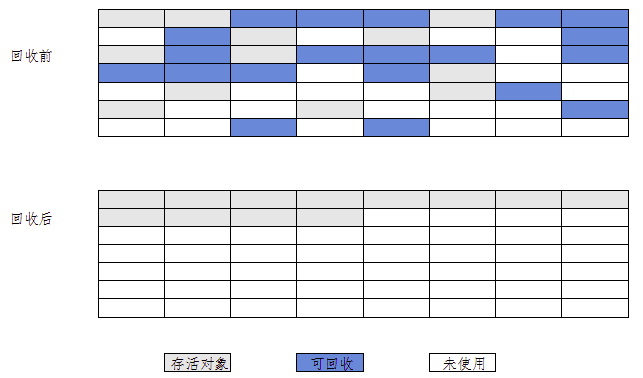
1、整个老年代的内存划分为 A 和 B 两个区域,区域 A 的大小是所有还存活对象的总大小,区域 B 大小是是剩余空间。 2、按顺序在 A 中找到第一个还存活对象,将它移动到 A 空间的最前端,接下来找第二个还存活的对象,将其移动到第一个对象的后面 3、以此类推,即使存活的对象在 B 中也一样顺序复制到A中,直至最后填满A空间,之后清除 B 空间。
这是自己添加的这个标题,书中的结构并不是如此,因为 Android ART 虚拟机使用的也是CMS收集方式,所以这里特意抽出来理解,方便理解Android的虚拟机。 CMS (Concurrent Mark Sweep) 收集器,并发的“标记-清除”方式实现的收集器。它是一种以获取最短回收停顿时间为目标的收集器。它的整个过程分为4个步骤:
发生Minor GC 前,虚拟机会检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果条件成立,则 Minor GC 可以确保是安全的,如果不成立,则会判断是否允许担保失败,如果允许担保失败,则最终可能会触发一次Full GC。虽然绕了一圈还是有可能触发 Full GC,但是这种情况相对较少。
publicstaticvoidmain(String[] args){ //使用List保持常量池的引用,避免full gc 回收常量池 List<String> list = new ArrayList<String>(); int i = 0; while(true){ list.add(String.valueOf(i++).intern()); } }
同样的原因,还可以引申一个更有意思的影响,如下代码:
1 2 3 4 5 6 7
publicstaticvoidmain(String[] args){ String str1 = new StringBuilder("计算机").append(“软件”).toString(); Systemt.out.println(str1.intern() == str1); String str2 = new StringBuilder("ja").append("va").toString(); Systemt.out.println(str2.intern() == str2); }
public Looper getLooper(){ if (!isAlive()) { returnnull; } // If the thread has been started, wait until the looper has been created. synchronized (this) { while (isAlive() && mLooper == null) { try { wait(); } catch (InterruptedException e) { } } } return mLooper; }
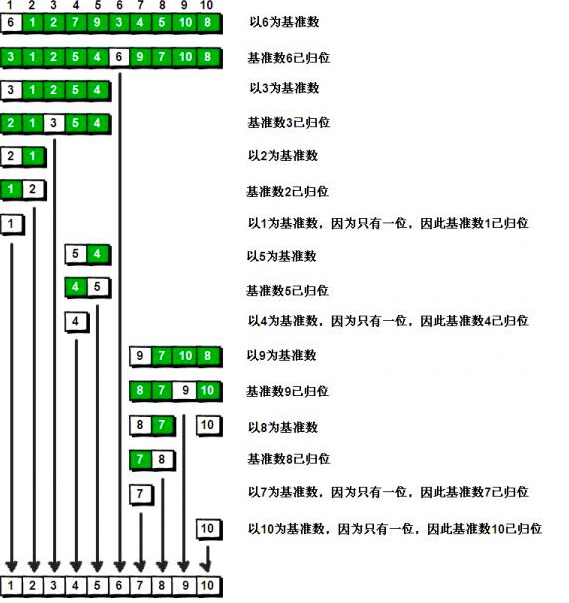
即第一趟:首先比较第1个和第2个数,将小数放前,大数放后。然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。之后便是重复第一趟步骤,直至全部排序完成(或者说直到某一趟没有发生交换的时候)。每一趟完成后,最后一个数肯定是最大的那个数,所以一次for循环后,会有 len – 操作,即每趟都比上一趟少比较一次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
privatestaticvoidbubbleSort1(int[] ints){ int len = ints.length; boolean flag = true; while (flag) { flag = false; for (int i = 1; i < len; i++) { if (ints[i - 1] > ints[i]) { int temp = ints[i]; ints[i] = ints[i-1]; ints[i-1] = temp; flag = true; } } len -- ; } }
privatestaticvoidheapSort(int[] arr){ int arrLen = arr.length; int temp; //建立大顶堆 for (int i = arrLen/2 -1;i>=0;i--){ //从第一个非叶子结点(在 arrLen/2 -1 处)从下至上,从右至左调整结构 adjustHeap(arr,i,arrLen);
//非递归,手算的思想,先变访问边找,找到最左下方的,然后向上再向访问右边的 publicstaticvoiditerativePreOrder(TreeNode p){ if (p == null) return; Stack<TreeNode> stack = new Stack<TreeNode>(); while (!stack.empty() || p != null) { while (p != null) { visit(p); stack.push(p); p = p.left; } p = stack.pop(); p = p.right; } }
//栈的思想,按层次倒着进栈,利用后进先出解决顺序问题 publicstaticvoiditerativePreOrder_2(TreeNode p){ if (p == null) return; Stack<TreeNode> stack = new Stack<TreeNode>(); stack.push(p); while (!stack.empty()) { p = stack.pop(); visit(p); if (p.right != null) stack.push(p.right); if (p.left != null) stack.push(p.left); } }
publicstaticvoiditerativeInOrder(TreeNode p){ if (p == null) return; Stack<TreeNode> stack = new Stack<TreeNode>(); while (!stack.empty() || p != null) { while (p != null) { stack.push(p); p = p.left; } p = stack.pop(); visit(p); p = p.right; } }
//双栈法,易于理解 publicstaticvoiditerativePostOrder_3(TreeNode p){ if (p == null) return; Stack<TreeNode> stack = new Stack<TreeNode>(); Stack<TreeNode> result = new Stack<TreeNode>(); while (!stack.empty() || p != null) { while (p != null) { stack.push(p); result.push(p); p = p.right; } if (!stack.empty()) p = stack.pop().left; } while (!result.empty()) { p = result.pop(); visit(p); } }
层次遍历
点击看答案
1 2 3 4 5 6 7 8 9 10 11
publicstaticvoiditerativeLevelOrder(TreeNode p){ if (p == null) return; LinkedList<TreeNode> queue = new LinkedList<TreeNode>(); queue.offer(p); while (!queue.isEmpty()) { p = queue.poll(); if (p.left != null) queue.offer(p.left); if (p.right != null) queue.offer(p.right); visit(p); } }
//顺序与 随机位置交换 Random r = new Random(); for (int i = 0; i < oneCard.size(); i ++){ int j = r.nextInt(52); Card tempCard = oneCard[i]; oneCard[i] = onCard[j]; onCard[j] = tempCard; }
我们假定链表头到环入口的距离是len,环入口到slow和fast交汇点的距离为x,环的长度为R。slow和fast第一次交汇时,设slow走的长度为:d = len + x,而fast走的长度为:2d = len + nR + x,(n >= 1),从而我们可以得知:2len + 2x = len + nR + x,即len = nR - x,(n >= 1)。所以,要找出环入口,也要两个指针,一个指针A指向相遇时候的节点,一个指针B指向链表头,两个指针每次都走一步,A指针在遍历过程中可能多次(n >= 1)经过环入口节点,但当B指针第一次达到入口节点时,A指针此时必然也指向入口节点。