一、分而治之思想
算法中分而治之思想和动态规划思想有点类似,要注意区分:
分而治之: 将一个任务分割成很多小任务,并且各个任务之间无关联
动态规划: 将一个任务 A 分割成很多小任务,比如 a1、a2、a3 ,假如存在 a1 执行完成才能执行a3,那就是小任务有关联性了,这就是动态规划思想了
快排,归并,二分都是分而治之的思想。
在 Java 7 中提供了 Fork/Join 工具(Fork:将任务拆分成很多独立的子任务;Join:将所有的子任务结果合并)来让分而治之的思想并发执行起来。当然,我们也可以不使用这个框架,自己将任务分成很多小任务,然后用多线程去执行。不过呢,Java 的 ForkJoin 给提供了工作窃取(work-stealing) 算法,能够让执行更高效。
2.1 工作窃取
工作窃取(work-stealing) 简单来说就是空闲线程试图从繁忙线程的 deques 中窃取工作。
默认情况下,每个工作线程从自己的双端队列中获取任务,但如果自己队列中任务已经执行完成,队列为空时,它就会从另一个繁忙线程的双端队列尾部或者全局入口队列中获取任务,因为这是最大概率可能找到工作的地方。
为什么会有任务先执行完成呢?因为工作量的划分不一定均等。即使是相同数量的数字相加,比如,每个任务都是10个数字相加,如果数字很大的话,耗时也会很长。
二、Java 提供的 ForkJoin
Java 提供分而治之的框架: ForkJoin。既然是要提交任务,我们需要对任务进行封装,ForkJoin 提供了 ForkJoinTask
1 | public abstract class ForkJoinTask<V> implements Future<V>, Serializable |
不过一般不直接使用它,而是用它的 2 个主要的子类:
1 | public abstract class RecursiveTask<V> extends ForkJoinTask<V> |
从这 2 个子类我们能看出,RecursiveTask 更适合有返回值的情形;RecursiveAction 适合没有返回值的情形。ForkJoinTask 它有2种使用方法:
同步用法:采用 invoke 来提交任务
异步用法:采用submit 或者 execute 方法来提交任务
使用 ForkJoin 的方法如下:
1 | public static void main(String[] args) { |
其中,makeArray 只是用来生成一个数组:
1 | public class MakeArray { |
真正的任务代码,由于我们需要有返回值,所以我们继承了 RecursiveTask :
1 | public class SumTask extends RecursiveTask<Integer> { |
在重写的 compute 方法中,我们不断拆分任务,直至任务满足我们定义的阈值位置。计算量越大,中途 IO 操作越多 或者 休眠时间越多, ForkJoin 的优势越明显。如果只是少量数据,那么由于:
ForkJoin 的递归调用
ForkJoin 多线程切换
反而导致还没单线程那么快。但是当计算过程中有IO 操作或者休眠时间时,ForkJoin 在大量数据情况下的优势就会显示出来。我们注意上述代码中注释的代码 : Thread.sleep(1); 如果在单线程计算和 ForkJoin 计算过程中都休眠 1ms ,后续导致的耗时差异是很大的,这个可以自行验证。
上面我们看了同步的操作,接下来看下如果进行异步操作,以下代码将根据指定的文件中,所有的 txt 文件,有可能文件下还有目录:
1 | public static void main(String[] args) throws Exception { |
首先 main 方法中调用与上述的同步差不多,只不过在使用 execute 异步调用后,主线程的日志和子线程的日志同时在打,最后,我们会调用 task.join 阻塞方法,这也导致当所有文件遍历完成后,才会在main 线程中 输出最后的 task end 语句。我们看下 FindDirFiles 的实现:
1 | public class FindDirFiles extends RecursiveAction { |
由于不需要返回结果,所以我们继承 RecursiveAction 即可,在 compute 中,我们将为每个目录创建一个 Task 加入 list 中,最后一并 invokeAll 执行。
三、CountDownLatch
它的作用是等待一个线程或者多个线程执行完成后再执行后续的操作。比如说要等所有的初始化工作(多个子线程)执行完成之后,才进入主线程执行。
对于 CountDownLatch 而言,计数器和线程数量是没关系的,有可能在同一个线程中做 2 个任务执行 2 次 countDown 操作。
线程做完 countDown 操作之后,能够继续执行,并不是说一定就要关闭之类的。
CountdownLatch 的 await 方法(即等待所有的扣减到 0 后才能执行的地方)可以在多个地方使用,比如同时在 主线程调用 countDownLatch.await() 以及在某个子线程中调用 countDownLatch.await() ,当 countDownLatch 计数器减为 0 的时候,主线程和那个子线程都会被唤醒接着执行。
四、CyclicBarrier
它的主要思想是,在某个点设置一个屏障, 比如 3 个线程,如果 A 线程先执行完成,它会 await 在那里等待;同样 B 线程也会这样,一直到 C 线程也执行完成,此时,3个线程才一起执行。它有 2 个主要构造方法:
1 | //parties 表示操控的线程数量 |
以及:
1 | public CyclicBarrier(int parties, Runnable barrierAction) { |
其中第二个 构造方法的 barrierAction 表示的是,当所有的操控的线程都执行到这个屏障的时候,此时优先执行一下这个 Rnnable ,之后三个线程才继续执行。这样做的一个好处就是:
举个例子吧,如果3 个线程计算一个任务的 3 个部分,这时候,我们可以用设置这个 Runnable 来合并这 3 部分结果,之后,这 3 个线程都拿着合并后的结果执行后面的操作。
五、CountDownLatch 与 CyclicBarrier 的区别
虽然二者在功能上很相似,但其实是有很大区别的,主要体现在:
CountDownLatch 定义的数字只能扣减一次,CyclicBarrier 能多次调用 await ,后续的 await 还都能触发 barrierAction 的执行
CountDownLatch 用外部线程协调;而 CyclicBarrier 本身相互协调
CountDownLatch 扣减数和线程数不一样,比如一个线程可以 countdown 多次;但 CyclicBarrier 初始化时传入的 数量必须是管控的线程数量
这点没大听懂,大体是说 CountDownLatch 运行中不允许其他线程执行;而CyclicBarrier 可以通过 barrierAction 执行其他线程任务。还需要额外确认这点
六、Semaphore
主要用于流控的场景。比如,数据库最多只能有 10 个连接,那么我们可以通过 Semaphore 发放 10 个 许可证。在正常使用的时候通过 acquire 和 release 来控制获取和释放操作。还是看如下代码:
1 | static class ConnectionImpl implements Connection { |
接下来就是编写 Demo 使用:
1 | private static class BusiThread extends Thread { |
上述代码会显示出前面 10 个线程几乎是 0ms 就获取到资源,而后续的会等待:
Thread_Thread-1获取数据库连共耗时【0】ms
Thread_Thread-0获取数据库连共耗时【0】ms
Thread_Thread-2获取数据库连共耗时【0】ms
Thread_Thread-3获取数据库连共耗时【0】ms
Thread_Thread-4获取数据库连共耗时【0】ms
Thread_Thread-5获取数据库连共耗时【0】ms
Thread_Thread-6获取数据库连共耗时【0】ms
Thread_Thread-7获取数据库连共耗时【0】ms
Thread_Thread-8获取数据库连共耗时【0】ms
Thread_Thread-9获取数据库连共耗时【1】ms
查询数据完成,归还连接
当前有40个线程等待连接,可用连接数:0
Thread_Thread-10获取数据库连共耗时【113】ms
查询数据完成,归还连接
当前有39个线程等待连接,可用连接数:0
Thread_Thread-11获取数据库连共耗时【124】ms
查询数据完成,归还连接
当前有38个线程等待连接,可用连接数:0
Thread_Thread-12获取数据库连共耗时【141】ms。。。省略一部分运行数据
这里可能大家有个疑问,为什么需要定义 2 个 Semaphore: useful, uselessful。其中 前者是代表可用的许可,后者代表空位。为什么这么设计?还得从 Semaphore 的机制说起:即使没有调用 acquire ,而是直接调用 release ,这样也是可以的,可以在release 的时候传入一个 new 出来的Connection 对象 !!!,假如出现这种情况的话,我们的许可证会越来越多,而不是我们初衷的限制了。
acquire 只是做流控,但是不能做同步操作,比如,它有 4 个许可证,意味着可以允许 4 个线程同时去取资源,这时候我们还是需要对存储资源的池子做同步的。 所以,我们上述的代码 takeConnect() 方法中,在 acquire 之后,还需要 synchronized (pool) 操作:
1 | public Connection takeConnect() throws Exception { |
七、Exchange
Exchange 的使用场景很少。它的含义是:两个线程 A 和 B,在某一位置设定一个点,当某个先执行完了,就会等待另一个线程。当 2 个线程都执行到这个点时,二者交换数据,然后接着继续执行,没错,只是交换数据。
八、Callable 、Task
我们前面说了开启一个线程有 2 种方式:new Thread 和 new Runnable 。但是,由于 Runnable 类的 run 方法是 void 类型的,没有返回值:
1 | public interface Runnable { |
因此 Java 中给准备了 Callable 这样的类,让方法有返回值:
1 | public interface Callable<V> { |
由于Thread 中只能接收 Runnable 参数,因此 Callable 不能直接传入使用,因此就有了 Task 这种类型,可能课程中的这张图更形象一点:
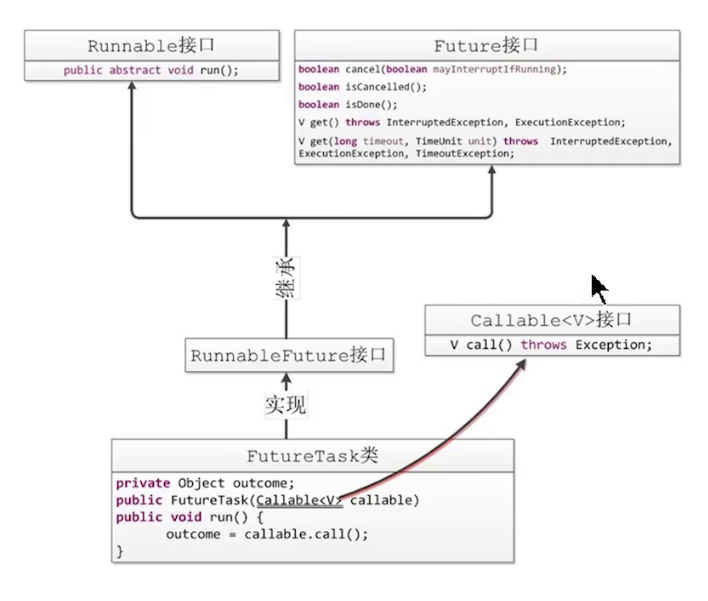
关于 Callable 的使用,我们可以参考下面的代码:
1 | public class CallableDemo { |
不过,需要注意的是,我们如果想取消 Task ,可以直接调用 task.cancel(true); ,其中传入的 true 是中断线程的标志,前面章节有说我们不建议使用 volatile 类型的变量去停止线程,还是希望使用 interrupt 去停止。所以,我们光调用 task.cancel(true);还不行,还得在线程中配合中断操作,如下所示:
1 |
|
