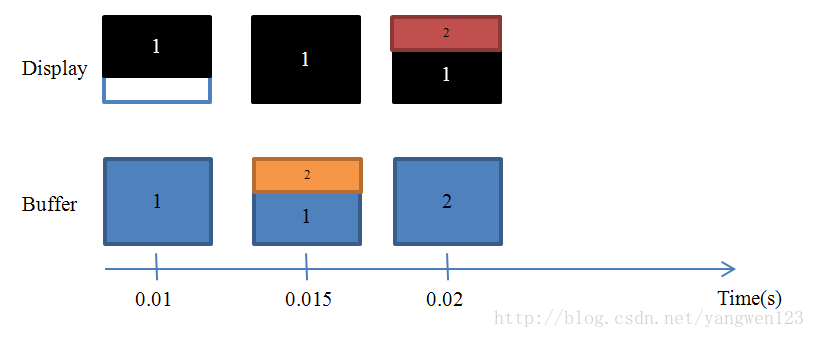
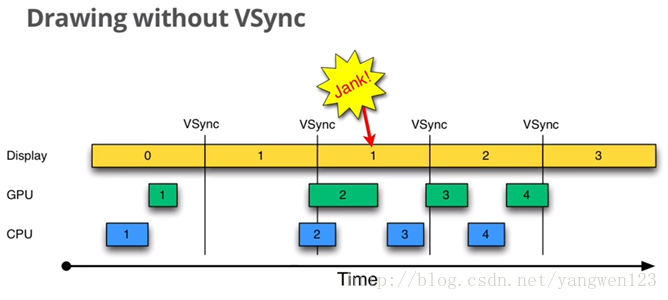
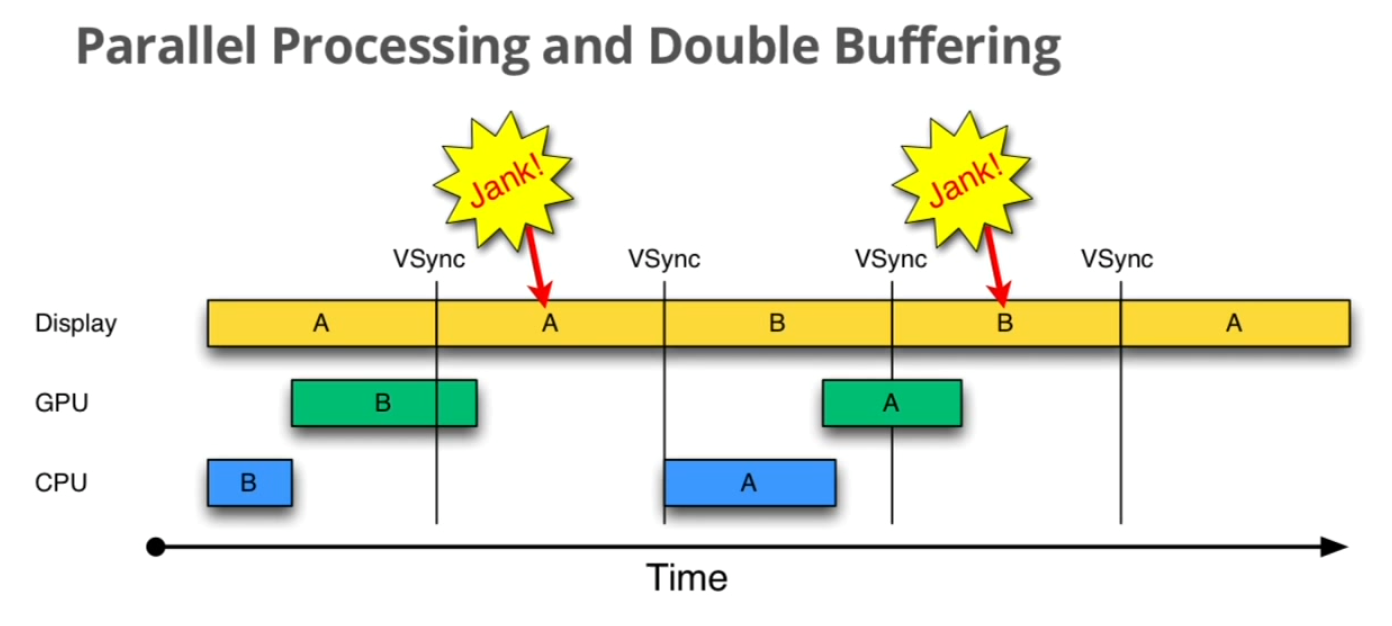
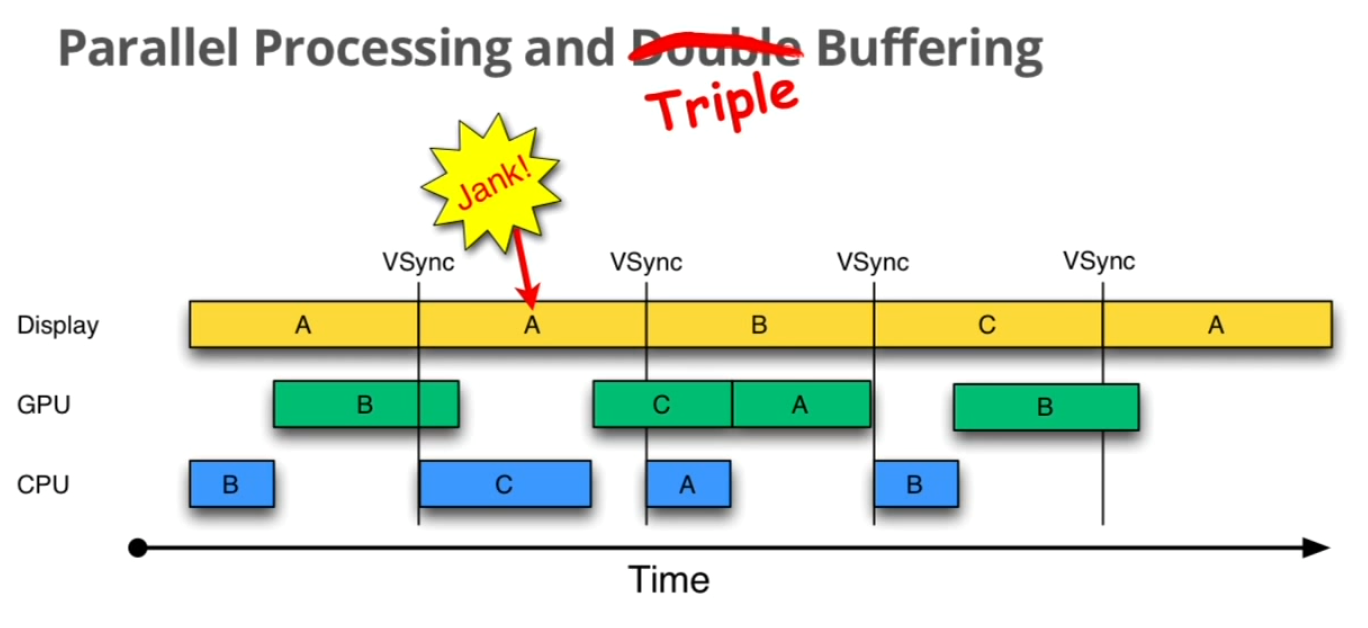
信息传递(自己起的,感觉书起的章节很乱) Android中提供了很多不同的信息传递方式,本节主要衡量每种传递方式的效率和使用场景。
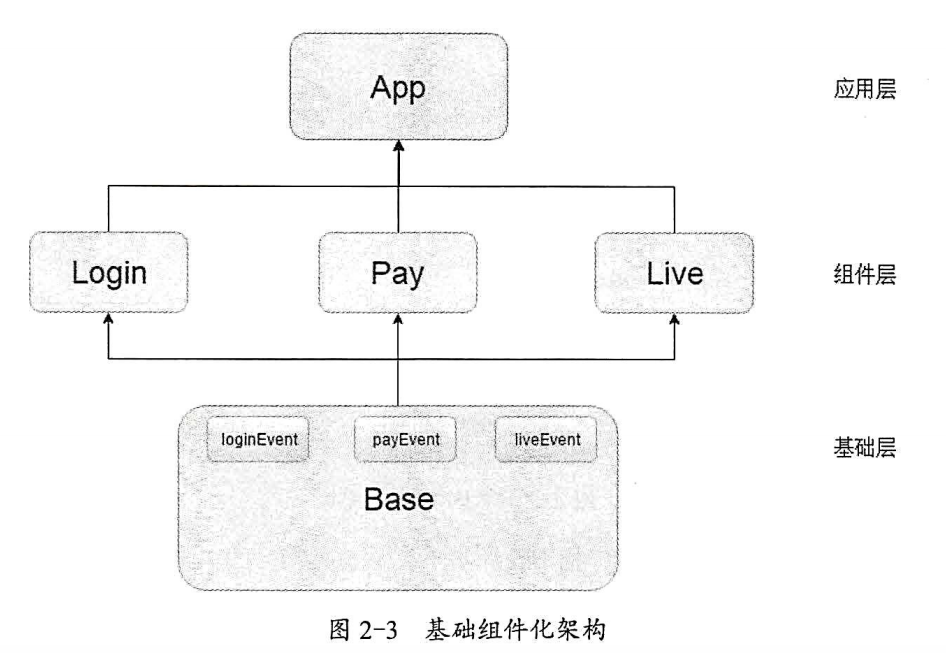
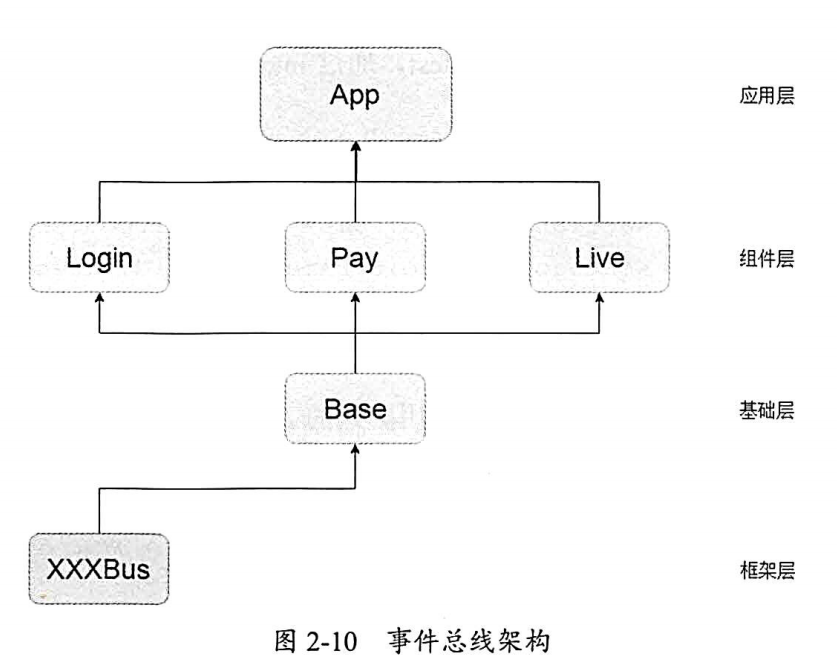
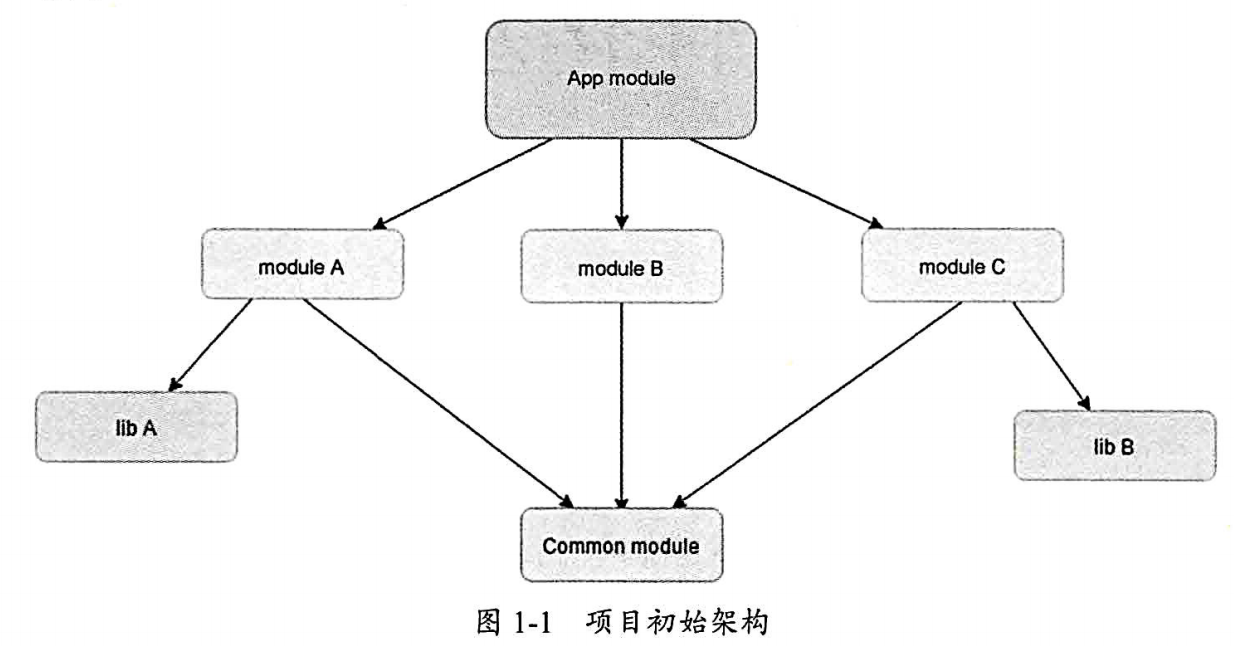
在最基础的组件化架构中,组件层中的模块是相互独立的,并不存在依赖,没有依赖就没法传递消息,那该如何传递消息呢?我们需要第三方协助,也就是基础层(BaseModule),如下图所示:
从图可以看出,Base module 就是跨越组件化层级通信的关键,也是模块间交流的基础 。
方式1、本地广播 本地广播与全局广播比较:
本地广播只能动态注册,全局广播可以动态和静态注册
本地广播只局限于当前App(严谨说是当前进程),全局广播可以跨进程
本地广播使用Handler 实现,就在当前进程传播,因此效率比全局广播高
但是,在用于组件间通信时,本地广播将一切全交给系统负责了,无法干预传输途中的任何步骤 。
方式2、事件总线 事件总线主要有 EventBus 和 RxBus。
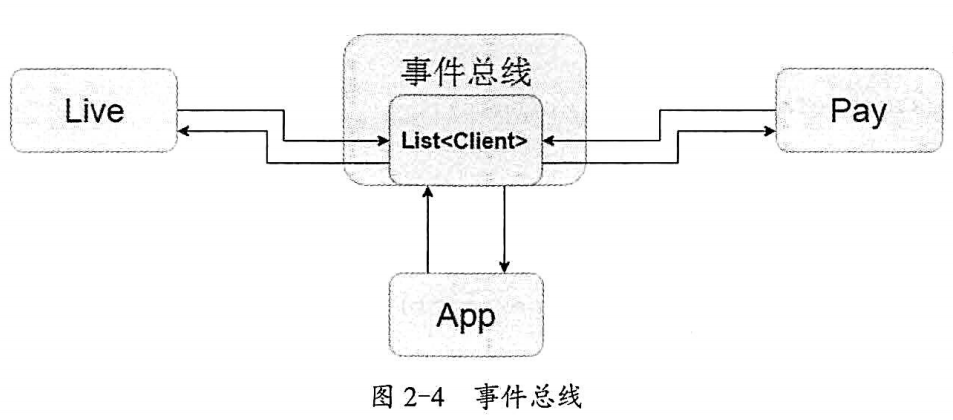
事件总线通过记录对象、使用监听者模式来通知对象各种事件。工作机制如下图:
其中,EventBus 是一款针对Android优化的发布/订阅事件总线,主要功能是替代 Intent、Handler、BroadCast,在Fragment、Activity、Service、线程之间传递消息,优点是开销小,代码更优雅,发送和接收者解耦;缺点是依附的对象销毁时一定要记得取消订阅,否则由于强引用会导致内存泄漏,并且,每个事件都必须自定义一个事件类,造成事件类太多 。
注意: EventBus 2.x 使用的是 运行时注解,很大程度上是依赖于反射规则的,采用反射的方式对整个注册的类的所有方法进行扫描来完成注册;而Eventbus 3.x 使用的是 编译时注解,在编译的时候,就会将相应操作编译成 .class 文件,在编译时就进行操作这样运行时的速度就会快很多。
RxBus 是基于RxJava 衍生而来的,只要引入了 RxJava 和 R小Android 就能很方便地使用 RxBus ,它的实现很有意思,采用静态内部类的单例,由于内部静态类只会被加载一次,所以实现方式是线程安全的 (可以与volatile + double check 对比着看):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class RxBus private final Subject bus; public RxBus () bus = new SerializedSubject<>(PublishSubject.create()); } public static RxBus getInstance () return RxBusHolder.mInstance; } static class RxBusHolder private static RxBus mInstance = new RxBus(); } }
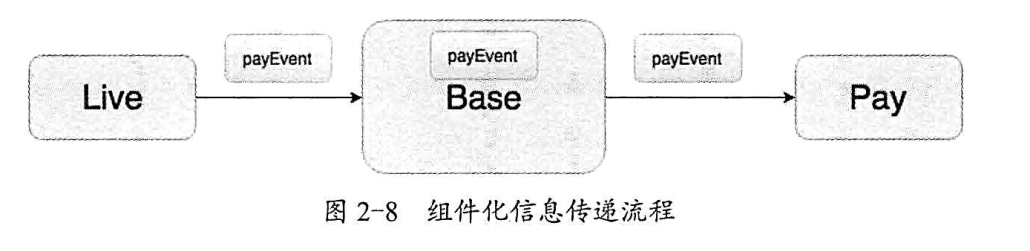
组件化事件总线考量 通信事件都要放到公共的Base模块中,Base模块也需要依赖于事件总线框架,信息组件都都需要放在Base模块中,我们看一下总线传递的流程:
组件化要求功能模块独立,应该尽量少影响 App module 和 Base module ,其中 Base module 尽量做得通用,不受其他模块影响。而如果上述事件总线放在 Base module 中,每个模块增删时,都需要添加或者删除Base module 的事件 ,而增删事件会让其他代码索引到这些事件的代码时造成错误,这样会破坏组件化设计的规则。
这就是目前组件化通信会遇到的瓶颈。两种比较适合现阶段组件化通信的方式:
ModuleBus: 能传递一些基础类型数据,不需要在 Base module 添加额外的类,所以不会影响 Base模块的架构,但也无法动态移除信息接收端代码,而自定义的事件信息模型还是需要添加到 Base module
组件化架构的 ModularizationArchitecture 库。每个功能模块都需要使用注解建立 Action 时间,每个 Action 完成一个事件动作,没有用到反射,参数通过 HashMap<Stirng,String>传递,无法传递对象
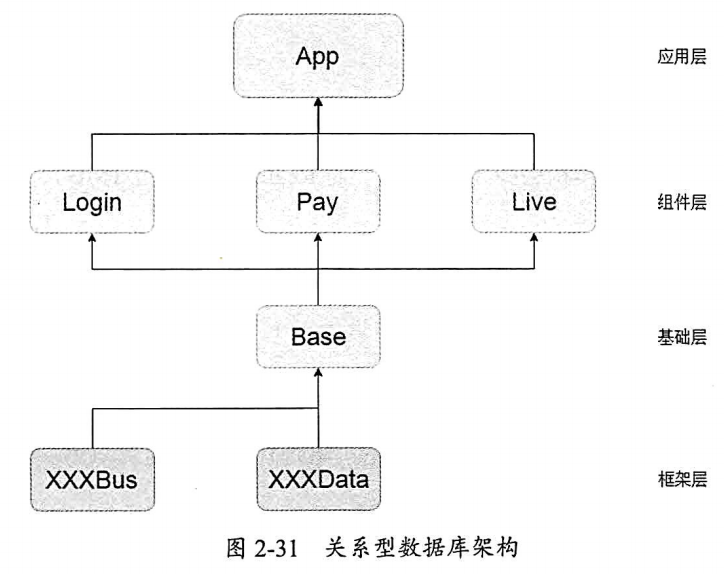
但是,如果一定要使用 EventBus 或者 RxBus事件总线 ,这里提供一种架构方案,最大限度地解耦:
其中xxBus独立为一个module ,Base module 依赖 xxBus 对事件通信的解耦,抽离事件到 xxBus 事件总线模块,以后添加事件的Event 的实体都需要在上面创建。
组件间跳转 在组件化中,两个功能模块是不存在直接依赖的,其依赖规则是通过 Base module 间接依赖的 。
Activity 跳转,直观的跳转就是startActivity 发送一个包装好的 intent去实现。但是如果Activity 在其他 moudle ,则无法索引到 Activity 类,这时候我们会很自然想到使用 intent 包装隐式 Action 实现。隐式跳转的方法:
1 2 3 4 5 6 7 8 9 Intent intent = new Intent("material.com.settings" ); startActivity(intent); Intent intent = new Intent(); intent.setClassName("模块包名" , "Activity路径" ); intent.setComponent(new ComponentName("模块包名" ,"Activity路径" )); startActivity(intent);
但是第2种方式会产生崩溃,提示Activity并没有在AndroidManifest中注册,可是明明注册了啊?这里真正需要理解的是, setClassName 和 setComponent 函数第一个参数的真正含义,它们是 App 的包名而不是所在的 module 的包名 ! 这在第1章的时候已经聊过了,当最终合成 AndroidManifest 后,module的包名压根就不存在了 (有空需要自己去验证下 )。
由于隐式跳转有可能找不到目标Activity 而导致崩溃,所以,我们应该首先判断intent是否能够正常跳转。
此外,还有对安全问题的考虑,因为其他App也能通过隐式的 Intent 来启动 Activity (隐式跳转是原生的,作用范围是整个Android系统 ),为了确保只有自己的 App 能启动组件,需要设置 exported = false。
ARouter 路由跳转 ARouter 使用 AOP 切面编程可以进行控制跳转的过滤。在 Application 中进行 init 之后,我们就对跳转目标做处理:
1 2 3 4 5 6 7 8 9 10 11 12 @Route(path="gank_web/1") public class WebActivity extends BaseActivity ARouter.getInstance().build("gank_web/1" ) .withString("url" ,url) .navigation(); Intent intent = getIntent(); String url = intent.getStringExtra("url" );
整一个过程还是非常优雅的。
组件化最佳路由 既然已经存在隐式跳转,为什么我们还要选择路由呢?在组件化架构中,假如移除一些功能 module 和跳转关系,则跳转无法成功,此时,如果要做一些提示,将迁入更多的判断机制代码。而使用路由机制,可以统一对这些索引不到的 module 页面进行提前拦截和做出提示。
路由除了跳转,另一个重要作用就是拦截,比如可以在跳转前进行登录状态验证,路由表的引入,也不需要在 AndroidManifest 中声明隐式跳转。
路由的选择: 现在开源软件中有不少路由结构,比如: ActivityRouter、天猫统跳协议、ARouter、DeepLinkDispatch、OkDeepLink 等。如果你的项目没有引入 RxJava,那么 ARouter 的介入成本低,是首选;如果接入了,那 OkDeepLink 可以 兼容 RxJava ,可以做考虑。当然,OkDeepLink 会在 Intent 中加入 FLAG_ACTIVITY_NEW_TASK 标识,那么创建每个Activity 都会创建新的任务栈来装载 !这样无法做到标准的压栈。
空类索引 如果不想使用第三方路由,可以采用空类索引的方式实现跳转,它的原理就是:使用空类来欺骗编译。 具体的步骤为(个人理解,不一定对):
在各个 module 编写好,但还没实现跨 module 跳转之前
将所有 module 打包,就会生成 apk 了,只是还暂时不能跳转而已
通过某种手段(人工或者工具)解压 apk ,并读取 AndroidManifest.xml 文件中的四大组件信息,生成一个 jar 包
这个 jar 包里面的内容是空的四大组件,比如,AndroidManifest 中有个 com.example.ActivityA ,那么在 jar 包中也会声明(同路径、同类名)一个 com.example.ActivityA,并且继承 Activity
之后,将这个 jar 包以 provided 形式(只是引入,不会编译进去)到各个 module 中
此后,各个 module 便可以直接以普通的显式 Intent 来 startActivity 了!
动态创建 动态创建也是为了解耦
动态创建 Fragment 如果在单Activity + 多Fragment情景中,可以使用动态创建 Fragment (反射的方式),之后添加到 ViewPager 里面,这种方式用于模块间的解耦是非常合适的。因为普通方式使用 Fragment 的话,需要强引用 Fragment,而这些Fragment 可能不在当前使用的 module 中,而且因为ARouter 也支持这种 Fragment 方式,所以直接使用 ARouter 是不错的。当然,由于我们是通过反射方式创建实例的,因此需要防止Fragment所在的 module 被移除之后产生 Exception,并且反射也会消耗性能。
动态配置Application 前面介绍了 Application 产生的替换原则。如果某些功能模块需要做一些初始化操作,则只能强引用到主 module 的 Application 中 ,是否有方法可以降低耦合呢?
第一种方案: 通过主 module 获取各个 module 的初始化文件,然后通过反射初始化的 Java 文件来调用初始化方法:
Base module 中定义接口 BaseAppInit,里面有 init() 方法
1 2 3 public interface BaseAppInit boolean init (Application app) }
在 module 中使用 BaseAppInit ,实现它:
1 2 3 4 5 6 7 public class NewsInit implements BaseAppInit @Override public boolean init (Application app) return false ; } }
在 PageConfig 中添加配置
1 2 3 4 5 private static final String NEWS_INIT = "material.com.news.api.NewsInit" ;public static String[] initModules = { NEWS_INIT };
在主 module 的 Application 中实现初始化方法:
1 2 3 4 5 6 7 8 9 10 11 public void initModules () for (String init: PageConfig.initModules) { try { Class<?> clazz = Class.forName(init); BaseAppInit moduleInit = (BaseAppInit)clazz.newInstance(); moduleInit.init(this ); } catch (Exception e) { e.printStack(); } } }
在 Application的 onCreate 中调用 上述的 initModules 方法即可
第二种方案: 在 Base module 中创建 BaseApplication ,之后主 Module 中的 Application 继承 BaseApplication 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class BaseAppLogic protected BaseApplication mApplication; public void setApplication (BaseApplication application) mApplication = application; } public void onCreate () public void onLowMemory () ... } public abstract class BaseApplication extends Application @Override public void onCreate () initLogic(); logicCreate(); } @Override public void onLowMemory () logicLowMemory(); } protected abstract void logicCreate () protected abstract void logicLowMemory () }
唉,第二次了还是没看懂这个方案,先不写了(以上内容代码没写完的 )。我个人觉得可以参考 ARouter 的思路,给子 module 自定义的 Application 加编译时注解,在编译的时候把这些 Application 找出来,生成新的类,然后就可以反射调用子module的 Application 方法了。
数据存储 存储方式主要5种,网络存储、File I/O 、SQLite、ContentProvider、SharedPreference,根据 安全、效率、量级 三个维度去决定使用哪种方式:
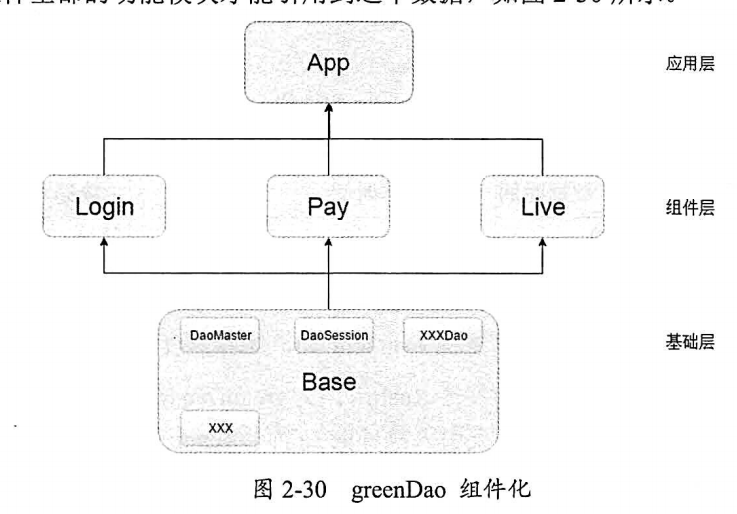
组件化存储 Android 原生的存储体系是全局的,在组件化开发中,五中原生的存储方式是完全通用的。文中介绍了 greeDAO 这个关系映射的数据库框架,greeDAO 是目前众多ORM(对象关系映射)数据库中最稳定、速度最快、编写体验最好的框架,并且支持数据加密,RxJava, 它能通过对象的方式去操作关系型数据库,但是它的底层还是 SQLite ,它的原理是将一个实体对象转换成意向数据,然后保存到SQLite。也正因为基于SQLite ,所以不能存储图片这样的大文件。关于数据库在组件化的应用,实体类放在本身的module 是无法传递的,需要放在一个统一的 module 中来管理这些类的产生和引用,其greenDao 需要在 Base module 中引入,编写时注解生成的对象也应该在 Base module 中,这样全部的模块才能引用到这个数据:
当然,更好的设计,文中也建议与事件总线一样,如下图:
权限管理 组件化权限 通过查看 AndroidManifest 文件,可以看到各个 module 中的权限申请,最终会被合并到完整 AndroidManifest 中。这时候,我们有两种权限放置方案:
将 normal 级别的权限申请都放到 Base module 中,然后在各个 module 中分别申请 dangerous 权限,这样分配的好处在于:当添加或者移除一个模块时,隐私权限的申请也跟随移除,做到最大限度地解耦
还有人提议,将权限全部转交给每个 module 中,达到最大程度的解耦,这样做的缺点在于:会增加AndroidManifest 的合并检测的耗时
当项目需要适配到 Android 6.0 以上的动态权限申请时,需要在 Base module 中添加自己封装的一套权限申请工具,其他组件层的 module 都能使用这套工具,书中推荐选择 AndPermission 。
动态权限框架 AndPermission 使用简单,并且最大程度适配国内各大厂商的 ROM。
路由拦截 当调用其他模块的功能时,就是路由拦截器起作用的时候了,将路由拦截器和权限申请结合在一起 ,前面介绍的 ARouter 是跳转钱是会遍历 Interceptor 的,因此我们可以设置拦截器来实现:
1 2 3 4 5 6 7 8 9 10 public class SettingsIntercptor implements IInterceptor @Override public void process (Postcard postcard, InterceptorCallback callback) if (postcard.getPath.equals("/gank_setting/1" )) { } } }
在上述过程可能涉及到弹出 Dialog ,那么我们首先要获取当前的 Activity 。我们可以通过在 Base module 中的 BaseApplication 中做 registerActivityLifecycle 来保存栈顶的 Activity,有两种方案:
在onCreate 的时候持有这个 Activity ,但是这可能引起内存泄漏
我们在 resume 的时候持有 这个activity ,由于 下一个 Activity 的 resume 肯定比当前 Activity 的 destroy 要先执行 ,所以可以肯定静态持有栈顶 Activity 不会导致内存泄漏(细品就知道了)。
静态常量 在 Application module 中查看 R.java 文件:
1 2 3 4 5 6 7 public final class R public static final class anim public static final int abc_fade_in = 0x7f050000 ; public static final int abc_fade_out = 0x7f050001 ; public static final int abc_fade_from_bottom = 0x7f050002 ; } }
但是,在 Lib module 中查看 R.java 文件:
1 2 3 4 5 6 7 public final class R public static final class anim public static int abc_fade_in = 0x7f050000 ; public static int abc_fade_out = 0x7f050001 ; public static int abc_fade_from_bottom = 0x7f050002 ; } }
仔细观察会发现,在 Lib module 中的静态变量没有被赋予 final 属性 。在第1章提及,各个 module 会生成 aar 文件,并且被引用到 Application module 中,最终合并成 apk 文件,当各个次级 module 在 Application module 中被解压后,在编译时 R.java 会被重新解压到 build/generated/source/r/debug(release)/包名/R.java 中。
合并后的 R.java 中 的id 属性会被添加 final 修饰符 。(这是我自己理解的,需要验证 )
组件化的静态变量 在 Lib module 中,R.java 文件没有了 final 关键字会导致什么问题呢?
这就会导致凡是规定必须采用常量的地方都无法直接使用 R.java 中的变量,包括 switch-case 和注解。 为此,我们只能抛弃 switch-case 而只能使用 if-else 来实现,if 里面不需要常量。
(这个知识点是自己加的 >)不同的 module 之间无法保证 R.java 中变量对应的数值不同,但是我们可以保证 R.java 的值不同,为了避免R.java 中资源的冲突,不同的 module 中,我们资源命名最好加前缀加以区分,比如登录module ,资源以 login_ 开头,比如社区module ,资源可以以 comm_ 开头等等。
R2.java 的秘密 ButterKnife ,一个专注于 Android View 的注入框架,可以大量减少 findviewById 和 setOnClickListener 操作的第三方库。当使用注入View 绑定时:
1 2 @BindView(R2.id.submit) public Toolbar mToolbar;
编译成 class 后,R的值会替换为常量:
1 2 @BindView(2131492966) public Toolbar mToolbar;
注解中只能使用常量 ,如果不是常量就会报错,那么 ButterKnife 是如何解决的呢?它的原理是使用替换的方法,将 R.java 文件复制一份,命名为 R2.java ,然后给 R2.java 的变量加上 final 修饰符,在相关的地方直接使用 R2 资源! 这一点,可以从 ButterKnife Gradle 中的 ButterKnifePlugin 源码中找到答案,源码略。最终生成的 R2 与 R 文件在同一个目录。
当然,ButterKnife 中处理后代码还是会用 findViewById ,用的是 R 的,而不是 R2, 但是 onClick 的时候,用的还是 R2,因为我们 view.getId() 返回的是 R 中的id ,而 R2 是 R 的副本,所以是一致的,不会有问题。
值得注意的是,library 使用 R2 的方式时,会出现 library 和 Application 切换 R 文件资源的引用问题,这里全部使用 R2 的方式生成引用资源 id,则不会出现此问题。
资源冲突 组件化的资源汇合 全部功能都依赖 Base module ,但是 Application module 最终还是得将功能 module 的 aar 文件汇总后,才能开始编译,那会不会出现多个 Base module 呢,不会,我们可以通过 gradle 命令查看 module 的依赖树:
./gradlew module_name: dependencies
则会展示依赖树,有些传递依赖标记了 * ,表示这个依赖被忽略了,因为有其他定级依赖中也依赖了这个传递的依赖。
AndroidManifest 冲突问题 前面说了,AndroidManifest 中 Application 的 app:name 冲突时,需要使用 “tools:replace=android:name” 声明可替换
包冲突 包冲突可以先检查依赖报告,用以下命令查看依赖目录树:
./gradlew module_name: dependencies
有冲突可以使用 exclude 解决:
1 2 3 compile('com.facebook.fresco:fresco:0.10.0' ) { exclude group: 'com.android.support' , module :'support-v4' }
资源名冲突 因为无法保证不同的module 中资源名称不同,那么Gradle 就会合并相同命名的资源,并且后编译的模块会覆盖之前编译的模块中的资源字段中的内容 。所以,一般在一开始命名的时候,不同的 module 加上不同的前缀即可解决。只能一点可以采用 gradle 命名提示机制,resourcePrefix字段:
1 2 3 android { resourcePrefix "组件名_" }
组件化混淆 混淆基础 混淆包括了代码压缩,代码混淆以及资源压缩等优化过程。AS 中的 ProGuard 是一个压缩、优化和混淆Java 字节码的工具,可以删除无用类、字段、方法和属性,还可以删除无用注释,最大限度优化字节码文件。
不能混淆的情况有以下:
反射中使用的元素
最好不让一些Bean 对象混淆
四大组件要在AndroidManifest中声明,混淆后类名发生改变,因此不要混淆
注解不要混淆,注解一般要用到反射
不能混淆枚举红的 value 和 valueOf ,因为这两个方法是静态添加到代码中运行的,也会被反射使用
JNI 调用 java 的方法,需要通过类名和方法名构成地址形成
java 使用 Native 方法,Native 是C/C++ 编写的,方法是无法一同混淆的
JS 调用 java的方法(-keepattributes *JavascriptInterface*)
webview中 Javascript 的调用方法不能混淆
第三方库建议使用自身混淆规则
Parcelable 的子类和 Creator 的静态成员变量不混淆
资源混淆 proguard 可以混淆代码,其实资源名也是能混淆的,混淆后变为 R.string.a 之类的,它有3种方案:
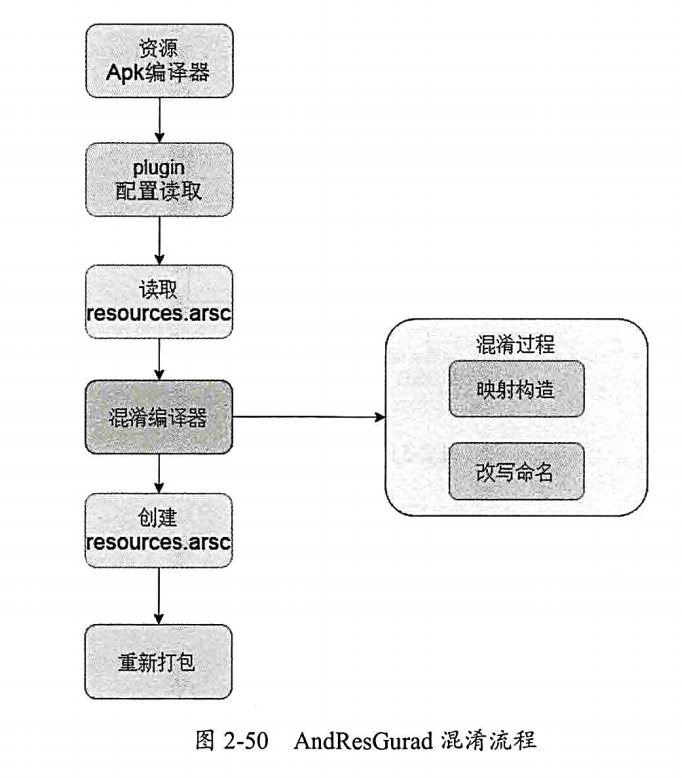
书中推荐使用 微信的 AndResGuard 混淆机制,它的工作流程如下:
组件化混淆 重点是保证只混淆一次:
第一种方案:只在 Application module 中设置混淆,其他module 都关闭混淆,所有的规则都放在 Application 的module 中
缺点:当某些模块移除之后,需要手动移除混淆规则,虽然理论上混淆规则多了不会崩溃或者编译不过,但是会对编译效率造成影响
第二种方案:命令将 所有的 module 中的 proguard-rule.pro 文件合成,然后覆盖 Application module 中的混淆文件
有合成操作,也会影响编译效率
第三种方案: 将 proguard-rule.pro 文件打进 aar
Library module 自身拥有将 proguard-rule.pro 文件打包到 aar 中的设置,如添加一个 consumerProguardFiles 属性:
1 2 3 defaultConfig { consumerProguardFiles 'proguard-fules.pro' }
开源库中可以依赖此标志来指定库的混淆方式,consumerProguardFiles 属性会将 *.pro 文件打包进aar ,混淆时会自动使用次混淆配置文件。不过,以 consumerProguardFiles 形式添加 混淆文件具有以下特性:
proguard.txt 文件会在aar文件中
proguard 配置会在混淆时使用
此配置只针对aar
此配置只针对 库文件有效,对应用程序无效
当 Application module 将全部代码汇总混淆的时候, Library module 会被打包为 release.aar ,然后被引用汇总,通过 proguard.txt 规则各自混淆,保证只混淆一次。
第三种方案可以最大限度地解耦混淆解耦工作。
多渠道打包 可以使用几种方式打渠道包:
在App目录的build.gradle 中配置 productFlavors
1 2 3 4 5 6 7 8 9 productFlavors { qihu360{} baidu {} //...省略其他渠道 productFlavors.all { flavor -> flavor.manifestPlaceholders = [channel: name] } }
在 AS 的 Build -> Generate signed apk 中选择设置渠道
当然如果要一次性打出全部的渠道,只需要 执行 .gradlew build 即可,就可以打出所有的 Release 和 Debug 包
多渠道模块设置 有个时候,我们的App可能要打包成 管理员端、普通用户端 ,等等此类需求是比较棘手的,不同的版本依赖的module不一样,这时候怎么弄呢?我们可以使用原生的 Gradle 来配置构建,下面演示一个用户版本和管理版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 //下面的代码都在根目录的 build.gradle 中 productFlavors { //用户版 client { manifestPlaceholders = [ channel: "10086", //渠道号 verNum: "1", //版本号 app_name: "Gank" //App名 ] } //服务版 server { manifestPlaceholders = [ channel: "10087", //渠道号 verNum: "1", //版本号 app_name: "Gank服务版" //App名 ] } } dependencies { clientCompile project(':settings') //引入客户版特定module clientCompile project(':submit')//我怀疑书上打错了,应该这里只是 compile 吧?是客户版与服务版公用的? serverCompile project(':server_settings') //引入服务版特定module }
上面通过 productFlavors 属性设置多渠道,而 manifestPlaceholders 设置不同渠道中的不同属性,这些属性需要在 AndroidManifest 中声明才能使用 。在 dependencies 中通过设置 xxxCompile 来配置不同渠道需要引用的 module 文件。 接下来,我们要在 App module 的 AndroidManifest 文件中声明:
1 2 3 4 5 6 7 8 9 10 11 12 13 <application android:allowBackup="true" <!--app引用名--> android:label="${app_name}" <!--标记可替代--> tools:replace="label"> <!--版本号声明--> <meta-data android:name="verNum" android:value="${verNum}"/> <!--渠道号声明--> <meta-data android:name="channel" android:value="${channel}"/> </application>
其中,android:label 属性用于更改签名,${xxx} 会自动引用 manifestPlaceholders 对应的 key 值, tools:replace 属性在以前的 Application 替代中提到,最后替换的属性名需要添加 tools:replace ,这里提示编译器需要替换的 label 属性。
声明 meta-data 用于某些额外自定义的属性,这些属性都可以通过代码读取:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static Object getMetaData (Context context, String metaName) String pkgName = context.getPackageName(); ApplicationInfo appInfo = context.getPackageManager().getApplicationInfo(pkgName, PackageManager.GET_META_DATA); Object obj = appInfo.metaData.get(metaName); return obj; } public static int getChannelNum (Context context) Object obj = getMetaData(context); return (int )obj; }
以上shi值调用,至于需要某个类调用,则可以直接将路径以值的形式来传递(同样在meta-data中),然后解析处meta-data,最后用反射方式就能完成对象的创建,之后就能调用了,代码就略了。