一、Java 程序执行过程
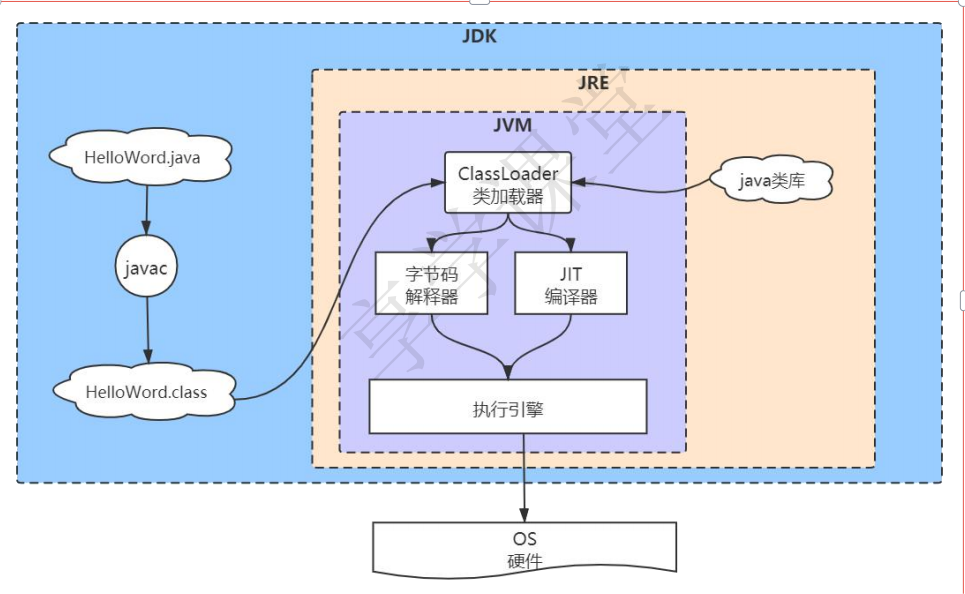
二、JVM 规范
Java 在 JVM 上经过 ClassLoader 加载后,有 2 种执行方式:
字节码解释器解释执行。Java 先编译成 class 文件,再由 C++ 解释器
JIT执行:HotSpot 就这样执行,将Java 代码翻译成汇编等形式的机器码,速度较快
JVM 是 C++ 写的,它解释执行是怎么解释呢?它碰到你 Java 代码中的 new 关键字的时候,它就执行某一段 C ++ 代码,类似:
1 | if(碰到了new) { |
也就是通过 C++ 来翻译 Java 语言。这经过了一道转换,效率是有点低的。
JIT 执行,直接将Java 代码翻译成汇编代码等机器代码,就能迅速执行。不过一般只有热点代码才这样做。缺点是,你要先提前翻译,编译的时间会比较长。
2.1 运行时数据区域
直接内存:没有经过 JVM 的虚拟化。比如总共有 8G 的存储空间,JVM 虚拟化了 6G ,但是还剩下 2G 我们没法去通过 JVM 使用,这时候就能用直接内存去使用这 2G 空间。
优点是不受 JVM 管理,不会受到 GC 影响,毕竟 GC 会Stop The World;缺点同样明显,就是使用不方便,自己申请,用完要记得释放,否则造成内存泄漏。
虚拟机栈的大小在不同的平台上的大小是不同的,在 Linux 上一般是 1M 。如果是死递归,不断往虚拟机栈压入栈帧,讲道理会将这个栈空间耗尽,不过现实中往往先 StackOverFlow。
一个线程光这个虚拟机栈就占了 1M 的空间,如果有500 个线程,那么占用的空间也是非常可观的,所以我们也要控制线程数量。
每个栈帧里面会包含什么呢? 一般是:
局部变量表
操作数栈
动态链接
完成出口
可能这些概念不太好懂,举个例子,看下面的代码:
1 | public class Person { |
上述代码在执行 main 方法的时候,会为 main 线程创建一个虚拟机栈,调用一个方法就会创建一个栈帧,所以 main 方法会有一个栈帧,调用 person.work 的时候也会创建一个栈帧。整个过程大体上会有如下操作:
x 和 y 都被定义了,但是还没使用,所以压入局部变量表中
执行 (x+y) * 10 的操作时,先计算 x + y = 3, 将 3 这个临时值放入操作数栈
之后,将操作数 10 也压入操作数栈的栈顶
接着, 操作数栈中的 3 和 10 都出栈,相乘得到结果 30 ,再压入 操作数栈 中
因为这里定义是 z 局部变量接受这个结果,所以需要将操作数栈中的 30 出栈,在局部变量表中放入 z 这个值 30
最后要返回 z ,方法与方法之间操作,这个返回值相当于一个操作数,所以又要将 z 这个 30 值复制到 操作数栈中
最后,带着 work 方法栈帧中操作数栈的这个 30 ,返回了 main 方法的 栈帧。
这里有个点需要注意下,构造方法也是方法,所以也会有栈帧
这个过程一直伴随着程序计数器的不断移动。至于完成出口,是记录调用方执行到哪里之后再来调用当前方法的,上述main 方法中 ,假如 是main 方法自己执行到行号 2 的时候就调用 person.work 了,此时,work 方法中记录的程序出口就是这个行号2,work 方法执行完,切回main 方法时, 会把这个值带回去,这样便知道从哪里继续执行。来看一下下面的这张图,这是字节码:
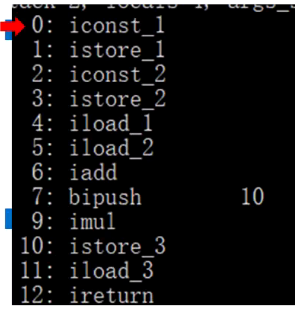
左边的就是 0,1,2…12 ,这些代表行号,也代表字节码的偏移量,有些指令比较短,有些比较长,会占据不止一行,所以,行号可能会跳过,上面的图中没有 8 这个行号,就是因为 bipush 指令比较大;右边的代表操作。非静态方法的局部变量表的第 0 个位置存的是 this ,也就是当前的对象。
动态链接 主要是跟多态有关。本地方法栈和虚拟机栈是可以合并的, HotSpot 就是这么做的。
三、课堂问题
课程中 demo 搞出来个 stackoverflow ,这个值得注意:
1 | public class Person { |
因为在 main 方法中 wo 来new Person 的对象时, 就会触发 haha 的又来 new 一个 new Person 对象,就会陷入死循环了。
四、直接内存
如果想使用直接内存,可以通过 ByteBuffer 来实现,这样可以被回收:
1 | public static void main(String[] args) throws Exception { |
ByteBuffer 是使用 unsafe 来实现的。
五、工具
使用 HSDB 查看 JVM 中的各个对象,能通过指定类和里面的对象,就能看到。
