启动优化已经有很多常规手段,如只加载必要模块,延迟加载等,能取得一些效果,为什么还需要启动框架呢?
一、引言
比如在 Application 中存在很多 SDK,比如20 个,这些 SDK 存在先后顺序,如何保证按照依赖顺序并且高效地执行呢?比如下面的任务:
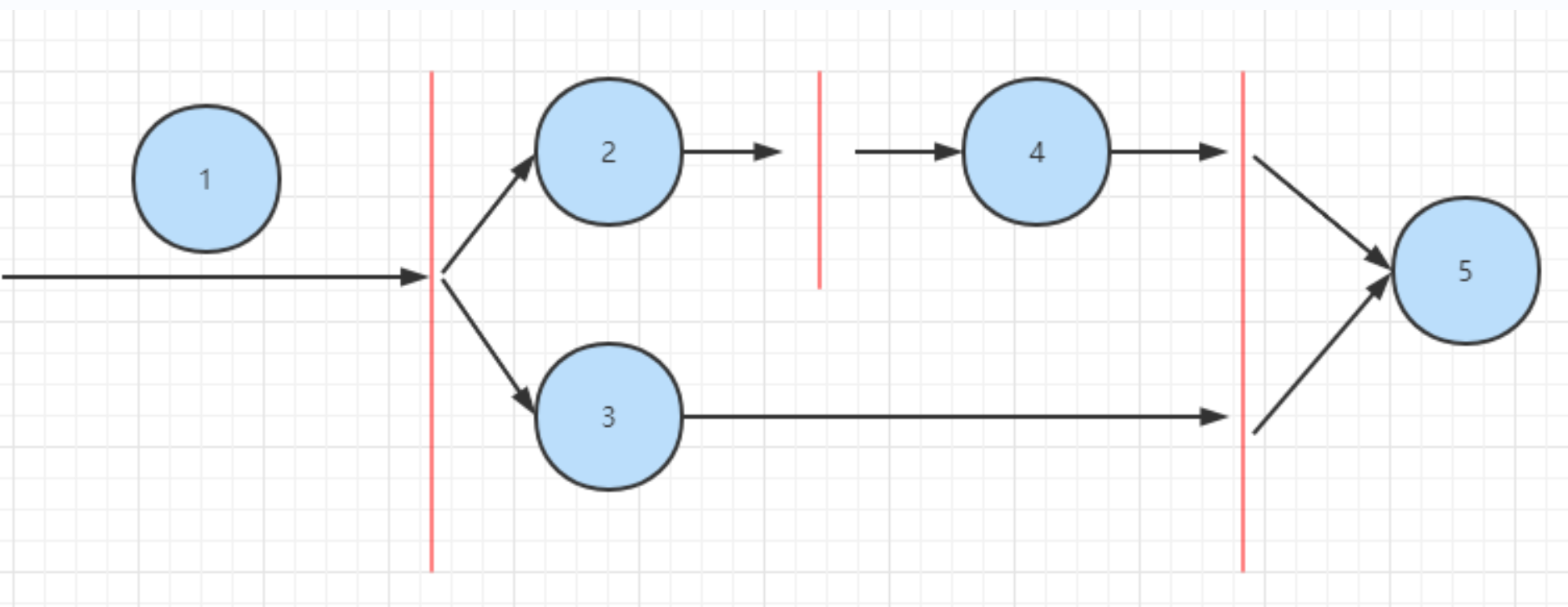
由图我们能看出相互之间的依赖:2 、3 依赖任务 1, 4 依赖任务 2 ,5 依赖 3 和 4。如果使用 Thread 去实现,会变得非常复杂。因此需要框架。
二、有向无环图
如果任务执行有方向(有序),并且没有环。在凸轮中,这种一个有向图从所有顶点出发,无论经过哪些边都不会回到这些顶点,那么就是有向无环图,简称 DAG 图。在 DAG 中:
顶点:图中的一个点,比如任务 1 ,任务 2
边:连接2个顶点的线段
入度:代表当前有多少边指向顶点(依赖多少任务)
出度:代表有多少边从顶点出发(被多少任务依赖)
三、拓扑排序
将我们的启动任务生成 DAG 图后,就要对 DAG 图做 拓扑排序,即对我们的任务启动顺序进行排序。对于前面的有向无环图而言,我们只需要保证 2、3 在 1 之后执行5 在 3、4 之后执行即可,因此我们可以得到多种排序结果:
1 -> 2 -> 3 -> 4 -> 5
1 -> 2 -> 4 -> 3 -> 5
1 -> 3 -> 2 -> 4 -> 5
也就是说,图的拓扑排序不是唯一的!
对 DAG 拓扑排序可以选择 BFS(广度优先)算法或者DFS(深度优先)算法,BFS 算法排序的过程如下:
找出图中入度为 0 的顶点
依次在图中删除这些顶点,删除后再找出入度为 0 的顶点
删除后再找出入度为 0 的顶点,重复执行第二步
基于上面的例子的拓扑排序步骤如下:
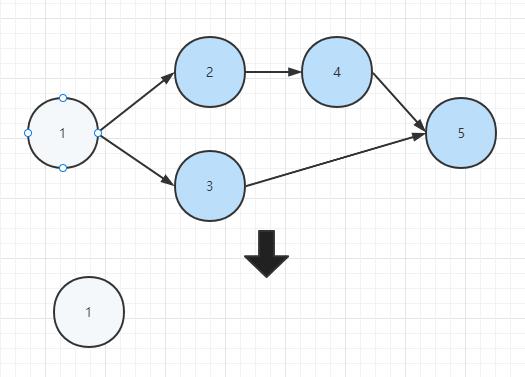
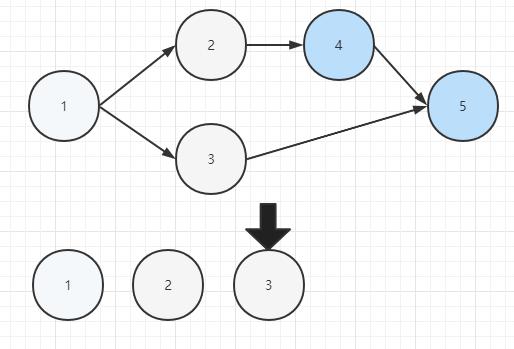
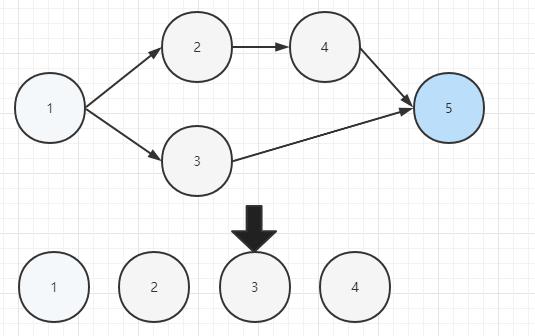
代码落地:
1 | public interface Startup<T> extends Dispatcher { |
然后,所有的任务都实现 Startup 接口。
四、线程管理
有些项目写 ConcurrentHashMap 的时候,value 不是直接使用 Object 类型,而是会使用自定义的类似 Result 类型,把原始结果封装了一层。这是什么原因呢?这是因为 ConcurrentHashMap 的 value 不能为 null ,否则会报错。如果我封装一层就能保证 Result 对象是不空的。
CountDownLatch 如果在初始化的时候,传入 0 这个数字,在下面调用 CountDownLatch.await 将不会被阻塞。
SDK中的线程比较多,或者有自己的线程池,那么有几种方法:
线程池设置成自己的线程池
反射改掉它的线程池
字节码增强技术,通过 gradle 插桩修改 SDK 的代码
如果写的 Builder ,让使用者添加 Task ,这样子在 Task 很少的时候,是很方便的,如果有 20 个,100 个的时候就头大了。这时候有什么好的办法去做?有几个方案:
使用注解,每个 Task 上都加上这个注解,然后在
使用 ContentProvider ,在 xml 中把最后的任务写在 data 中
视频中讲解的启动框架源码可以在[github开源项目中看到](android-startup/README-ch.md at master · idisfkj/android-startup · GitHub) ,这个项目比课程中的更加完善
五、问题
有个问题,为什么要先拓扑排序?
假如我们不拓扑排序,会发生什么?假如有task 5 和 6 ,都是在主线程运行,其中 6 是要等 5 结束后才能开始,假如我们不拓扑排序,此时 6 先执行,在这里阻塞了,由于阻塞,此时 5 也不能执行了,又由于在主线程,此时就 ANR 了。
