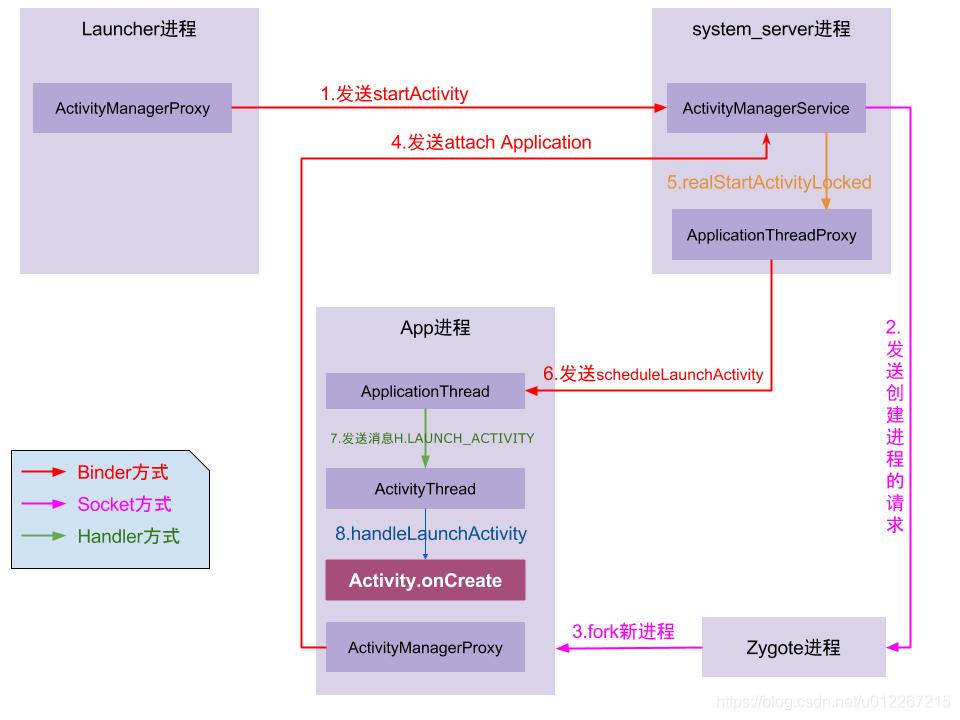
一、Window 总览
window 是屏幕上一块区域,但不是实实在在的,实际显示的是 View 。WMS、WindowManager 以及 Window 之间的关系如下:
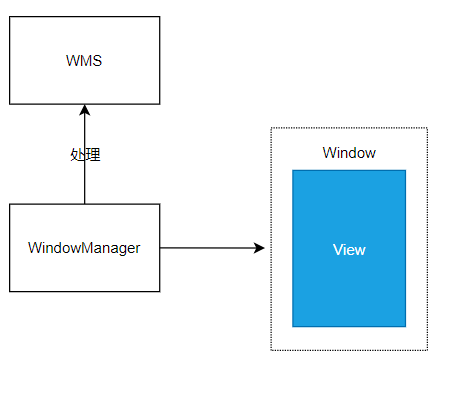
Window: 窗口的概念,Android 中所有的师徒都依赖于 Window 显示
WindowManager : 管理 Window ,包括 增、删、更新 等操作,类似一个代理的概念,最终要丢给 WMS 去实际操作。
WMS : Window 最终管理者,负责 window 的启动、添加、删除,Window 的大小和层级也是 WMS 管理的
1.1 Window 分类
Application Window
xxxx
statusBar 和 searchBar 等居然也都是 System Window 。
打电话时,脸靠近手机的时候,黑屏 以及 脸不能按屏幕上的按钮,这些都是 Window 的标记来实现的。
二、WindowManager
WindowManager 在应用层。WindowManager 是继承了 ViewManager 的,这里发散以下, ViewGroup 也是实现了 ViewManager ,联动一下。
Activity 的 attach 方法里面,会创建 Window ,以及 绑定到 WindowManager 。
Activity 中 Window 下最直接管理的 View 是 DecorView ,示意图如下:
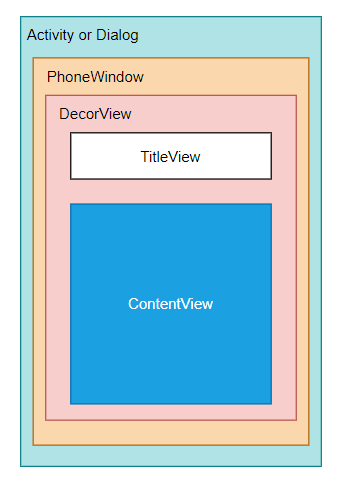
注意,我们平时在代码中调用 setContentView 是我们上图蓝色部分的 ContentView 吗?答案不是的,我们 setContentView 的 View 到时候会作为上述 蓝色 ContentView 的子 View 。
我们都说onResume 的时候,是可见可操作的。这里其实应该是Activity 可见 ,就是 Activity 已经创建好了!但其实里面的元素还是不可见的,因为 performResume 之后,才会执行 window.addView 将 View 添加进去,所以,要注意区分。
WindowManagerGlobal 主要的职责是:
设置view的参数(layoutparams)
创建 ViewRootImpl
其中,WindowManagerGlobal 的 addView 方法中会创建 ViewRootImpl 的对象。
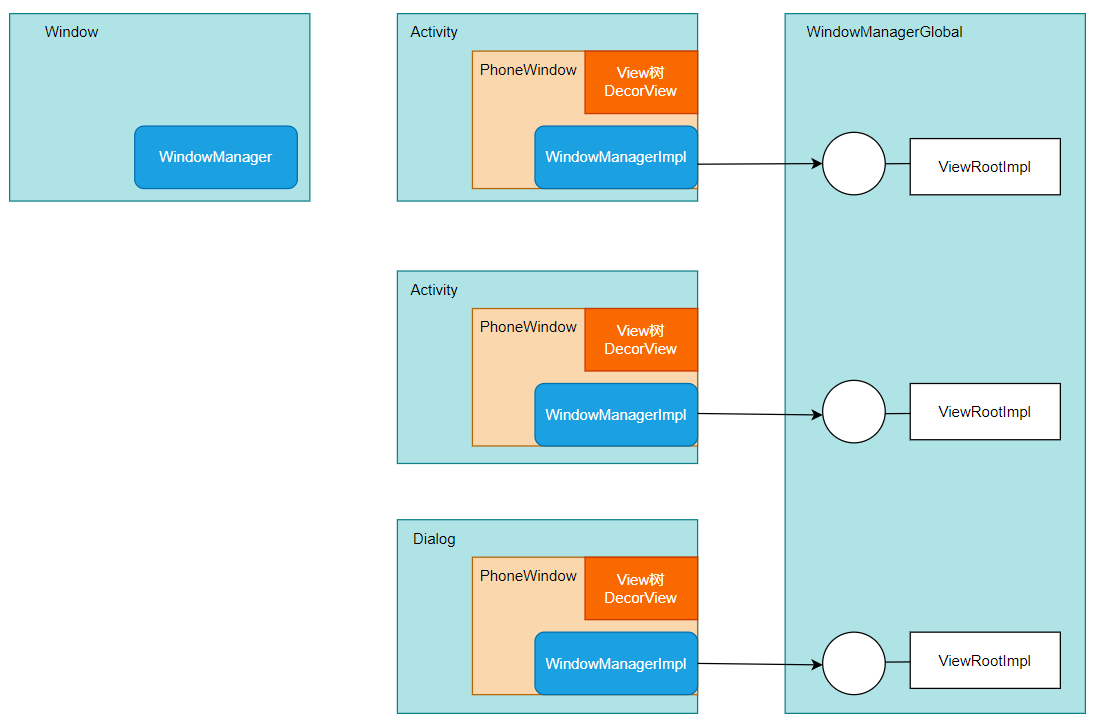
总结一下各方关系就是:每个 Activity 都有一个 PhoneWindow ,每个 PhoneWindow 中有个根 View——DecorView ,并且PhoneWindow 中有个 WindowManagerImpl 用于管理 Activity 中 VIew 的细节,然后 WindowManagerGlobal 用于全局管理所有的 WindowManagerImpl ,示意图如下所示:
三、绘制流程
在 ViewRootImpl 中,接收到同步信号的时候,就会触发 performTraversalses() 方法,在里面会执行 performMeasure、performLayout、performDraw 等,
ViewRootImpl
ViewRootImpl 的功能主要体现在如下几个方面:
作为 View 树的树根(注意,它自己并不是View,只是树根的意思而已)并管理 View 树
触发 View的测量、布局和绘制
输入响应的中转站
负责与 WMS 进行进程间通信
关于输入响应的中转站,我们可以看如下图:
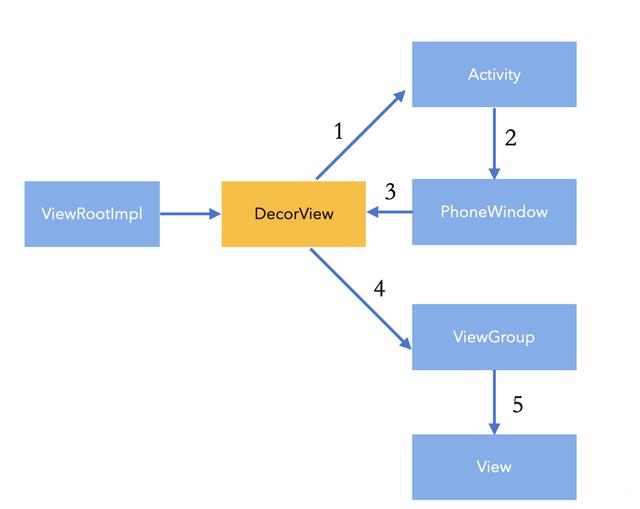
事件产生后,会传递到 ViewRootImpl 中,之后被传递给 DecorView ,我们根据这个步骤可以看到,这里面传递很弯弯绕绕,DecorView 传递给Acitivty ,第 3 步的时候,又回到了 DecorView 中。
为什么要这么设计呢?省略中间商赚差价直接到 ViewGroup 行不行?答案是不行。因为诸如打电话脸贴到屏幕上时需要黑屏,点击操作不能响应等操作, View 和 ViewGroup 上面没有相关的处理机制的,都在 PhoneWindow 里面,所以必须经过 PhoneWindow 。
view 或者 Window 的刷新都依赖于 ViewRootImpl 中的 scheduleTraversals 方法。
UI刷新
以 2 个问题开始:
TextView 连续 2 次setTextView ,那么会触发几次重绘?
Android 为什么要求帧率是 60?
答案:UI必须等待 16ms 的间隔才会绘制下一帧,所以连续2次 setTextView 只会触发一次重绘。同时必须每秒 60 帧(电影是 24 帧)用户才不会感觉卡顿,所以就 16ms 就要一帧。
关于刷新的整体流程我们可以参考如下图:
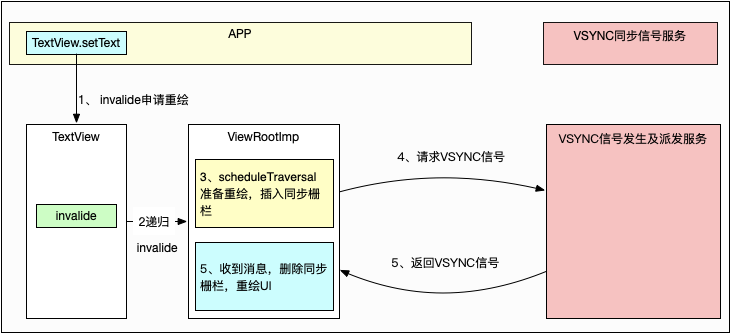
从图可以看出,setText 之后,就会触发 invalidate ,由于 View 自己不能刷新,需要向上请示老大,一直到 ViewRootImpl ,而 ViewRootImpl 自己也不能刷新,只能插入同步栅栏,等待下一次的 Vsync 信号(通过编舞者postcallback)来了之后再绘制。等到 Vsync 信号来了之后,我们会把同步栅栏给移除掉。
小结
总结一下主要有几点需要注意:
Android 一般是 60FPS ,是 VSYNC 决定的,每 16ms 最多一帧
VSYNC 要客户端主动申请,才又 VSYNC 到来才会刷新
UI没有更改的话,不会请求 VSYNC 也就不会有刷新
UI局部重绘其实只会去重绘有更新的 View
SurfaceFlinger
SurfaceFlinger 是整个 Android 系统渲染的核心进程,整个流程是这样的:每个 DecorView 对应一个 Surface ,每个 Surface 里面包含一个 canvas ,每个 surface 对应一个 layer(图层), SurfaceFlinger 将各类的图层合成。
SurfaceFlinger 的整体流程如下图所示:
面试题
onResume 里面度量的宽高有效吗?
分情况。Activity 第一次调用 onResume 的时候是无效的,从 Activity A 跳转到 B 再返回来,这时候 A 的onResume 中是有效的。因为 onResume 的时候,还没有 执行 window.addView 呢。
Activity 、Window、view 三者的联系和区别。
先整体,再细节。所以先讲这3个是啥,Activity 是xxx,window 是xxx,View 是xxx。Activity 没有界面,委托给 Window 展示,
首次 View 的绘制流程是什么时候触发的?
WindowManagerImpl.addView -> WindowManagerGlobal.addView
ViewRootImpl.setView -> ViewRootImpl.requestLayout
ViewRootImpl.scheduleTraversals
这时候就触发了首次绘制
我们调用 invalidate() 之后会马上进行屏幕刷新吗?
一定不。需要等到下一个 Vsync 信号来了才会
我们说丢帧是因为主线程做了耗时操作,为什么做了耗时操作就会引起丢帧?
一言以蔽之:主线程的耗时操作会影响下一帧的绘制。我们知道有以下信息:
在 ViewRootImpl 的 scheduleTravesals 方法中会去发送同步屏障,接着发送异步 Message,用于处理 UI 更新
在Handler 机制中碰到 target == null 这种 Message 的时候,就知道这是同步屏障了,此后,就只执行异步 Message
我们知道主线程耗时操作的体现形式也是 Message
如果有耗时操作之前的消息有耗时操作,那么可能耗时导致推迟执行 同步屏障那个 Message ,也就推迟了后续的 异步 Message的执行,也就影响了下一帧的绘制