在windows 10 上使用Android studio 开发,分分钟让你怀疑人生,编译运行一次看效果,5、6分钟很正常,7、8分钟是常有的事,忍无可忍,决心切换到 linux 环境。以个人的理解,Linux 的发行版都是基于相同的内核,所以比较各个发行版的时候,我个人主要比较 美观程度、使用方便程度以及可使用的软件数目。
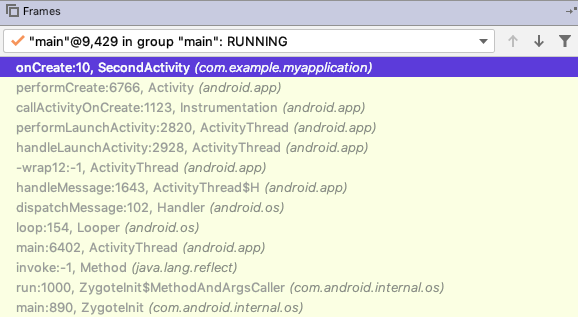
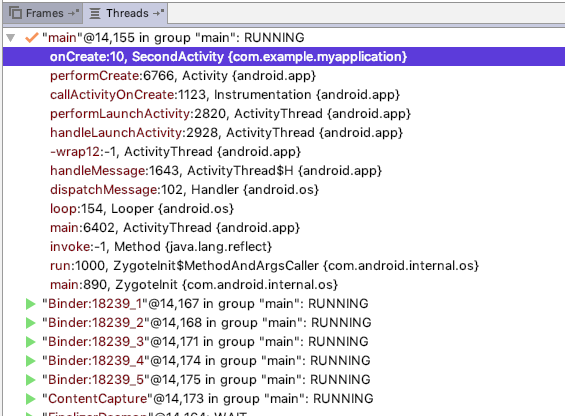
按照Android系统设计:”By default,all componets of the same application run in the same process and thread(called the “main” thread)”,这可以理解为,对于同一个AndroidManifest中定义的四大组件,除非有特别的声明,否则它们都运行在同一个进程中(并且均由主线程处理事件)。如何证明呢?根据前面操作系统的基础知识,如果两个对象处于同一个进程空间,那么内存区域应该是可共享访问的,利用这个原理我们可以论证下:
最终输出的结果是2,说明都是在同一个进程中,当然,我们还可以通过查看二者的 PID 和 TID 的方法证明这两个Activity默认确实在同一个进程中。当然,Android还提供了特殊方式让不是同一个包的组件也可以运行于相同的进程中,这样做的优势是,它们可以方便地资源共享,而不用大费周章地进程间通信。这可以分为两种情况:
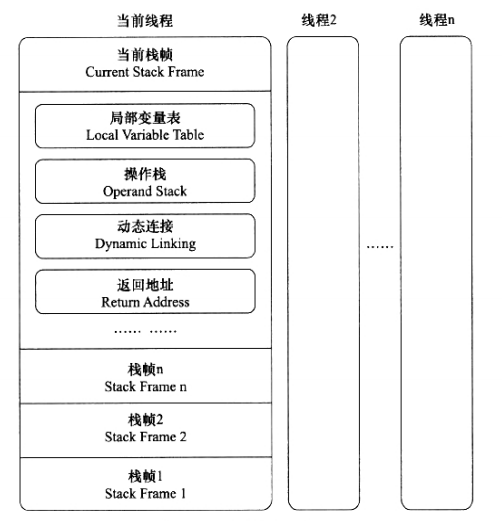
但是如果遇到一个方法,其后面的代码有一些耗时很长的操作,而前面又定义了占用了大量内存、实际上已经不会再使用的变量,手动将其设置为null值(代替上面例子中的 int a = 0,把变量对应的局部变量表中的空间清理掉)便不见得是一个绝对无意义的操作,这种操作可以作为一种在极特殊情形(对象占用内存大、此方法的栈帧长时间不能被回收、方法调用次数达不到JIT的编译条件)下的“奇技”来使用。
publicclassDynamicDispatch{ staticabstractclassHuman{ protectedabstractvoidsayHello(); } staticclassManextendsHuman{ @Override protectedvoidsayHello(){ System.out.println("man say hello"); } } staticclassWomanextendsHuman{ @Override protectedvoidsayHello(){ System.out.println("woman say hello"); } } publicstaticvoidmain(String[] args){ Human man = new Man(); Human woman = new Woman(); man.sayHello(); woman.sayHello(); man = new Woman(); man.sayHello(); } }
打印结果:
man say hello woman say hello woman say hello
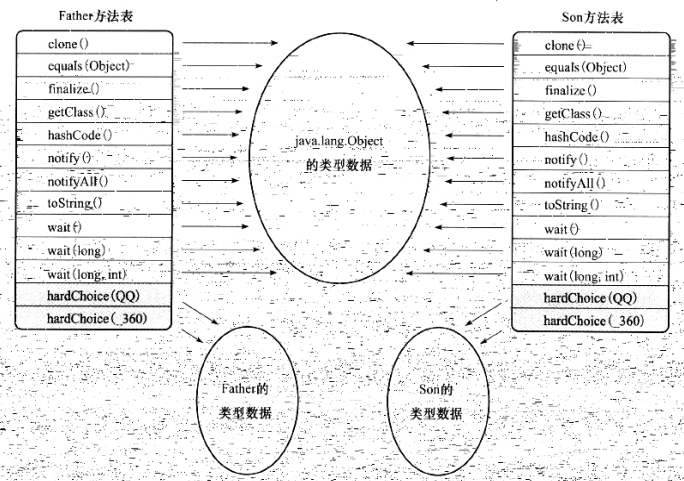
结果不出人意料,但是虚拟机是如何知道要调用哪个方法?这里显然不能再根据静态类型来决定,因为静态类型都是Human的两个变量 man 和woman 在调用 sayHello 方法时执行了不同的行为,并且man在两次调用中执行了不同的方法。因此可以看出,这只是因为变量的实际类型不同。因为invokevirtual指令的运行时解析过程大致如下:
再看看运行阶段虚拟机的选择,也即动态分派的过程。在执行 “son.hardChoice(new QQ())” 时,由于编译期已经决定目标方法的签名必须为 hardChoice(QQ) ,此时,参数的静态类型和参数的实际类型都对方法的选择不会构成任何影响(只要是QQ类型,管你是“腾讯QQ”还是“奇瑞QQ”),唯一可以影响虚拟机选择的因素只有方法接受者的实际类型是 Father 还是 Son ,因为只有一个宗量作为选择依据,所以Java语言的动态分派属于单分派类型。
publicclassStaticMainClass{ publicstaticvoidmain(String[] args){ StaticClassFarther farther = new StaticClassFarther(); StaticClassFarther mix = new StaticClassSon(); StaticClassSon son = new StaticClassSon();
case MotionEvent.ACTION_MOVE: //计算移动距离 int offsetX = x - lastX; int offsetY = y - lastY; //调用layout方法来重新确定它的位置 layout(getLeft() + offsetX,getTop()+offsetY, getRight()+offsetX,getBottom()+offsetY) break
case MotionEvent.ACTION_MOVE: //计算移动距离 int offsetX = x - lastX; int offsetY = y - lastY; //对left 及 right 进行偏移 offsetLeftAndRight(offsetX); //对top及bottom进行偏移 offsetTopAndBottom(offsetY); break;
velocityTracker.computeCurrentVelocity(1000); int xVelocity = (int)velocityTracker.getXVelocity(); int yVelocity = (int)velocityTracker.getYVelocity();
//序列化 User user = new User(12,"tom"); ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("cache.txt")); out.writeObject(user); out.close();
//反序列化过程 ObjectInputStream in = new ObjectInputStream(new FileInputStream("cache.txt")); User newUser = (User)in.readObject(); in.close();