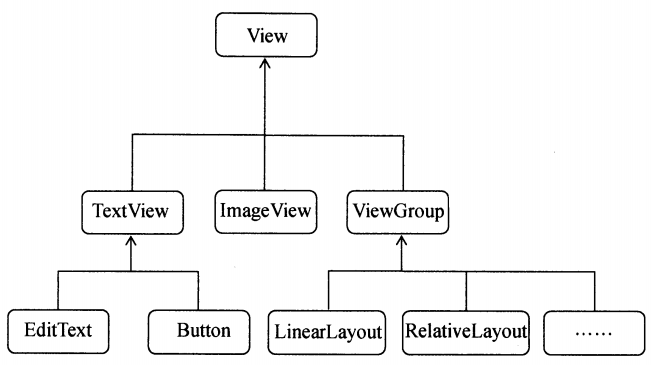
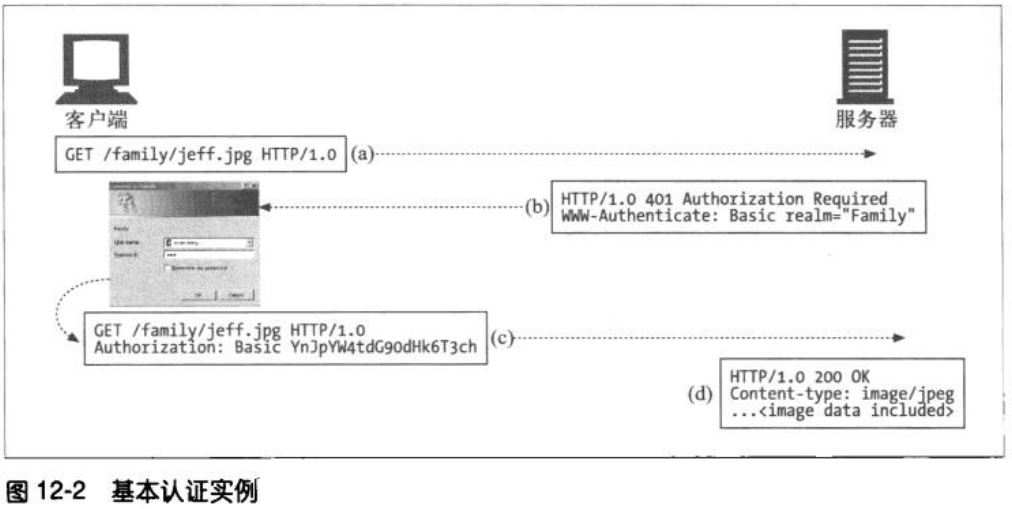
这一章前面部分主要讲解Fragment的基本使用,这点我觉得官方文档关于fragment的知识可能会更好一些,以下是官方的阐述:
主要是平时使用Fragment时,对其使用方法有疑惑,以下或许能解释部分:
为什么使用Fragment
参考自官方:主要是为了在大屏幕手机(如平板电脑)上更加零落的UI设计,可以更方便地组合和交换UI组件。
Fragment的创建
想为Fragment提供布局,则必须实现onCreateView()回调,可以通过xml定义布局资源,为此,onCreateView()提供了一个LayoutInflater对象:
public static class ExampleFragment extends Fragment {
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
// Inflate the layout for this fragment
return inflater.inflate(R.layout.example_fragment, container, false);
}
}向Activity中添加Fragment
1、在Activity的布局文件中声明:
<?xml version="1.0" encoding="utf-8">
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:orientation="horizontal"
android:layout_width="match_parent"
android:layout_height="match_parent">
<fragment android:name="com.example.ListFragment"
android:id="@+id/list"
android:layout_weight="1"
android:layout_width="0dp"
android:layout_height="match_parent" />
<fragment android:name="com.example.AticleFragment"
android:id="@+id/viewer"
android:layout_weight="2"
android:layout_width="0dp"
android:layout_height="match_parent" />
</LinearLayout>官方解释:Activity初始化布局时,会实例化布局中指定的每个fragment,并为每个Fragment调用onCreateView()方法,系统会直接插入Fragment返回的View来替代
元素。
2、通过编程方式将Fragment添加到某个现有的ViewGroup:
可以在Activity运行期间将Fragment添加进去,你只需要指定Fragment要放入哪个ViewGroup,这需要使用FragmentTransaction:
FragmentManager fragmentManager = getFragmentManager();
FragmentTransaction transaction = fragmentManager.beginTransaction();然后,你可以使用add()方法添加一个fragment:
ExampleFragment fragment = new ExampleFragment();
transaction.add(R.id.fragment_container,fragment);
transaction.commit();一旦通过FragmentTransaction做出了更改,就必须commit以使更改生效。
3、添加没有UI的Fragment:
你可以使用Fragment为Activity提供后台行为,而不显示额外的UI。使用函数:
add(Fragment,String)String类型参数为Fragment提供一个唯一的字符串标记,由于Fragment没有雨Activity中的视图关联,因此不会收到onCreate()调用,因此你可以不实现这个方法。如果你稍后想从Activity中获取到这个Fragment,可以使用findFragmentByTag()。
可以在SDK的sample中查看具体用法:
/APIDemos/app/src/main/java/com/example/android/apis/app/FragmentRetainInstance.java
执行Fragment事务
需要使用FragmentTransaction,可以使用:
add() 、remove() 、replace()等方法设置想要执行的更改,然后commit生效。
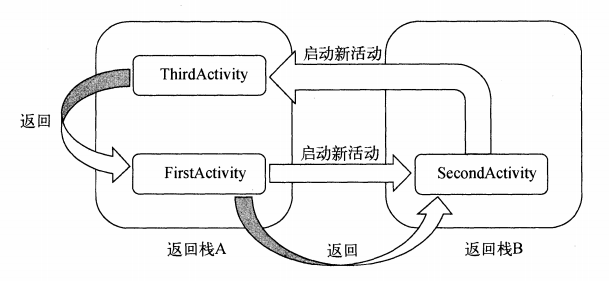
不过在commit之前你可能想调用 addToBackStack()将其添加到Fragment事务返回栈,允许用户按返回键返回上一Fragment状态。
来个例子:
/**create new fragment and transaction**/
Fragment newFragment = new ExampleFragment();
FragmentTransaction transaction = getFragment().beginTransaction();
/**Replace whatever is in the fragment_container view with this fragment
and add the transaction to the back stack**/
transaction.replace(R.id.fragment_container,newFragment);
transaction.addToBackStack(null);
//commit the transaction
transaction.commit();向FragmentTransaction添加更改的顺序无关紧要,但有一些注意事项:
commit操作不会立即执行,而是等主线程认为可以执行的时候再运行,不过,如果有必要,你也可以从主线程调用executePendingTransactions() 以立即执行commit。
最后必须调用commit,而且只能在用户离开Activity之前commit,否则会引发异常,如果对于需要commit的更改无关紧要,可以使用commitAllowingStateLoss()。
可以向同一个容器中添加多个fragment,你添加的顺序决定他们在视图层次结构中出现的顺序。
管理Fragment
需要使用FragmentManager,你可以使用它执行以下操作:
findFragmentById() (对于在Activity布局中提供UI的Fragment)或者findFragmentByTag()(对于提供或者不提供UI的Fragment都可)。
popBackStack() (模拟用户发出的返回命令),将Fragment从返回栈中弹出。
addOnBackStackChangedListener() 监听返回栈变化
与Activity通信
Fragment可以通过getActivity()访问Activity实例,并轻松执行诸如在Activity布局中查找视图等任务:
View listView = getActivity().findViewById(R.id.list);同样,Activity也可以使用findFragmentById 或者 findFragmentByTag,通过从FragmentManager获取Fragment的引用来调用Fragment中的方法:
ExampleFragment fragment = (ExampleFragment) getFragmentManager().findFragmentById(R.id.example_fragment);一个应用场景例子
一个新闻应用中Activity两个Fragment,Fragment A放列表list,Fragment B 放对应内容,那么A在列表项选定后,告诉Activity,以便Activity通知B显示该新闻。其方案可以这样设计:
在A中声明接口OnArticleSelectedListener :
public static class FragmentA extends ListFragment {
...
// Container Activity must implement this interface
public interface OnArticleSelectedListener {
public void onArticleSelected(Uri articleUri);
}
...
}同事在Activity中实现接口OnArticleSelectedListener,在A的onAttach方法时判断Activity是否这样做了:
public static class FragmentA extends ListFragment {
OnArticleSelectedListener mListener;
...
@Override
public void onAttach(Activity activity) {
super.onAttach(activity);
try {
mListener = (OnArticleSelectedListener) activity;
} catch (ClassCastException e) {
throw new ClassCastException(activity.toString() + " must implement OnArticleSelectedListener");
}
}
...
}当有点击事件的时候,A看起来是这样子的:
public static class FragmentA extends ListFragment {
OnArticleSelectedListener mListener;
...
@Override
public void onListItemClick(ListView l, View v, int position, long id) {
// Append the clicked item's row ID with the content provider Uri
Uri noteUri = ContentUris.withAppendedId(ArticleColumns.CONTENT_URI, id);
// Send the event and Uri to the host activity
mListener.onArticleSelected(noteUri);
}
...
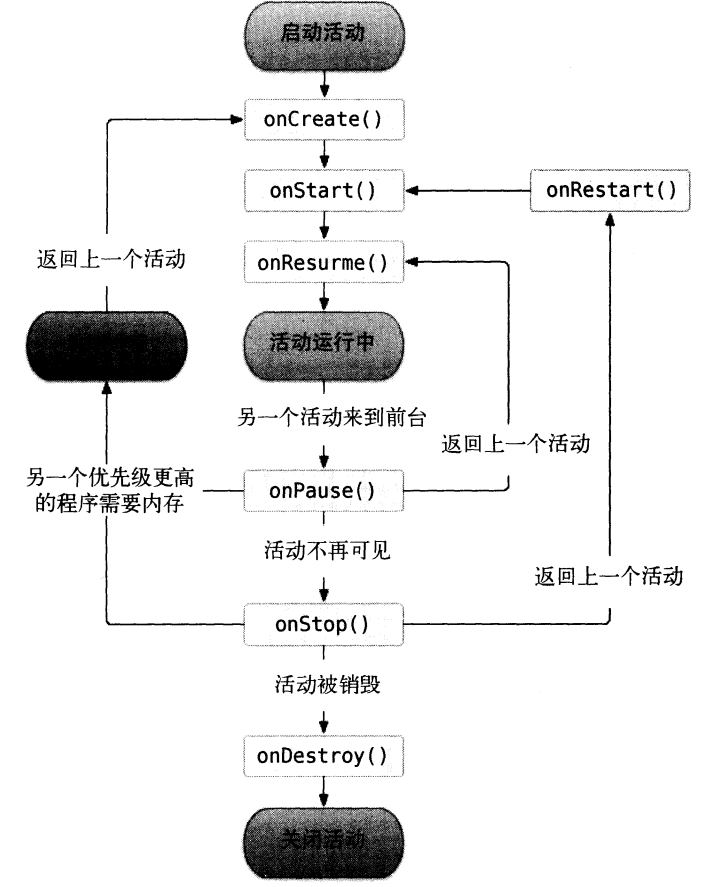
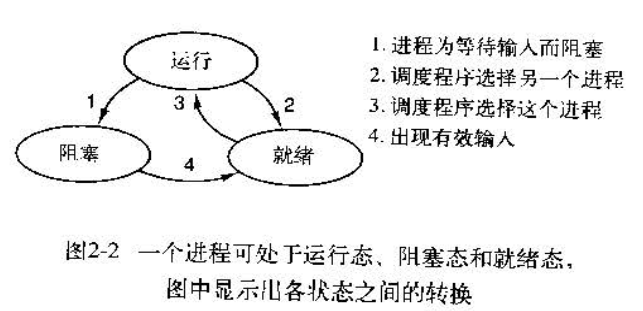
}Fragment的生命周期如下图:
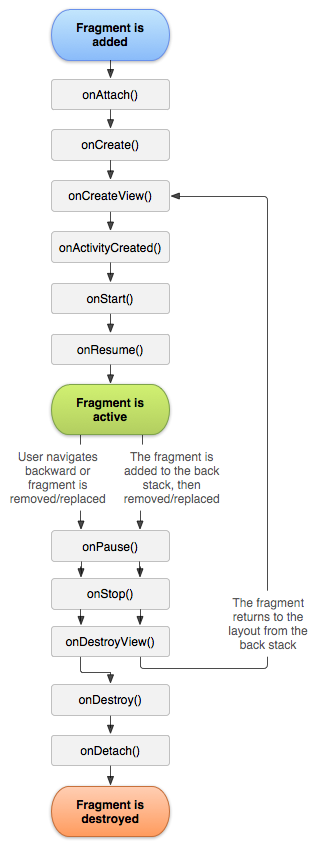
其中将fragment进行至fragment的resume状态(即可以跟用户交互)的核心序列如下:
onAttach(Activity) :activity与fragment关联的时候调用.
onCreate(Bundle) :fragment初始化的时候调用.
onCreateView(LayoutInflater, ViewGroup, Bundle) :为fragment创建返回view界面.
onActivityCreated(Bundle): 通知fragment它绑定的那个Activity已经执行完了onCreate()操作.
onViewStateRestored(Bundle): 通知fragment它保存的view state已经被恢复了.
onStart(): fragment对用户可见 (还要取决于包含这个fragment的activity是否已经启动了).
onResume(): 使fragment可以和用户交互了 (还要取决于包含这个fragment的activity是否已经resume了).
如果一个fragment不再使用了,它会执行一系列相反的过程:onPause(): fragment不能与用户交互(可能是由于activity的pause)。
onStop(): fragment不可见了(可能是由于activitystop了)。
onDestroyView():通知fragment清理与它相关的view资源。
onDestroy():在完全清理fragment的状态时调用。
onDetach():当fragment与activity解除绑定时调用。
动态加载布局的技巧
使用限定符
如果使用平板就会发现里面的应用基本上是双页模式,但是在手机上限于屏幕大小,都是单页模式。如果判断该使用双页模式还是单页模式,这就要借助限定符(qualifiers)来实现了,我们可以有两个布局文件,一个 layout_single.xml 单页模式布局放在layout目录,一个 layout_double.xml 双页模式布局放在 layout-large 目录,其中的large是个限定符。Android中常用限定符如下:

使用最小限定符
前面解决了单页双页模式,但是到底怎么才算large,我们需要更精确地控制的话,需要最小限定符。我们新建layout-600dp文件夹,将双页布局文件放入其中,这样就会意味着,当程序运行在宽度小于600dp的设备上时,显示的是单页布局,否则使用的是双页布局。
以上两种技巧可以将手机版和pad版都使用同一个app,避免维护多个app,一处改动,需要在两个app中同步改动。注意在代码中区别目前是双页模式还是单页模式,可以用以下方式:
1 | if(findViewById(R.id.anotherpageid) == null){ |
其中R.id.anotherpageid是在单页中所没有的那个布局的id。