一、重试重定向拦截器-重试限制
首先判断是否取消了,取消了直接抛出异常
之后在 try-catch 代码块里面执行责任链获取 response,并且捕捉 RouteException (路线异常,比如 socket 连接失败)和 IOException (IO 异常),在这 2 种 异常中判断是否需要重试,调用的是 recover 函数:
1 | //检查是否需要重试 |
可以看出,检查是否需要重试,如果不需要,直接抛出异常就终止了,否则才继续往后面走重试。那么是否需要重试的条件是什么呢? 有以下几点:
OkHttpClient 可以配置是否允许重试,设置为 false 直接不能重试
request body 不允许复用,那就不能重试
产生了 FileNotFoundException 异常,也不用重试了
产生了不允许重试的异常(协议异常-如返回204代表无响应体,但是Content-Lenth 不为0,二者产生冲突,就是协议异常了、证书异常、除连接超时之外的 IO 中断异常)
最后一关,是否有拥有更多路线(设置了代理,DNS 返回了多个 ip -应该重试其他ip),即使上面的判断都通过,只要没有更多路线,都不能重试
重定向限制次数,20 次
二、重试重定向拦截器-重定向规则
次数超出 20 次,也抛出异常。
代码中是通过 followUpRequest 方法来确定重定向的,同过 response 的响应码来判断响应码,这个重定向看起来不只是重定向功能,如果只是重定向,可能只需要判断 3xx 这个码就可以了,实际上,这里面判断多个码,包括:
3xx:重定向
401:服务器需要授权,比如某些接口需要登录
407:代理需要授权,比如付费代理,验证身份
408:请求超时
421:当前客户端所在的ip到服务器的连接数超了
503:服务不可用
个人觉得准备面试的话就记住 3xx、需要授权、连接数超了这几个基本上就可以了
代理有 2 种,HTTP 代理和 Socket 代理,Http代理代理的是 Http,Socket 代理它代理的是 TCP/IP
三、桥接拦截器
桥接拦截器主要功能就是在请求前和请求后做一些通用繁琐处理:
请求前补全请求头(设置cookie、设置UA、设置Host字段、content-Length 、Content-Type 、Gzip 压缩等)
得到响应后:接收 Cookies 并回调给用户,在下次请求的时候读取相应 cookies 数据设置到请求头;如果有设置 gzip ,则解析 gzip 数据
四、缓存拦截器
关于缓存的请求头和响应头非常多,所以这里很复杂,Http 的缓存我们可以按照行为分为: 强缓存 和 协商缓存。
强缓存: 有缓存的时候,直接将缓存给用户,不会发送请求给服务端,可以通过 Cache-Control 和 Expires 来判断缓存过期时间。
协商缓存:请求还是会发给服务端,但是服务端可能会返回 304 (此时没有请求体的),意味着服务端在这段时间没有修改,使用本地的缓存就好。
如果 networkReqeust 存在,则优先发起网络请求,否则使用 cacheResponse 缓存,若都不存在则请求失败。
五、连接拦截器-新建连接
代码很少,总共就 4 行代码
在这里来判断是 http1 还是 http2。找到连接之后,还需要连接是否健康(未关闭,正常工作),
普通代理:可以想象 Fiddler,它是可以更改你的数据再发送出去的
隧道代理:是无法更改客户端的请求的,将客户端的数据无脑地发送给服务端
Okhttp 支持你创建代理,可以选择是 Http 代理还是 Sockets 代理。老师有写这些代理使用的方式,有现成代码,这里就不贴出来了。
ALPN 是 TLS 的扩展协议,从 与 服务端的 hello 里面可以协商到使用哪一种协议。会存储在 sslSocket 中
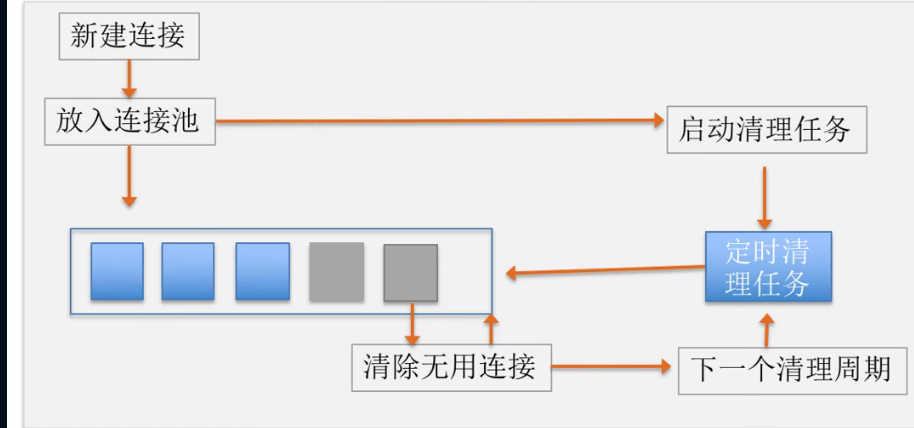
六、连接拦截器-连接池
首先从连接池中获取连接,如果没有,才去做上述的新建连接。
每次put 新的连接到池子里面的时候,都会扔进去一个定时执行的 Task,用于执行 clean 任务,清除不可用的连接,无效的连接。不移走会占用内存。比如,你刚创建的连接,那么5分钟后肯定会过期,如果没有使用的话
连接池最多允许 5 个空闲连接;连接池中闲置的连接最多允许闲置 5 分钟。比如,某个连接 baidu.com 只使用了一次,这样就能将其清理掉。清理的时候,将闲置时长最长的清理掉。
七、请求服务拦截器与面试总结
发送很简单,这里就不写了,有个点需要注意下,如果是发送个比较大的文件,是需要与服务端协商的,Okhttp 是这样做的:
如果服务器允许则返回 100 ,则客户端继续发送请求体
如果服务器不允许就直接返回给用户
如果服务器忽略这个问询的请求头,一直无法读取应答,此时会抛出超时异常
7.1 面试题
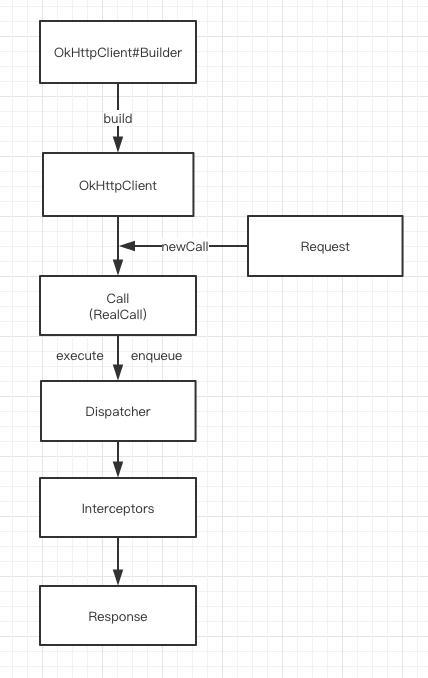
Okhttp 的请求过程
构建 Request ,通过 OkhttpClient 获得 Call (RealCall对象)如果:
是同步请求,则在发起请求的线程中直接获取结果(调用5个Interceptor)
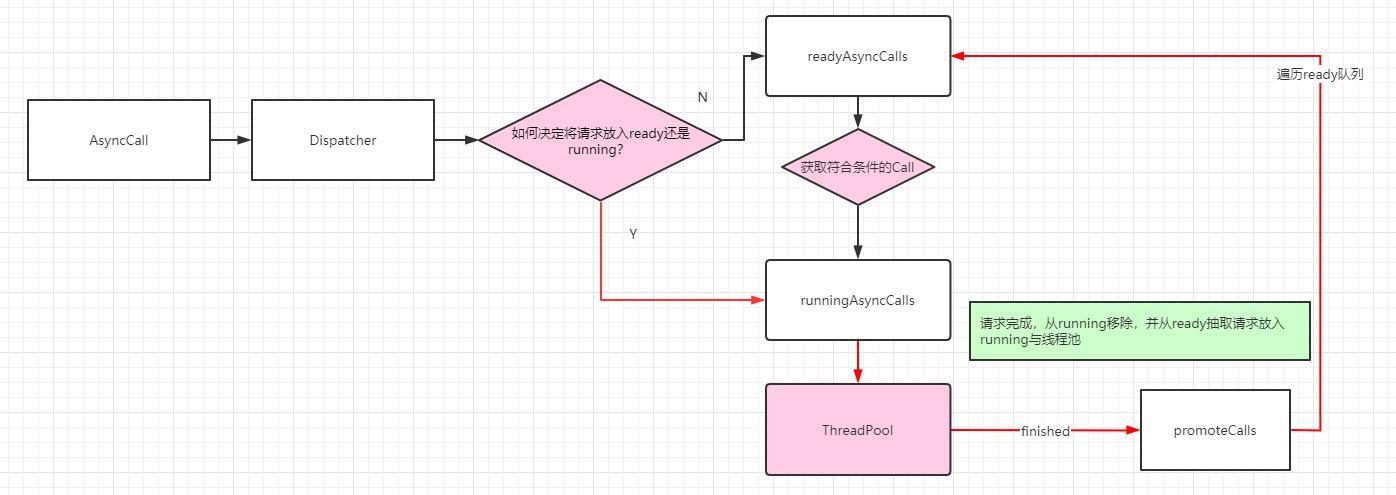
如果是异步请求,则通过 Dispatcher 分发到线程池中进行请求获取结果(也是调用5个Interceptor)
拦截器如何工作的?
责任链模式将请求者与执行者解耦,请求者只需将请求发送给责任链即可
应用拦截器与网络拦截器的区别?
他们在 interceptors 中的顺序不一样
网络拦截器不一定执行,因为有可能直接拿了缓存,不需要后续的执行了
Okhttp 如何复用连接?
host 验证规则一样、dns 一样等等,这些属性都一样。当然,也会清理垃圾连接,超过 5 分钟没有使用的连接,超过5个闲置连接后,清理闲置最久的连接