USS 很重要,因为这是 Uniq 的,每个进程独占的。
USS、PSS、VSS 等波动用来监测内存抖动
oom_adj 相当于进程的优先级,数值越大越容易被回收
GC Roots 有:
在线程栈中的局部变量(正在被调用的方法的参数和局部变量)
存活的线程对象
JNI引用
Class 对象(在 Android 中 Class 被加载后不会被卸载的)
引用类型的静态变量
自动化监测流程目标
自动且较为准确监测 Activity 泄漏
自动获取泄漏的 Actiivty 和 冗余Bitmap 对象的引用链
能灵活地扩展 Hprof 的分析逻辑,必要时允许提取 Hprof 文件人工分析
在监测阶段,需要 2 个问题:
activity 在执行销毁的时候,我们如何得知
如何判断一个 Activity 无法被 GC 机制回收
可以写自己写过 APM ,或者带几个人做过
我们之前说在 Activity 的 destroy 时触发GC,但是这样不怎么好,我们需要手动触发 GC ,会导致卡顿。所以,一般不使用 registerActivityCallback ,而是通过 阈值触发(如 count 计数),达到阈值时就触发GC (Koom 就是这么做的)。
常见内存泄漏原因
动画问题(在activity销毁时,调用动画的cancel 方法)
匿名内部类
InputStream/OutputStream 、cursor 等没有 close
xxx未完,后续看老师的笔记
Koom 的分析
如何将 APM 写入简历?
如果自己做过 APM 就更好,如果没有做过就将 APM 接入自己的项目中,然后收集数据,记住那些数据就OK了——路哥
1、Native Heap 泄漏监控:
主要思路是借助 Tracing Garbage Collection(一种垃圾回收算法)来进行监控,GC 回收器的 G1 回收器就是基于这个理论。
google 提供了一个 libmemunreachable 库,我们可以把所有的代码拷贝到 NDK 里面,自己打包成 so 库,就能调用这个库发现 Native 的内存泄漏了。它会告知有哪些地址可达和不可达(reachable)。
Koom 的核心监控代码都在各种 monitor 中,比如 LeakMonitor.kt 等。
爱奇艺的 xHook 能够Hook Native 代码,hook 诸如 malloc 等方法,替换成自己的 malloc 函数,这样就能监测Native 的代码行为。一旦调用了 malloc 等函数,就回调出去。
ida 这个工具可以查看某个 so 里面有哪些 api,这样就能查看它所有的方法。
koom Native 内存泄漏分析的思路:
hook malloc/free 等内存分配器方法,用于记录 Native 内存分配元数据(大小、堆栈、地址等)
周期性地使用 mark and sweep 分析整个进程 Native Heap,获取不可达的内存块信息(地址、大小)
利用不可达的内存块地址、大小等,从我们之前记录的元数据中获取其分配堆栈,产出泄漏数据(不可达内存地址、分配堆栈、大小等)
APM 在大厂都只会说原理,没法谈实战的。Android 只有APM 这个知识点可以这样。面试官问你 Koom Native层面 怎样 hook ,用 xhook,怎么知道内存泄漏的,google 官方提供的 libmemunreachable 库
profiler 里面也可以选择当前的进程,然后能看到 Leaks 就可以知道哪些泄漏的。
2、Java 内存监测思路
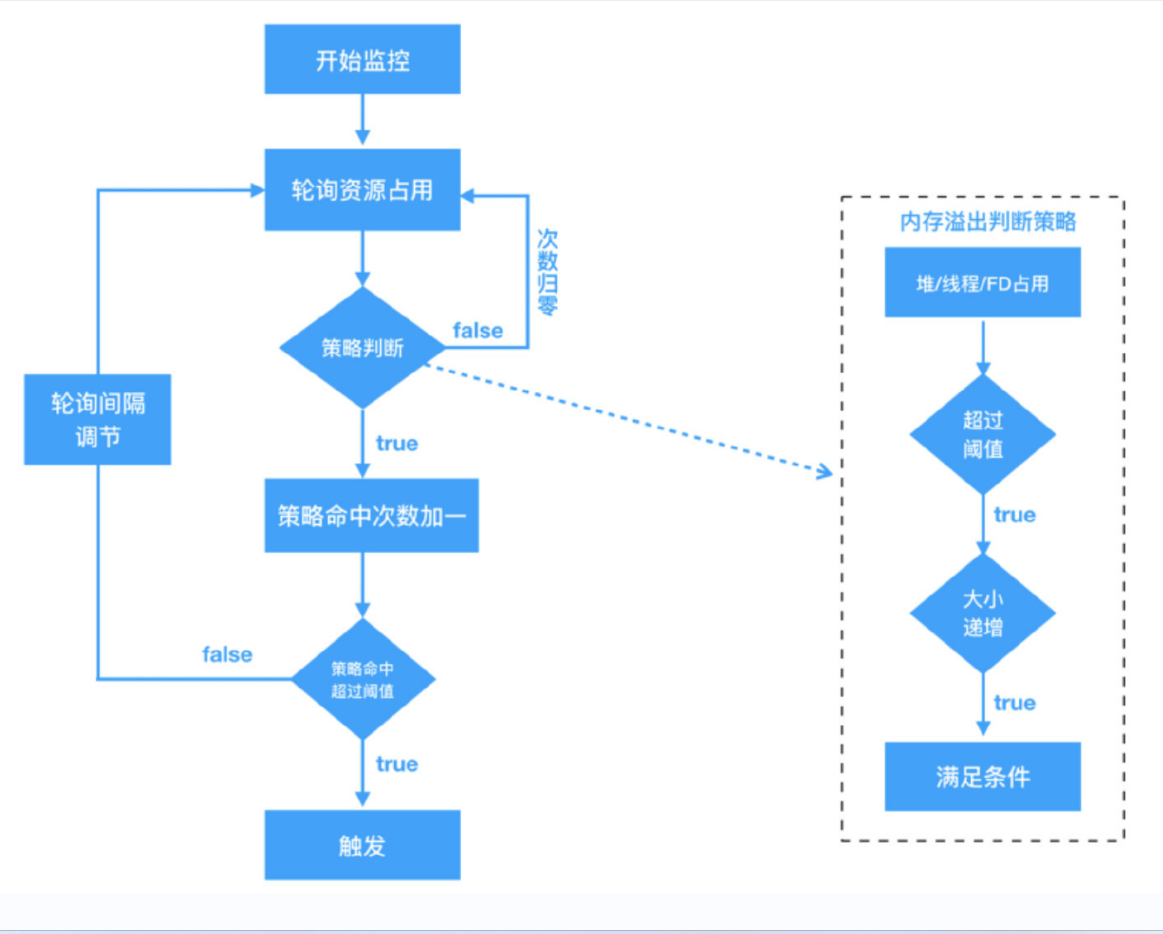
LeakCanary 采用了弱引用的特性,为Activity 创建了弱引用,但是会在 Activity 的 onDestroy 之后连续触发 2 次 GC,并检查引用队列。但是 GC 会引起用户可感知的卡顿,所以 Koom 采用了无性能损耗的内存阈值监控来触发镜像采集。
Koom 的整体流程如下图所示:
3、hprof 文件
使用以下的命令可以导出 hprof 文件:
adb shell am dumpheap
或者在Android 中采用如下代码(会暂时挂起所有线程):
1 | Debug.dumpHprofData(fileName) |
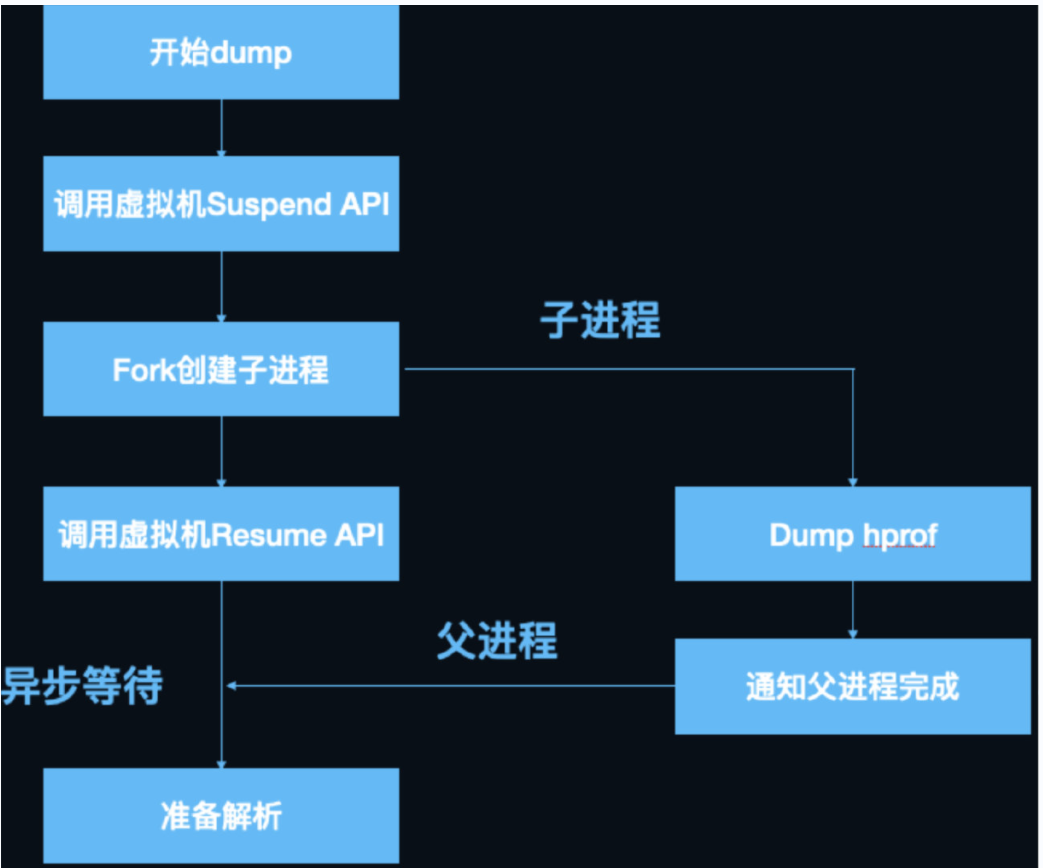
由于会暂时挂起所有的线程,所以 LeakCanary 在这个时候会非常非常卡,这也是为什么不能用于线上的一个原因。这个时候面试官可能会问,那怎么解决这个问题呢?开子线程行不行?
肯定是不行的,因为这时候挂起了所有线程,包括你的这个子线程。
解决方案:
fork 子进程去执行 dumpHprofData 方法
fork 进程采用的是 “copy On Write” 技术,只有在进行写入操作时,才会为子进程拷贝分配独立的内存空间。默认情况下,子进程可以和父进程共享同个内存空间。所以,当我们要执行dumpProfData 方法时,可以 fork 一个子进程,它拥有父进程的内存副本,然后在子进程中取执行 dumpProfData 方法,而父进程可以正常继续运行。
这个过程的流程图如下所示:
hprof 文件很大,一般可达 1G 的规模,所以不可能直接丢给后台去分析,一般会做以下裁剪。这时候就看你具体要什么,可能不同的公司需要的不一样,但是大体上需要看 bitmap、byte 数组 byte[] 等。有个 shark 工具可以用来分析这个 hprof ,便于后续的裁剪。 我们关注的主要是 三类 信息:
字符串信息,保存着所有的字符串,在解析时可以通过索引id引用
类的结构信息:包括类内部的变量布局、父类信息等
堆信息:内存占用与对象引用的详细信息
裁剪的主要思路如下:
读取 Hprof 文件
记录 Bitmap 和 String 类信息
移除 Bitmap buffer 和 String value 之外的基础类型数组
将同一个图片的 Bitmap buffer 指向同一个 buffer id,移除重复的 Bitmap buffer
其他数据原封不动地输出到新文件中
性能优化里面最难的就是 内存,后续的 FPS 之类的就比较简单了。
落脚点
启动优化
apm 的 demo
