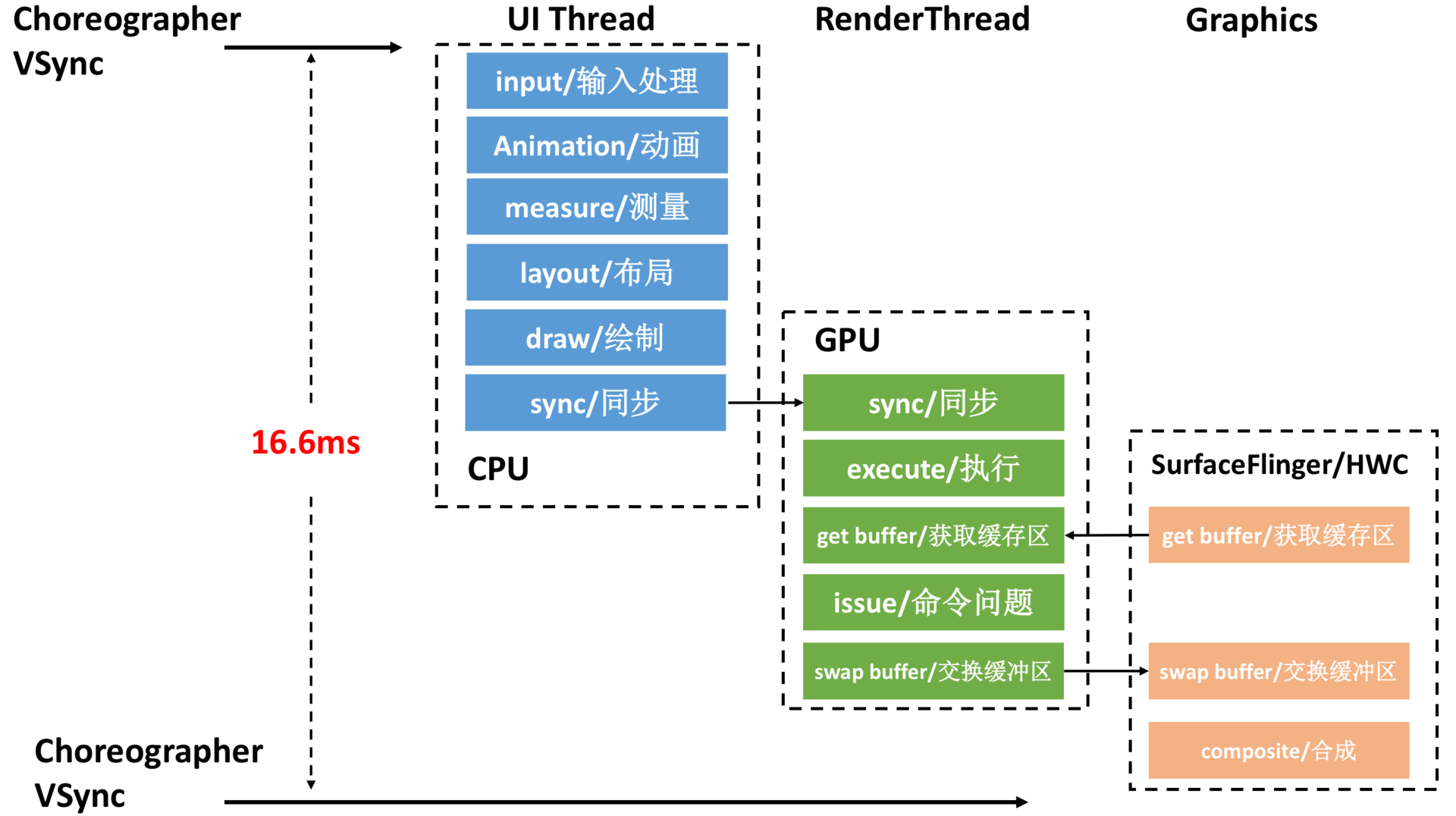
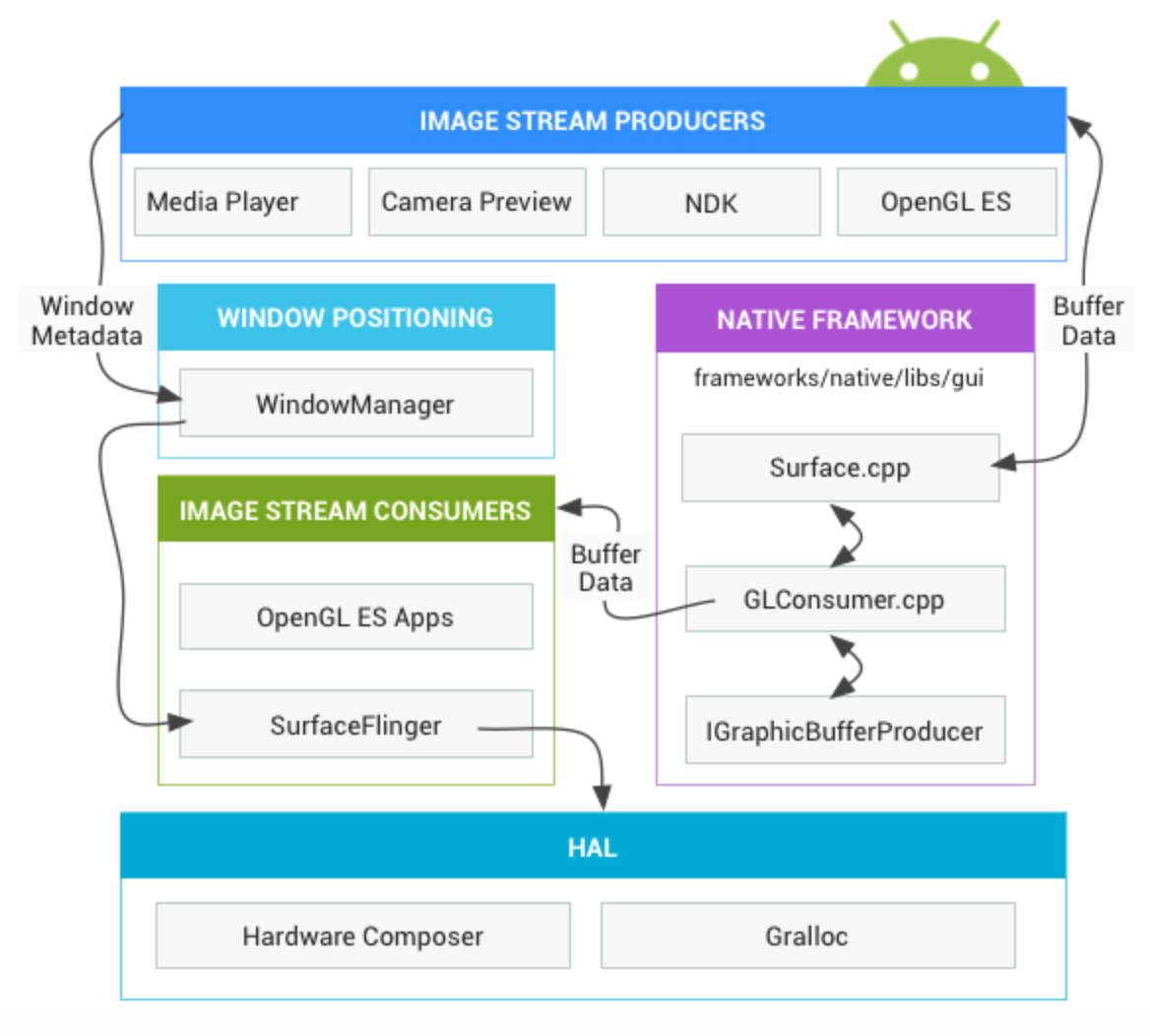
接下来章节要介绍以下概念,掌握了这些底层知识,就算是迈进了Android插件化的大门了:
Binder
AIDL
AMS
四大组件工作原理
PMS
App安装过程
ClassLoader以及双亲委托
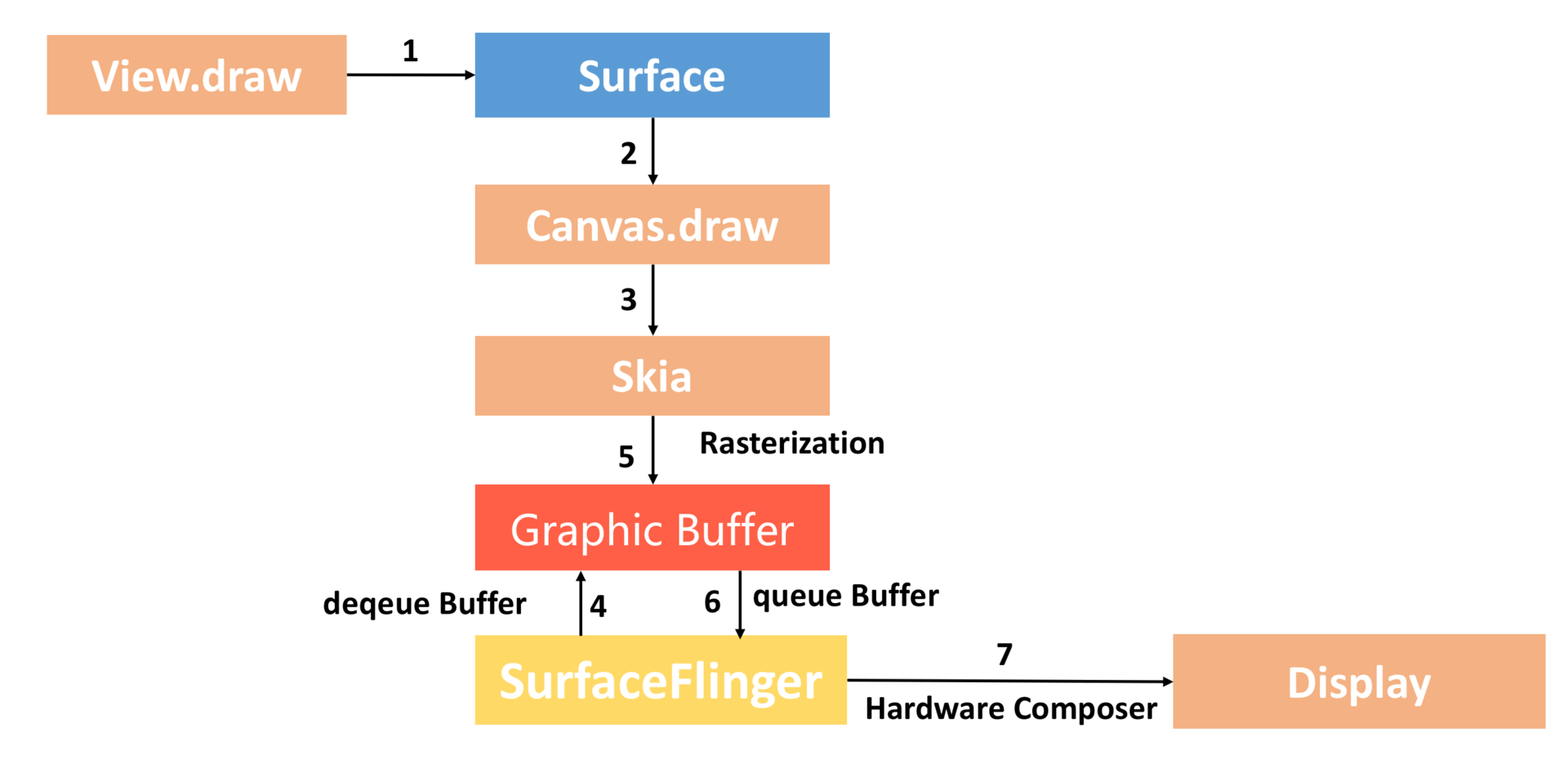
Binder 原理 对于Binder的原理,只需要了解以下过程即可:
首先,Server 在 SM 中注册
如果Client 需要调用Server 的 add 方法,就需要先获取Server 的对象,但是SM不会把真正的 Server 对象返回给 Client,而是把 Server 的一个代理对象(Proxy)返回给Client
Client 调用Proxy 的add方法,SM 会帮它去调用 Server 的add 方法,并把结果返回给 Client
具体过程可以参考下图:
AIDL原理 我们自定义一个aidl 文件时(比如 MyAidl.aidl,里面有个sum方法),在sync 和 rebuild 之后,Android studio 会为我们自动生成 MyAidl.java 文件,类图如下图所示:
为什么要把3个类都放在一个文件里面呢?因为如果有多个aidl文件,那么就会有很多的Stub和Proxy类,这样就会重名,把它们放在各自的文件里面,就区分开了,实现了内聚 。3个类的代码如下:
可以看到,在Stub的asInterface 方法中会根据 IBinder 类型的obj 对象来判断是不是有跨进程,如果未跨进程,直接返回 obj 通过 queryLocalInterface 得到的iin;如果有跨进程,则新建 Stub.Proxy ,并返回。
还有,Stub 的 onTransact 指的是接收Server 返回的数据,这里面会根据code 来做相应的操作,对Server的每个操作都会有唯一的code对应,因为底层并没支持类似 sum 这种method标识。
此外,Parcel 类型的写和读也值得注意,它并不需要key-value的方式,而是直接将value写入(reply.writeString(),reply.wrteInt() 等方式)。可以理解为(这里与旭哥聊过,我自己没看过源码,不一定准确):这些数据都是挨着排放,会存储每个值的偏移值(curr_position)以及大小(size),取的时候,Parcel 并不知道里面存的是什么,只能靠自己正确知道类型按照存入的顺序 取出来,比如 data.readInt()、data.redString(),通过偏移值(curr_position)以及大小(size),就能正确读取值。这里可以参考csdn上的博客
对于Proxy 而言,它的sum方法,只是通过 IBinder 类型的 mRemote 将参数和code(用来唯一标记一个操作,对应 onTransact 接收server 返回的数据时的code)发送给server (用_data发送数据,用_reply接收数据),而并没有真正计算。
经过以上的分析,完整的 AIDL 类图应该如下图所示:
AMS 站在四大组件角度看,AMS就是Binder的Server,四大组件都归他管。
这里引申两个问题:
App 的安装过程,为什么不把apk解压到本地,这样读取图片就不用每次都从apk中读取了。
为什么Hook永远是在Binder 的Client端,也就是四大组件这边,而不是在 AMS 端。
对于第二个问题,拿Android的剪贴板来说,它也是个Binder服务,如果在AMS层面把剪贴板给Hook了,那会导致Android系统中所有的剪贴板功能被Hook了,所有App都会受到影响,这不就是病毒嘛。。。所以Android肯定不会允许。
Activity 工作原理 App怎么启动 Launcher 是个App,与我们的各种应用App没什么不同。我们在开发一个App时,在AndroidManifest文件中需要定义默认启动Activity:
1 2 3 4 5 6 <activity android:name=".MainActivity" > <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity>
这些信息在App安装或者 (Android系统启动)的时候,PackageManager-Service 会从apk 中读取封装到 Launcher 显示的桌面图标中。
启动App并非那么简单 上一节只是简单描述,Launcher 与 我们要启动的App(假设是斗鱼App)位于两个不同的进程,所以这一系列过程需要进程间通信Binder来完成的,AMS 也出场了,以启动斗鱼App为例,整体分为以下7个阶段(基于Android 6.0源码):
Launcher通知AMS,要启动斗鱼App,并指定启动的页面
AMS 通知 Launcher “我知道了,没你什么事了”,同时,把要启动的首页记下来
Launcher 页面进入 Pause 状态,然后通知AMS “我睡了,你找斗鱼App去”
AMS 检查斗鱼App是否启动,是,则直接唤起;否则,就启动一个新进程。AMS在新进程中创建一个 ActivityThread 对象,启动其中的main函数
斗鱼App启动后,通知 AMS “我启动好了”
AMS 翻出步骤 2 中保存的值,告诉斗鱼App,启动哪个页面。
斗鱼App启动首页,创建 Context 并与首页Activity关联,之后调用首页 Activity 的onCreate函数
至此,App启动流程已经完成。
以上步骤总体可以分为三个部分: 一、Launcher 通知AMS;二、AMS处理Launcher传过来的信息;三、Launcher休眠,通知AMS:“我真的已经睡了”;四、AMS启动新的进程;五:新进程启动,以ActivityThread 的main函数作为入口;六、AMS告诉新的App启动哪个Activity;7、App启动Activity。
Launcher页面本身也是Activity,所以它startActivity 最终也会调用到 Activity 的startActivityForResult,在里面,最终使用 Instrumentation 的 execStartActivity 来实现功能:
Instrumentation.ActivityResult ar = mInstrumentation.execStartActivity(this, mMainThread.getApplicationThread(), mToken, this, intent, requestCode, options)
其中,
mMainThread.getApplicationThread() 获取的是一个Binder 对象,这个对象类型为 ApplicationThread(是 MainThread的内部类),这个对象代表了 Launcher 所在的进程。
mToken 也是一个Binder对象,代表Launcher这个Activity ,通过 Instrumentation 传给 AMS 后,AMS 一查就能知道是谁向 AMS 发起了请求。
Launcher通知AMS 的流程如下图所示:
这里要注意一点,ActivityThread 是UI县城,它代表应用程序,我们平常认知 Application 是这个角色。其实Application 就是一个上下文而已,对开发者也许很重要,但是对Android系统中没那么重要。
Instrumentation 的execStartActivity 方法执行时,其实就是将数据透传给 ActivityManagerNativ:
1 2 3 4 5 6 7 8 9 public class Instrumentation public ActivityResult exeStartActivity (xxx,xxx,...) try { int result = ActivityManagerNative.getDefault().startActivity(xx,xx,....); } } }
ActivityManagerNative(AMN) 这个类会反复用到。AMN通过getDefault从ServiceManager中取得一个名为 activity 的对象,然后把它包装成 ActivityManagerProxy(AMP) 对象, AMP 就是 AMS 的代理对象。AMN 和 AMP 都实现了 IActivityManager 接口,AMS 继承自 AMN ,对照之前的 AIDL 的UML,就不难理解了,下图是 他们的类图:
第二阶段就是 AMS 处理Launcher 传过来的信息,主要有如下步骤:
Binder(即 AMN/AMP) 和 AMS 通信,比如这次因为是要启动斗鱼App首页,那么是发送 START_ACTIVITY 请求给 AMS。
AMS 收到后,就会检查斗鱼 App 中 AndroidManifest文件,是否存在这个目标Activity,如果不存在就抛出 Activity not found。
AMS 通知Launcher,“没你事了,洗洗睡”。
我们想想第3步AMS 怎样给 Launcher 发送消息,之前我们说启动过程把 Launcher 以及它所在的进程传过来了,它在AMS 这边保存了一个 ActivityRecord 对象,这个对象里有个 ApplicationThreadProxy,这就是一个Binder代理,它的Binder 真身,就是 ApplicationThread 。因此,答案就是:AMS通过ApplicationThreadProxy 发送消息,而App通过 ApplicationThread来接收这个消息。
ApplicationThread(APT)在接收到AMS的消息后,会调用ActivityThread的sendMessage向Launcher主线程Handler(H对象)发送一个 ACTIVITY_PAUSE消息,即进入第三阶段:Launcher休眠,并且通知AMS:“我真的已经睡了”。
这个pause的实现原理:在ActivityThread里面有一个 mActivities 集合,保存当前App(目前是Launcher)中所有的Activity,这时候把它们都找出来,让它们全部休眠 。之后,就通知AMS “已经休眠”。
这时候,应该到第四阶段: AMS应该给Zygote 进程发送消息创建新进程了,并且在创建进程后,马上创建 ActivityThread 对象,并且在其中创建主线程Looper、创建Application(注意,Application是在这里生成的)。
具体过程是:ActivityThread 在收到 BIND_APPLICATION消息后,根据传过来的 ApplicationInfo 创建一个对应的 LoadedApk 对象(标志当前的APK信息),接着反射创建Application。在App创建好之后,就通知 AMS “我启动好了”,同时把自己的 ActivityThread 对象发送给AMS,AMS 就登记这个App信息,AMS 以后也能通过这个 ActivityThread (我的理解是ActivityThread中的ApplicationThread的代理对象)对象向这个 APP 发送消息。
接下来就是AMS告诉App要启动哪个Activity,App通过 H 类启动这个新的 Activity。
App内部页面跳转 有了前面的页面跳转,内部跳转就更容易了,流程大同小异,这里不多说
Context家族史 可以用一张图来展示 Context 家族的关系:
两种启动Activity方式的差别(这是我自己加的) 通过Activity可以直接 startActivity 来启动新的Activity,也可以在Activity 中 getApplicationContext 来获取 Context 上下文通过 ContextImpl 来最终启动Activity,这二者的区别是什么呢?首先看下下图:
Context的 startActivity ,其实也是通过 ContextImpl 拿 mMainThread对象,从 mMainThread 中获取 Instrumentation,让它来执行 execStartActivity,和 Activity 自己的方法实现是一样一样的(其实这里在书上说得并不详细,至少没说为什么 ApplicationContext 在startActivity 时 为什么要 NEW_TASK 标记)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public void startActivity (Intent intent, Bundle options) ... if ((intent.getFlags()&Intent.FLAG_ACTIVITY_NEW_TASK) == 0 ) { throw new AndroidRuntimeException( "Calling startActivity() from outside of an Activity " + " context requires the FLAG_ACTIVITY_NEW_TASK flag." + " Is this really what you want?" ); } mMainThread.getInstrumentation().execStartActivity( getOuterContext(), mMainThread.getApplicationThread(), null , (Activity) null , intent, -1 , options); } public void startActivityForResult (@RequiresPermission Intent intent, int requestCode,@Nullable Bundle options) if (mParent == null ) { ... Instrumentation.ActivityResult ar = mInstrumentation.execStartActivity( this , mMainThread.getApplicationThread(), mToken, this , intent, requestCode, options); ... } else { if (options != null ) { mParent.startActivityFromChild(this , intent, requestCode, options); } else { mParent.startActivityFromChild(this , intent, requestCode); } } }
主要是Context 的startActivity 时,要求一定要有 FLAG_ACTIVITY_NEW_TASK,否则就不能执行下去。还有,Activity 的startActivityForResult 中执行的 mParent.startActivityFromChild(),最终也是通过 mInstrumentation.execStartActivity 实现的,因此我们可以说Activity 的startActivity 最终也是通过 Instrumentation 的 execStartActivity 实现 。
Service 工作原理 Service 有两套流程,一套是启动流程,另一套是绑定流程:
在新进程启动 service 在新进程启动Service主要分为 5 个阶段:
App向 AMS 发送一个启动Service 的消息
AMS例行检查(是否在AndroidManifest中声明),查看目标Service 是否存在,如果存在就不管;如果不存在,则把Service信息保存下来,之后创建新进程
新进程启动后,通知AMS “我可以了”
AMS 把保存的Service信息发给新进程
新进程启动Service
当然,这个启动新进程,还是会启动 ActivityThread ,并且新进程启动Service 也是向 ActivityThread 的 H 类发送 START_SERVICE 来启动。
不管是前面的Activity ,还是后面的Service,创建对象时,都是通过 packageInfo(它是一个LoadedApk对象)去获取 ClassLoader,之后再通过反射创建出来 Activity 或者 Service 对象,四大组件的逻辑都是如此。所以,我们如果要做插件化,可以在这里做文章,换成插件的classLoder,加载插件中的四大组件 。
BroadCast 原理 注册过程 用Activity或者Context去注册,其实都是使用Context的registerReceiver方法,然后通过 AMN/AMP 把一个Receiver 传给AMS,在注册过程中,会使用 PMS 获取包信息,业绩 LoadedApk 对象。这个LoadedApk 对象的 getReceiverDispatcher 方法将传过来的 Receiver 封装成一个实现了 IIntentReceiver 接口的Binder 对象。我们实际上就是将这个 Binder 对象和 IntentFilter 对象传递给了 AMS。不过,这时发送广播是不知道发给谁的, 所以Activity所在的进程还要把自身的对象也发送给AMS。
这里都是动态注册广播,那静态广播呢?它是在App安装的时候注册。动态Receiver 与静态Receiver 分别存在AMS中不同的变量中,在发送广播时,会把两种 Receiver 合并到一起,其中动态的排在静态的前面,然后依次发送,因此,动态Receiver 永远先于静态Receiver收到消息。
发送过程 发送时,通过 AMN/AMP 发送广播给 AMS,广播中也带着 IntentFilter 对象。AMS 收到广播后,根据Filter 找到对应的Receiver,向广播接收者所在的进程发送广播 。Receiver 所在进程收到广播后,并不会直接发给Receiver,而是将广播封装成一个消息,(通过H类)发送到主线程的消息队列,当这个消息被处理时,才会把消息中的广播发送给 Receiver。
广播种类 无序广播、有序广播、粘性广播。这个粘性广播,用一个例子来了解:当电量小于 20%时,就会提示用户,而获取电池电量信息就是通过广播来实现的,一般的广播发完就完了,我们需要这样一种广播,发出后还能一直存在,未来的注册者也能收到这个广播,这种广播就是粘性广播 。
ContentProvider 工作原理 ContentProvider 的本质是把数据存储在SQLite 数据库中,但是封装成了统一的访问方式,比如对于数据集合而言,必须提供增删改查功能。我们在SQLite 上封装了一层,就成了 ContentProvider。
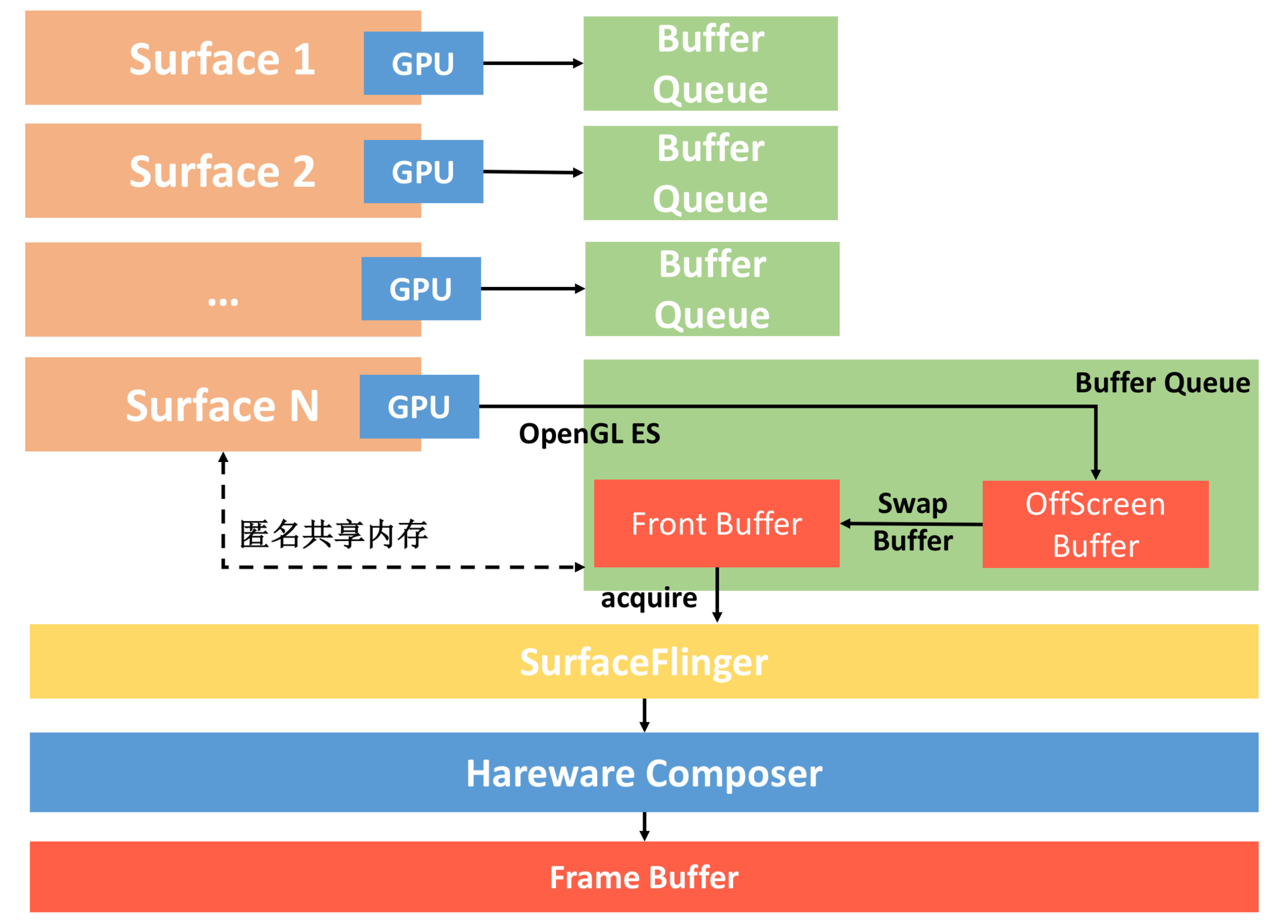
匿名共享内存(ASM) ContentProvider 读取数据使用了 ASM,并且,ASM实质上也是个Binder通信 ,下图为 ASM 类的交互关系图:
图中的 CursorWindow 就是匿名共享内存,这个流程简单来说分为3个步骤:
Client内部有一个 CursorWindow 对象,发送请求时,把这个CursorWindow 类型对象传过去,这个对象暂时为空
Server 收到请求,搜集数据,填充到这个CursorWindow 对象中
Client 读取内部这个CursorWindow 对象,获取数据。
举个例子就是: 你定牛奶,在家门口放个空箱子,送奶人每天早上往这个箱子放牛奶,你睡醒了去箱子里取牛奶,这个奶箱就是匿名共享内存 。
ContentProvider 与 AMS 的通信
App2发送消息给AMS,想要访问 App1 中的 ContentProvider
AMS 检查发现,App1的ContentProvider没有启动过(也即App1没启动,因为我们知道App启动时,在 Application的onCreate 之前就会启动ContentProvider,这也是 LeakCanary 新版免install的原理),为此新开一个进程启动App1
AMS获取App1启动的ContentProvider ,并把 ContentProvider 的代理对象返回给 App2
App2 拿到 ContentProvider 的代理对象,也就是 IContentProvider,就调用它的增删改查方法。
接下来就是使用 ASM(匿名共享内存) 传输数据,也就是上面提到的 CursorWindow 类,取得数据或者操作结果即可
PMS 及 App 安装过程 PMS简介 在前面我们介绍过,AMS会使用 PackageManagerService(简称PMS)加载包的信息,之后AMS会将这个信息封装在 LoadedApk 这个类对象中,然后我们就可以从中取出在AndroidManifest 中声明的四大组件信息了。
在安装App的过程中,会把 apk 复制到 data/app 目录 下。apk是一个zip压缩包,在文件头会记录压缩包的大小,所以就算在后续文件尾追加一部电影,都不会对解压造成任何影响。Android的多渠道打包其中的一种思路就是这样,在 apk 尾巴上追加几个字节,来标记apk的渠道,apk启动时,从apk尾巴上读取这个渠道值。不过,后来google发现了这个漏洞,在新版本系统中,系统安装apk时,会检查apk实际大小,二者不相等就会报错安装失败 。
这里回答前面提出的问题:为什么App安装不把它解压?其实,每次从apk读取资源,并不是先解压再找资源,而是解析apk中的resources.arsc文件,这个文件存储着资源的所有信息,包括资源在apk中的地址、大小等,按图索骥,可以很快拿到资源文件,这是一种很高效的算法。不解压的好处自然是节省空间 。
App安装流程 Android 系统使用PMS解析apk的AndroidManifest 文件,包括:
四大组件信息
分配用户id和用户组id,用户ID是唯一的,用户组id指的是各种权限,每个权限都在一个用户组中
Launcher 生成一个icon,icon中保存着默认启动Activity的信息
App 安装的最后,会把上面的信息记录在一个 xml文件中,以备下次安装使用
Android手机系统每次启动时,都会使用PMS,把Android系统中所有的apk都安装一遍 ,共4个步骤:
关于第1步,因为app安装过后,都会xml保存安装信息,所以Android系统再次启动后,就可以直接读取之前保存的xml 了。第2步就是从所有目录安装apk。
PakageParser PMS是系统进程,我们是不能Hook的。PMS中有个类:PackageParser ,它是专门用来解析 AndroidManifest 文件的,以获取四大组件信息以及用户权限。它有一个parsePackage 方法,接收一个apkFile 文件参数,这个参数既可以是 当前apk文件,也可以是 外部apk文件,我们可以使用这个方法来读取插件apk的信息 ,虽然PackageParser 类不对外开放,但是我们可以反射来获取这个类。
ActivityThread 与 PackageManager 对于App开发人员,可以通过 Context.getPackageManager() 来获取当前的 Apk 信息,但其实它在ContextImpl中的真正实现是通过 ActivityThread.getPackageManager() 来实现的。所以,我们一般可以通过反射 ActivityThread 来获取Apk 信息,注意,这里一般是获取宿主Apk 的包信息,而不是插件Apk包信息 。
ClassLoader 家族史 Android 插件化能加载外部下载的 Apk,就在于 ClassLoader。其中最重要的是 PathClassLoader 和 DexClassLoader,及其父类 BaseDexClassLoader。 PathClassLoader 和 DexClassLoader这两个类都很简单,粗看没啥区别,仔细看,构造函数第2个参数 optimizedDirectory 的值不一样,PathClassLoader 把这个参数设置为null,DexClassLoader 把它设置为一个非空的值。其实,这个值是用来缓存我们需要加载的dex文件的,并创建一个DexFile对象,如果为null,那么就会直接使用dex文件原有的路径来创建DexFile对象 。由于DexClassLoader 可以指定自己的 optimizedDirectory,所以它可以用来加载外部的dex;而PathDexClassLoader 没有这个参数,只能加载内部的dex(存在于系统中的已经安装过的apk里面)。
MultiDex 方法数超过65536 时,会有著名的 “65536”问题,一般来说我们使用 MultiDexApplication就能解决。Google还推出了 MultiDex 工具,它就是把原先的一个dex文件,拆分成多个dex文件,每个dex的方法数量不超过 65536。其中 classes.dex 称为主dex ,由App 使用PathClassLoader 加载,而 classes2.dex 等 dex 会在App 启动之后使用 DexClassLoader 进行加载。
在Android 5.0之后,虽然能够在dex中容纳比65536更多的方法数,但是dex的体积变大了,为了加快速度,我们还是可对dex进行拆分,classes.dex只保留App启动所需的类以及首页的代码,从而确保App花最少的时间启动并进入首页 ,而把其他的模块代码转移到其他dex中,这个技术称为手动分包,在后续会介绍。