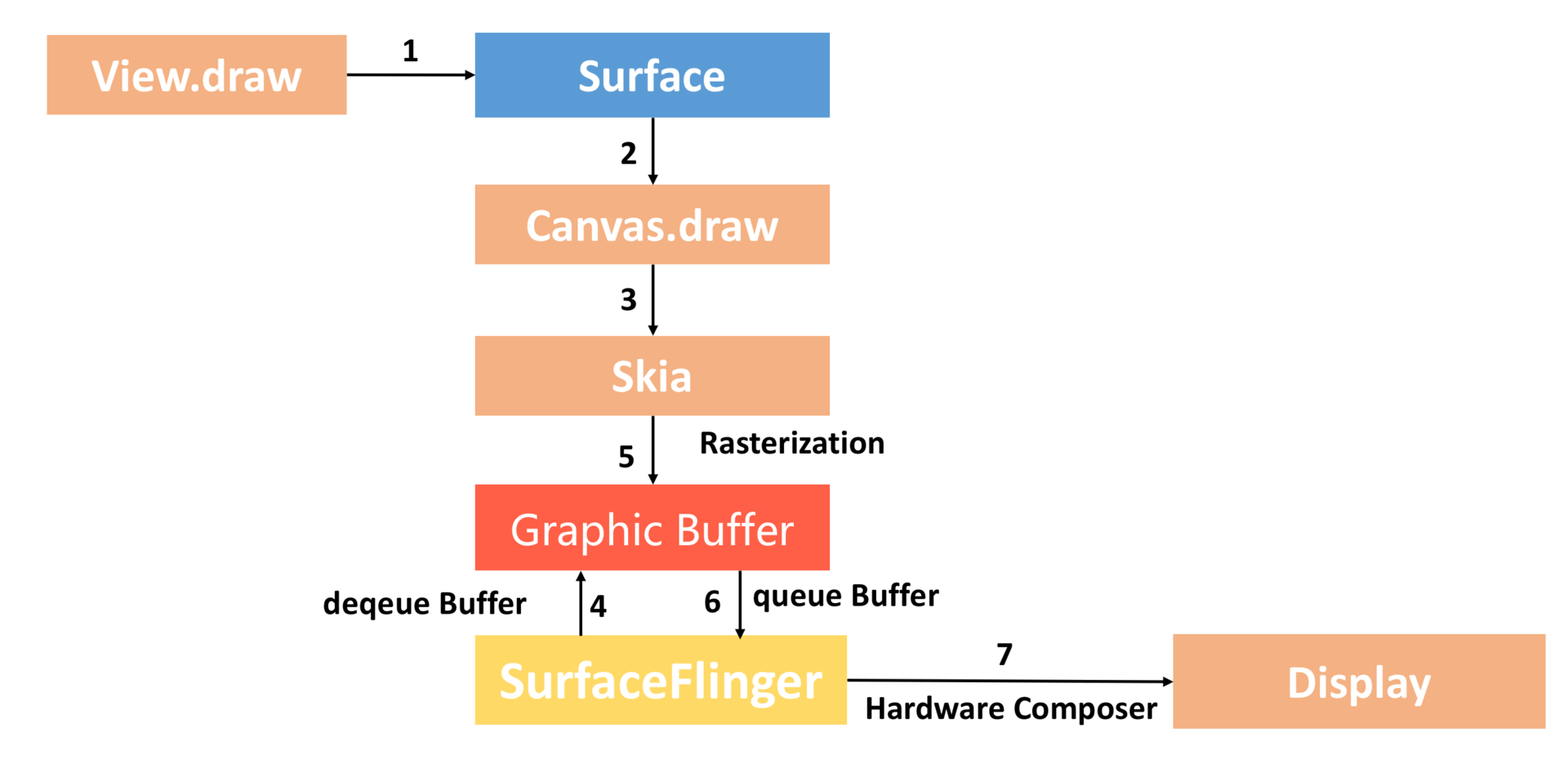
- Surface: 每个View 都由某个Window 管理,每个Window 关联一个Surface
- Cavas。通过Surface的lock 函数获得一个Cavas,Cavas 可以理解成Skia 底层接口的封装
- Grapic Buffer。 SurfaceFlinger 帮我们托管 BufferQueue ,我们从BufferQueue 中拿到 Graphic Buffer,然后通过Canvas 和 Skia 将绘制内容栅格化到上面(个人理解为栅格化后的数据保存在这个buffer中)。
- SurfaceFlinger 。通过 Swap Buffer 把 Front Graphic Buffer 的内容交给 SurfaceFlinger ,最后硬件合成器 Hardware Composer 合成并输出到显示屏。
硬件加速绘制流程如下图(3.0以后支持硬件加速):
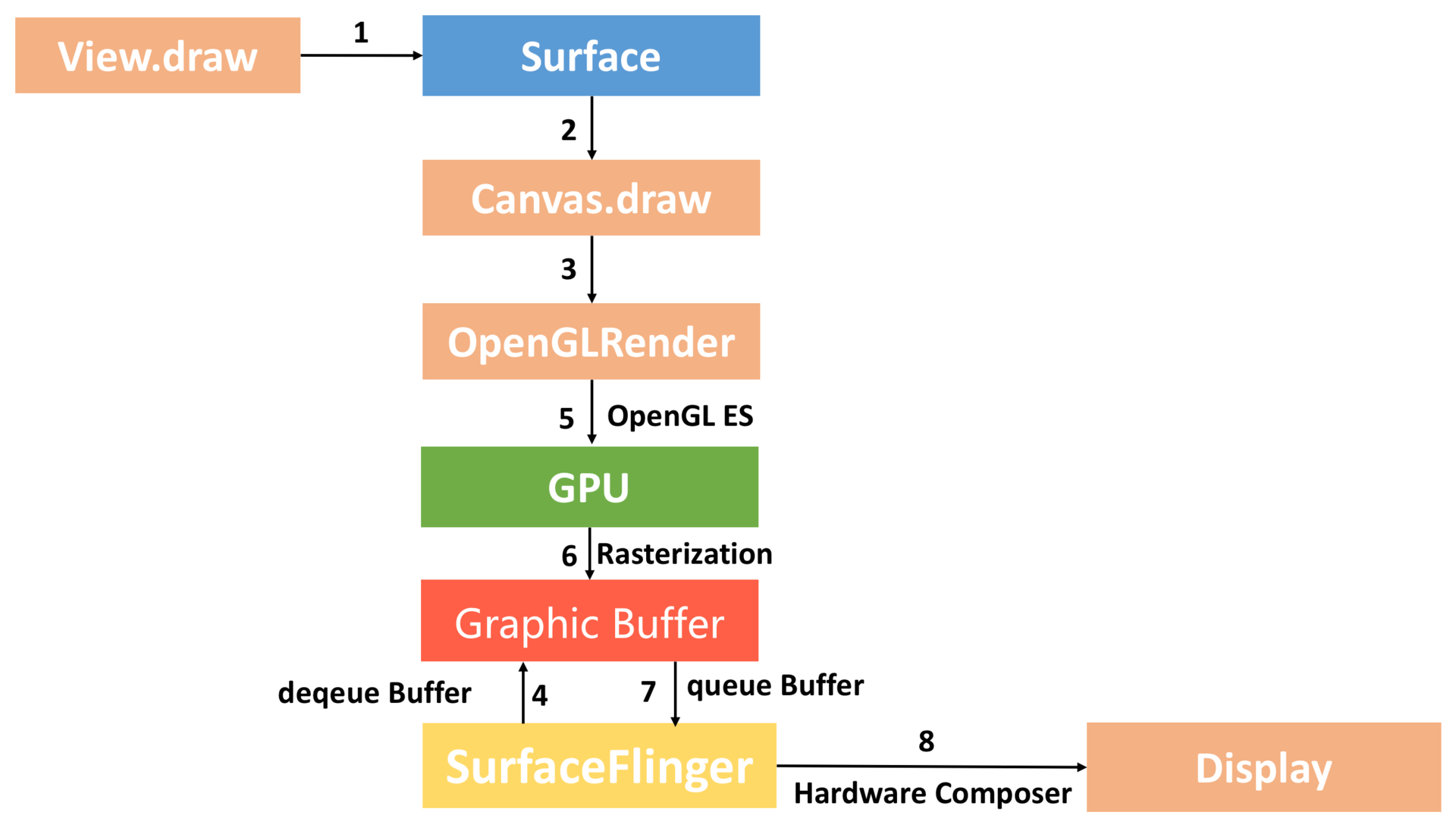
硬件绘制与软件绘制最核心的区别是硬件绘制通过GPU完成 Graphic Buffer内容的绘制,此外,硬件绘制引入了 DisplayList 的概念,每个View内部都有一个DisplayList,当某个View需要重绘时,将其标记为Dirty,重绘也仅仅只需要重绘一个View的DisplayList,这样,无需像软件绘制那样向上递归,大大减少绘图的操作数量,提高了渲染效率,更新的过程示意如下:
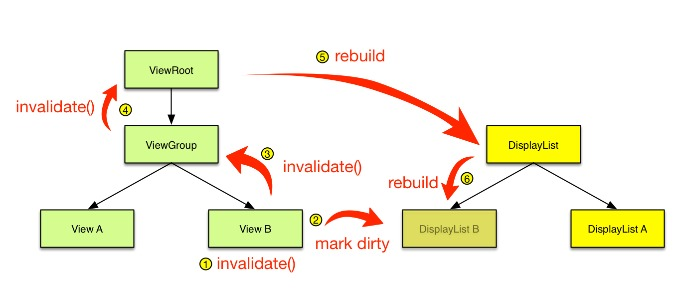
硬件加速虽然极大地提高了显示和刷新速度,但是它也存在一些问题,一方面是内存消耗,另一方面是部分绘制函数不支持
Project Butter (黄油计划)
4.1的时候,提出黄油计划,主要包括两个方面,一是 VSYNC ,一是 Triple Bufferfing (三缓冲)。
在4.0 及以前,cpu可能在忙别的事情,导致没来得及处理UI 绘制,为了解决这个问题,VSYNC 出现了,它类似于时钟中断,这个信号到来时,CPU立即准备Buffer数据,大部分设备刷新频率都是60Hz,所以一帧数据的准备工作要在 16ms内完成。
4.0及以前,Android使用双缓冲,一般不同的View或者Activity 都会公用一个Window,也就是公用一个Surface,每个Surface 会有一个BufferQueue 缓存队列,这个队列由SurfaceFlinger 管理,通过匿名共享内存与App应用层交互。示意图如下:
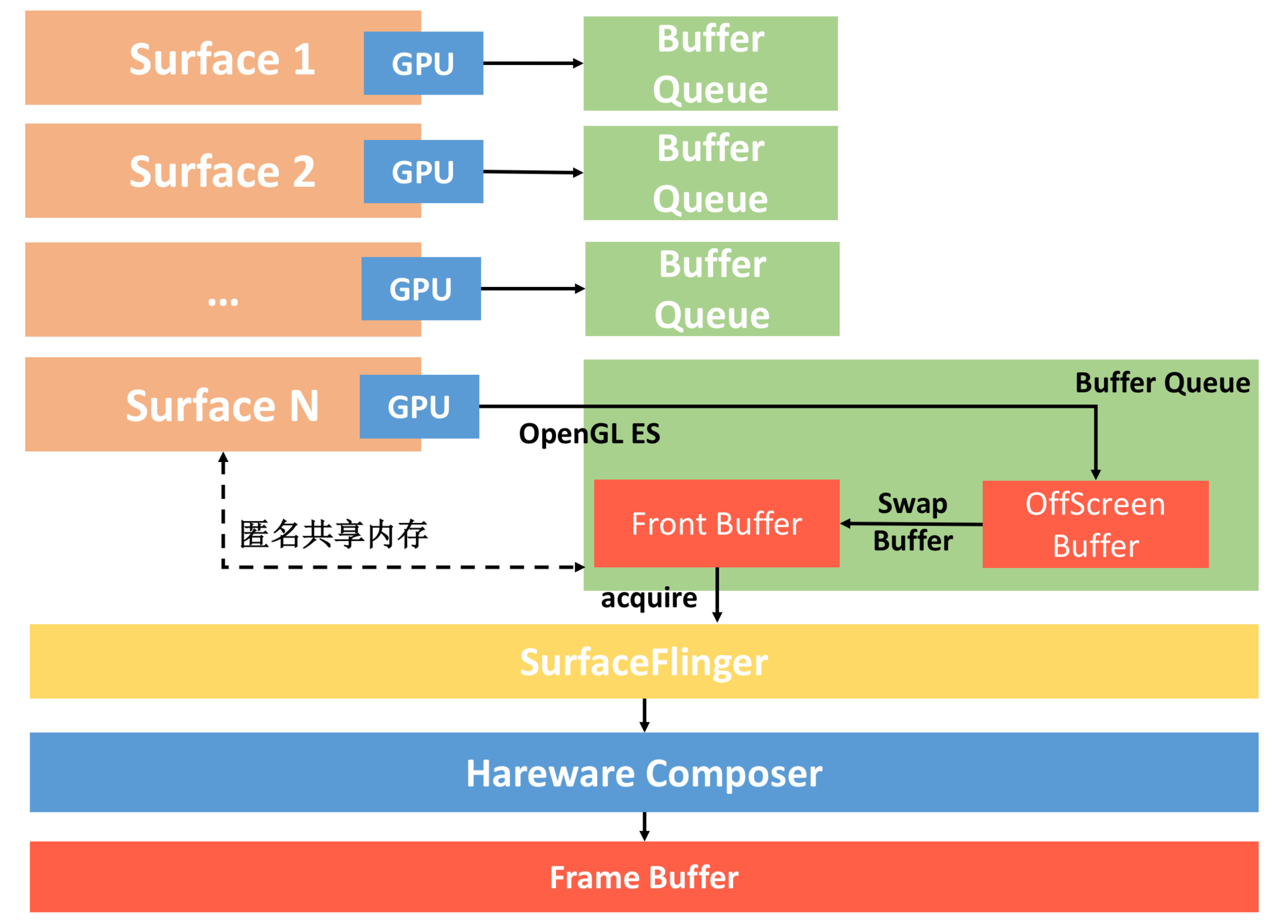
整个流程如下:
每个Surface对应的 BufferQueue 内有有两个Graphic Buffer,一个用于绘制,一个用于显示。
同一时刻可能有多个Surface (可能是不同应用的Surface,也可能是同一个应用里面类似SurfaceView 和TexureView ,它们都会有自己单独的Surface),SurfaceFlinger 把所有的Surface 要显示的内容统一交给 Hardware Composer,它会最终合成屏幕显示的内容。
如果只有两个Buffer,当CPU/GPU 绘制时间过长,则两个缓冲区分别被显示设备和GPU 占用,cpu 无法准备下一帧数据,造成浪费。三个缓冲区的话,cpu、gpu 显示设备都能使用各自的缓冲区工作,个不影响,最大限度利用空闲时间。
在黄油计划之后,Android 5.0 推出了 RenderThread ,将所有GL 命令执行放到 RenderThread 中执行,减轻UI 线程的负担。
数据测量
可以通过开发者选项中查看过度绘制的情况
还可以使用 Systrace 性能数据采样和分析工具
4.1及以后,可以采用 Tracer for OpenGL ES 逐帧分析
