// 循环? // 获取被 ARouter注解的 "类节点信息" Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(ARouter.class); for (Element element : elements) { // for 3 // 1 element == MainActivity 2 element == MainActivity2
// Top-level build file where you can add configuration options common to all sub-projects/modules. buildscript { repositories { google() jcenter() } dependencies { classpath "com.android.tools.build:gradle:4.0.1"
// NOTE: Do not place your application dependencies here; they belong // in the individual module build.gradle files } }
public <T> T create(final Class<T> service){ validateServiceInterface(service); return (T) Proxy.newProxyInstance( service.getClassLoader(), new Class<?>[] {service}, new InvocationHandler() { privatefinal Object[] emptyArgs = new Object[0];
@Override public@NullableObject invoke(Object proxy, Method method, @Nullable Object[] args) throws Throwable { // If the method is a method from Object then defer to normal invocation. if (method.getDeclaringClass() == Object.class) { return method.invoke(this, args); } args = args != null ? args : emptyArgs; Platform platform = Platform.get(); return platform.isDefaultMethod(method) ? platform.invokeDefaultMethod(method, service, proxy, args) : loadServiceMethod(method).invoke(args); } }); }
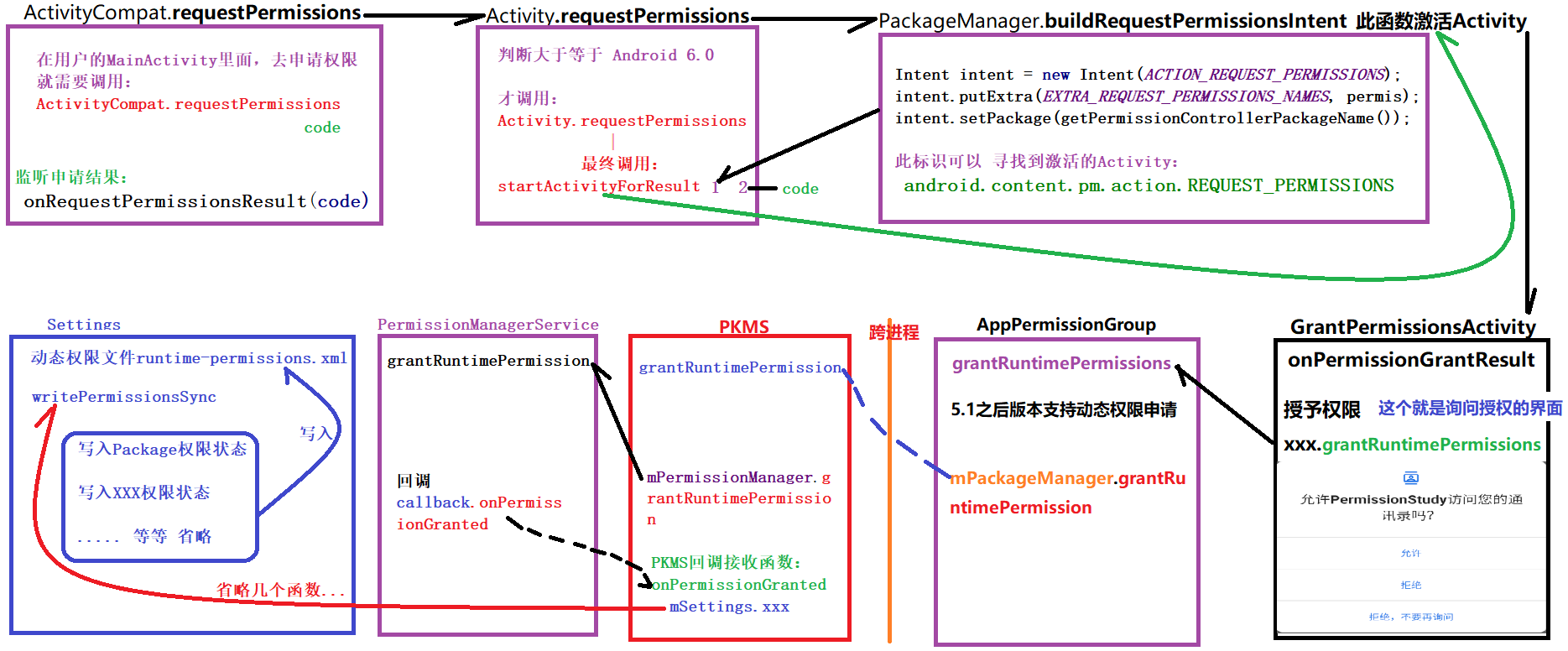
publicfinalvoidrequestPermissions(@NonNull String[] permissions, int requestCode){ if (requestCode < 0) { thrownew IllegalArgumentException("requestCode should be >= 0"); } if (mHasCurrentPermissionsRequest) { Log.w(TAG, "Can request only one set of permissions at a time"); // Dispatch the callback with empty arrays which means a cancellation. onRequestPermissionsResult(requestCode, new String[0], newint[0]); return; } Intent intent = getPackageManager().buildRequestPermissionsIntent(permissions); startActivityForResult(REQUEST_PERMISSIONS_WHO_PREFIX, intent, requestCode, null); mHasCurrentPermissionsRequest = true; }
这里面有个小的知识点,Intent 是通过 build 创建出来的,这里是启动隐式的 App:
1 2 3 4 5 6 7 8 9
public Intent buildRequestPermissionsIntent(@NonNull String[] permissions){ if (ArrayUtils.isEmpty(permissions)) { thrownew IllegalArgumentException("permission cannot be null or empty"); } Intent intent = new Intent(ACTION_REQUEST_PERMISSIONS); intent.putExtra(EXTRA_REQUEST_PERMISSIONS_NAMES, permissions); intent.setPackage(getPermissionControllerPackageName()); return intent; }
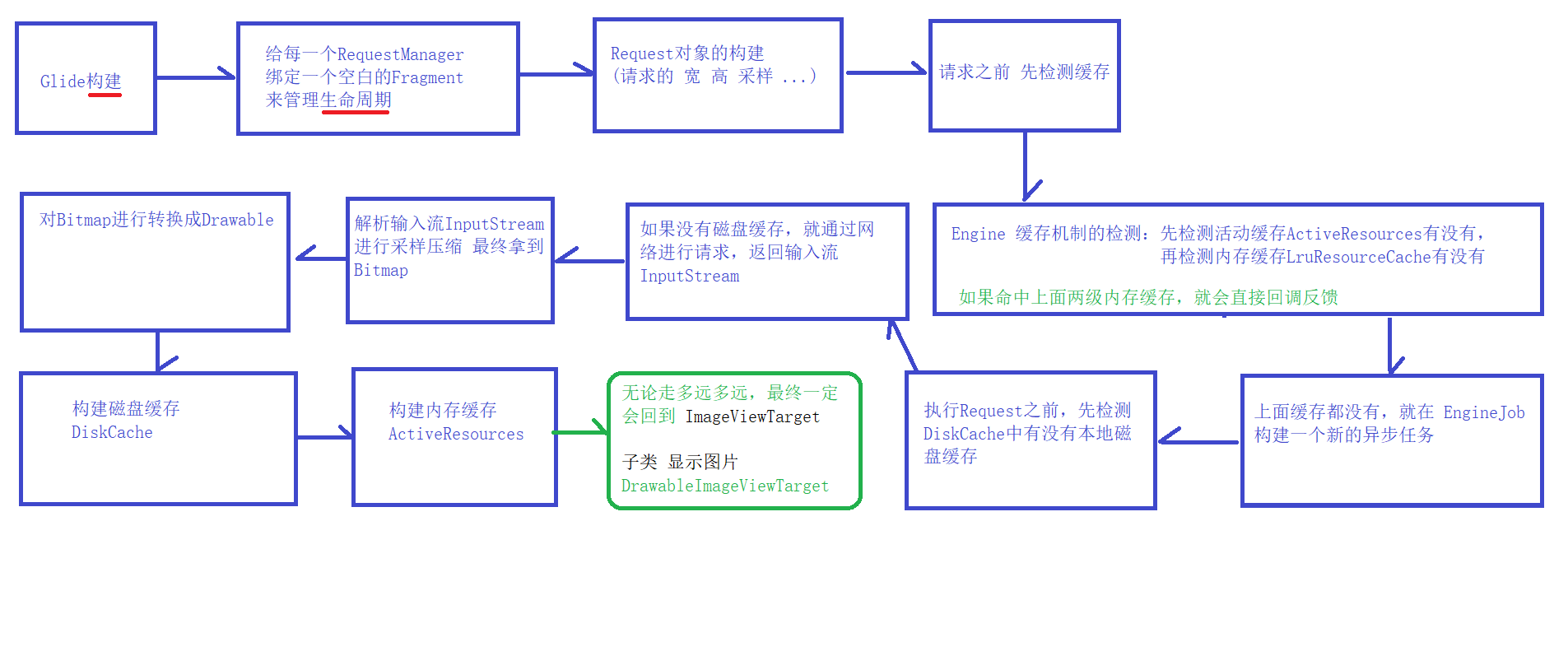
public ViewTarget<ImageView, TranscodeType> into(@NonNull ImageView view){
if (!requestOptions.isTransformationSet() && requestOptions.isTransformationAllowed() && view.getScaleType() != null) {
switch (view.getScaleType()) { case CENTER_CROP: requestOptions = requestOptions.clone().optionalCenterCrop(); break; case CENTER_INSIDE: requestOptions = requestOptions.clone().optionalCenterInside(); break; case FIT_CENTER: case FIT_START: case FIT_END: requestOptions = requestOptions.clone().optionalFitCenter(); break; case FIT_XY: requestOptions = requestOptions.clone().optionalCenterInside(); break; case CENTER: case MATRIX: default: // Do nothing. } }