Java的基础容器主要有 List、Set、Queue、Map 四大类,但是大家熟知的 ArrayList、LinkedList 、HashMap 等都不是线程安全的。为了解决安全问题,Java用内置锁提供了一套线程安全的同步容器类,但是效率不高;因此,JUC提供了一套高并发容器。
7.1 线程安全的同步容器类
Java 同步容器类通过 synchronized 来实现同步的容器,比如 HashTable、Vector 以及 SynchronizedList 等容器,另外,Java 还提供了一组包装方法,将一个普通的基础容器包装成线程安全的同步容器,例如通过 Collections.synchronizedMap() 包装方法能将Map 包装成线程安全的 Map,看代码就能知道其原理:
1 | //java.util.Collections |
通过上述代码可以看出,Collections 提供的包装方法实现步骤:首先实现了容器的操作接口,在操作接口上使用 synchronized 进行线程同步,然后在 synchronized 临界区将实际的操作委托给被包装的基础容器。
7.1.1 同步容器面临的问题
由前面的描述可知:同步容器实现线程安全的方式是(包括HashTable之类的以及 Collections包装类之类的)*在需要同步访问的方法上添加关键字 synchonized *。所以效率并不高。
7.2 JUC 高并发容器
为了解决同步容器的性能问题,有了 JUC 高并发容器。高并发容器是基于非阻塞算法(也说无锁编程算法)实现的容器类,主要通过 CAS(Compare And Swap) + volatile 组合实现,其中 CAS 保证原子性,volatile 保证可见性。其主要优点如下:
- 开销小:无需在内核态和用户态来回切换
- 读写不互斥: 读读操作之间可以不互斥,只有写操作需要使用基于 CAS 机制的乐观锁
7.3 CopyOnWriteArrayList
很多应用场景读操作可能会远远大于写操作,由于读操作不会修改原有数据,因此每次读取都要加锁其实是一种浪费。
7.3.2 CopyOnWriteArrayList 原理
CopyOnWrite(写时复制)就是在修改器对一块内存进行修改时,不直接在原有内存块上进行写操作,而是将内存复制一份,在新的内存中进行写操作,写完之后,再将原来的指针(引用)指向新的内存,原来的内存GC 。CopyOnWriteArrayList 的核心成员如下:
1 | public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable,Serializable { |
7.3.3 CopyOnWriteArrayList 的读取操作
读取操作没有任何同步操作和锁控制,理由是内部数组array 不会发生修改,只会被另一个 array 替换,因此可以保证数据安全:
1 | /** 操作内存的引用*/ |
7.3.4 CopyOnWriteArrayList 写入操作
写入操作 add() 方法在执行时加了独占锁以确保只能有一个线程进行写入操作:
1 | public boolean add(E e) { |
每次进行添加操作时,都会重新复制一份数组,再往新数组中添加元素,添加完了,再将array 引用指向新的数组。也就是当add() 操作完成后,array 的引用就已经指向新的存储空间了。
7.3.5 CopyOnWriteArrayList 优缺点以及对比(自己加的章节)
7.3.5.1 优缺点(自己加的章节)
- 优点:高并发操作下读取、遍历操作不需要同步,速度非常快,适用于“读多写少“的场景
- 缺点: 每次添加要复制一份,增加内存开销
7.3.5.2 比较(自己加的章节)
CopyOnWriteArrayList 和 ReentrantReadWriteLock (读写锁) 的思想非常类似,ReentrantReadWriteLock 的泗县时:读读共享、写写互斥、读写互斥、写读互斥,而 CopyOnWriteArrayList 更进一步了:为了将读取的性能发挥到极致,读取时完全不加锁。
7.4 BlockingQueue
在多线程环境中,通过 BlockingQueue (阻塞队列) 可以很容易实现多线程之间的数据共享和通信,比如在经典的“生产者-消费者“模型中,通过 BlockingQueue 可以完成一个高性能版本。
7.4.3 常见的 BlockingQueue
BlockingQueue 的实现类大概有 :ArrayBlockingQueue、DelayQueue、LinkedBlockingDeque、
PriorityBlockingQueue、SynchronousQueue等。
7.4.3.1 ArrayBlockingQueue
ArrayBlockingQueue 内部采用定长数组来存储元素,添加和删除操作采用同一个锁对象,也就是说添加和删除无法并行运行(为什么不能并行呢?因为作者认为ArrayBlockingQueue的写入和获取操作已经足够轻量了)。
为什么 ArrayBlockingQueue 比 LinkedBlockingQueue 更加常用?因为前者添加或者删除的时候不会产生或者销毁任何额外的 Node 实例,在高并发场景下,这可以减轻系统 GC 压力
7.4.3.2 LinkedBlockingQueue
LinkedBlockingQueue 是基于链表的阻塞队列,对于添加和删除元素分别才用了独立的锁控制,也就是在高并发场景下,消费者和生产者可以并行地操作队列中数据。
需要注意的是,新建 LinkedBlockingQueue 时如果没有指定其容量大小,则默认大小近乎无限(Integer.MAX_VALUE),这样的话,一旦生产速度大于消费速度,也许还没等到队列满阻塞产生,系统内存就消耗光了。
7.4.3.3 DelayQueue
DelayQueue 只有当其指定的延迟时间到了才能够从队列中取该元素,它是一个没有大小限制的队列,因此添加(生产者)永远不会被阻塞,只有获取数据(消费者)才会被阻塞。
DelayQueue 的适用场景较少,常见的例子是用来管理一个超时未响应的连接队列
7.4.3.4 PriorityBlockingQueue
PriorityBlockingQueue 和 DelayQueue 类似,它也不会阻塞生产者,只会在没有可消费的数据时阻塞消费者。
7.4.3.5 SynchronousQueue
SynchronousQueue 是一种无缓冲的等待队列,不像 LinkedBlockingQueue 有中间缓冲区,所以吞吐率相对而言会低一些。不过对于单个任务来说,正因为没有缓冲区,所以响应会快一些。
LinkedBlockingQueue、DelayQueue 以及 PriorityBlockingQueue 都需要注意生产速度不能快于消费者,否则容易耗光内存。
7.4.4 ArrayBlockingQueue 的基本使用
用 ArrayBlockingQueue 队列实现一个生产者-消费者的案例:
1 | // 省略import |
7.4.6 非阻塞式添加元素 add()、offer() 方法的原理
首先来看非阻塞式添加元素,在队列满而不能添加元素时,非阻塞式添加元素的方法会立即返回,所以线程不会被阻塞。add() 方法的实现如下:
1 | public boolean add(E e) { |
可以看出直接调用了 offer 方法,如果 offer 方法添加失败,直接抛出异常,否则返回true。
offer() 方法的实现:
1 | //offer()方法 |
可以看到,offer() 方法的操作如下:
- 如果数组满了,就直接释放锁,返回false
- 数组没满,将元素加入队(通过enqueue()方法)然后返回true
7.4.7 阻塞式添加元素:put() 方法的原理
put() 方法是一个阻塞方法,如果队列元素已满,那么当前线程会被加入 notFull 条件等待队列中,直到有空位置才会被唤醒执行添加操作:
1 | //put()方法,阻塞时可中断 |
总结一下put()流程:
- 获取 putLock 锁
- 如果队列满了,就被阻塞,put线程进入 notFull 等待队列,等着被唤醒
- 如果队列未满,通过 enqueue 方法入队
- 释放 putLock 锁
7.4.8 非阻塞式删除元素: poll() 方法
当队列空而不能删除元素时,非阻塞删除元素的方法会立即返回,执行线程不会被阻塞。poll() 方法实现:
1 | public E poll() { |
里面使用了 dequeue() 方法出队:
1 | //删除队列头元素并返回 |
主要注意后面的通过 notFull.signal() 唤醒条件等待队列中的一个 put 线程。阻塞式的 take() 方法略。
7.5 ConcurrentHashMap
在 Java 7 之前版本 ConcurrentHashMap 采用分段锁实现,数据分为一段一段的,每段分配一把锁,当一个线程访问其中一段数据的时候,其他段的数据能被正常访问,实现了真正的并发访问;Java8对内部存储结构进行了优化,性能进一步提升。
7.5.1 HashMap 和 HashTable 的问题
HashMap 不是线程安全的,多线程环境下,HashMap 的 put() 操作可能会引起死循环,导致CPU使用率接近100%。于是JDK提供了线程安全的Map-HashTable,它使用几乎与 HashMap 几乎一样区别有2点:
- HashTable 不允许key 和value 为null
- HashTable 的包括 get/set 在内的方法都是用 synchronized 来保证线程安全,对整个 Hash 表锁定,但是代价会非常大的
7.5.2 Java 1.7 及以前版本的 ConcurrentHashMap
分段锁是一种锁设计,并不是具体的锁。对于 ConcurrentHashMap 而言,分段锁技术将 key 分成一个个小 segment 存储,给每段数据一把锁,当一个线程占用锁访问其中一段数据时,其他段数据也能被其他线程访问,实现真正的并发。
这个原理已经比较了解了,这里就不按照书本的章节走,略过了
7.5.4 JDK 1.8版本 ConcurrentHashMap 的结构
1.7 版本虽然通过 segment 方式实现了并发热点分离,默认情况下将一个table 分裂成 16 个小的 table(Segment表示),从而在 Segment 维度实现并发。但是这样并发粒度还不够细。1.8 版本抛弃了 Segment 分段锁机制,存储结构采用数组+链表或者红黑树的组合方式,将并发粒度细化到每一个桶,进一步细化了热点,利用 CAS + Synchronized 来保证并发更新安全。
JDK 1.7 的 ConcurrentHashMap 每个桶为链表结构,1.8 引入了红黑树结构,当桶的节点超过阈值(默认64)时,自动将链表结构转换为红黑树,可以理解为将链式桶转为树状桶。这样的好处在于,访问的时候只需要对一个桶锁定,而不需要将整个 Map 集合都进行粗粒度锁定。事实上,引入红黑树的一个原因是:链表查询复杂度 O(n) ,红黑树查询复杂度 O(log(n))
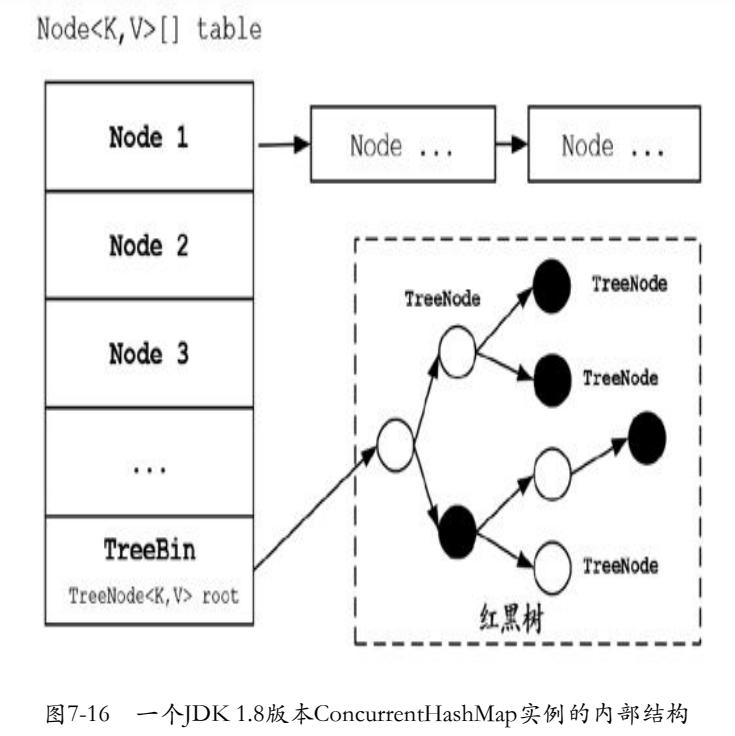
7.5.5 ConcurrentHashMap的核心原理-1.8 版本
JDK 1.8版本的ConcurrentHashMap中通过一个 Node<K,V>[] 数组table 来保存添加到哈希表中的桶,在同一个 Bucket 位置是通过链表和 红黑树的形式来保存的,但是 table 是懒加载的,只有在第一次添加元素的时候才会初始化。它的主要成员属性大致如下:
1 | public class ConcurrentHashMap<K,V> extends |
重要属性介绍如下:
- table用于保存添加到哈希表中的桶
- DEFAULT_CAPACITY: table的默认长度。默认初期长度为16,在第一次添加元素时,会将table初始化成16个元素的数组
- sizeCtl:sizeCtl用来控制table的初始化和扩容操作的过程
涉及修改 sizeCtl 的方法有 5 个:
- initTable():初始化哈希表时,涉及sizeCtl的修改
- addCount():增加容量时,涉及sizeCtl的修改
- tryPresize():ConcurrentHashMap扩容方法之一
- transfer():table数据转移到 nextTable,扩容操作的核心在于数据的转移,把旧数组中的数据前一到新的数组。ConcurrentHashMap可以利用多线程来协同扩容,简单说是把 table 数组当做多个线程之间共享的任务队列,然后通过维护一个指针来划分每个线程锁负责的取件,一个已经迁移完的 Bucket 会被替换为一个 ForwardingNode 节点,标记当前 Bucket 已经被其他线程迁移完成。
- helpTransfer():并发添加元素时,如果正在扩容,其他线程会帮助扩容,也就是多线程扩容。
7.5.6 JDK 1.8 版本 ConcurrentHashMap的核心源码
下面来看JDK 1.8版本ConcurrentHashMap的put()操作:
1 | public V put(K key, V value) { |
从源码可以看出,使用 CAS 自旋完成桶的设置时,使用 synchronized 内置锁保证桶内并发操作的线程安全。尽管对同一个 Map 操作的线程争夺会非常激烈,但是在同一个桶内的线程争夺通常不会很激烈,所以使用 CAS 自旋、synchronized 的偏向锁或轻量级锁 不会降低 ConcurrentHashMap 的性能。为什么不用显式锁 ReentrantLock 呢?因为如果为每个桶都创建一个 ReentrantLock 实例,就会带来大量的内存消耗,而前面那些方法带来的内存消耗微乎其微。
get方法也没有加锁操作,与 JDK1.7差不多,就不赘述了。
