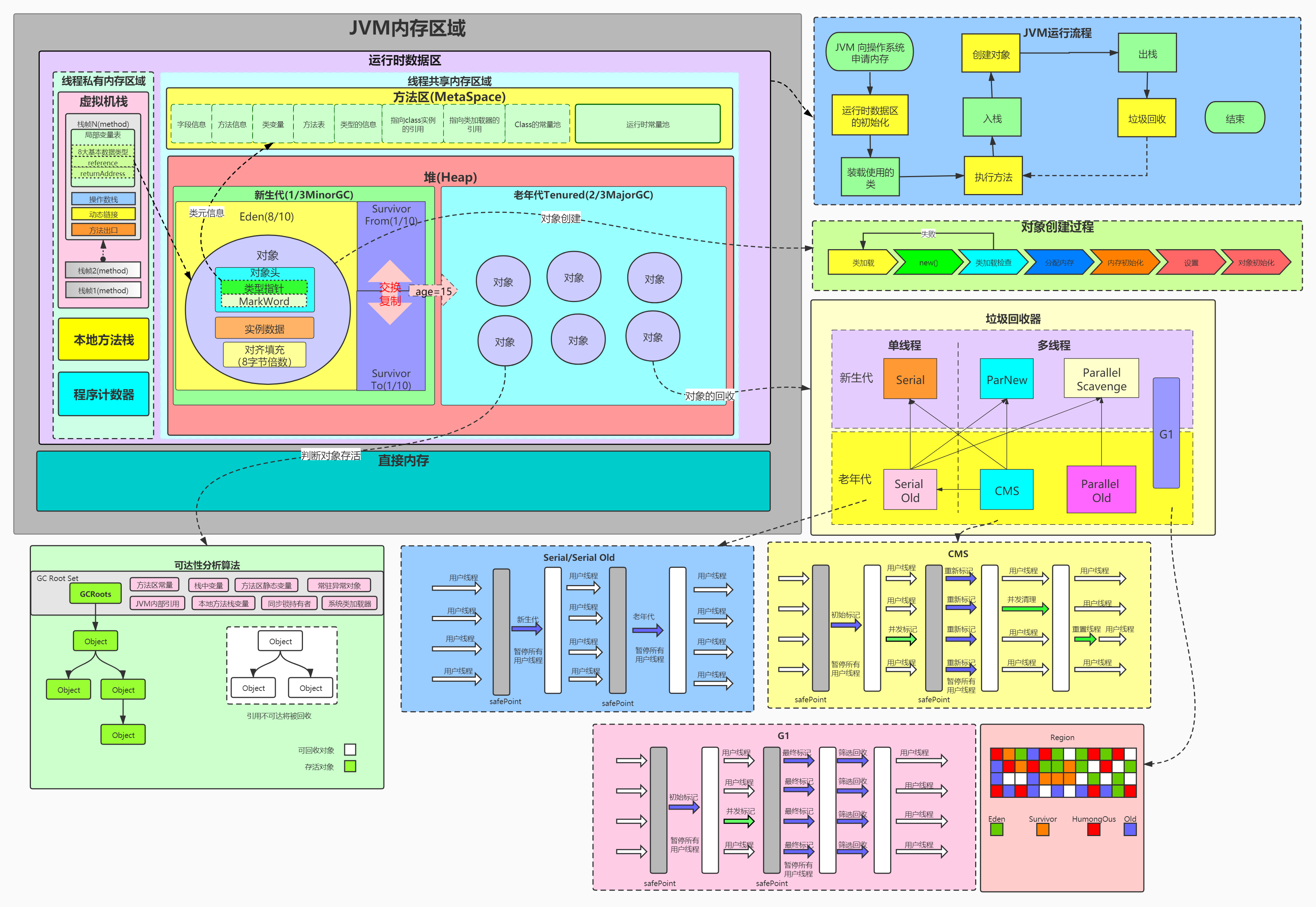
一、Java 线程安全停止工作
interrupt() 方法是对线程发起中断,只是改写了一下 标志位!不代表线程要立即停止工作。不过可以根据这个标志位来决定是否停止线程了。
基于这一点,我们可以说 JDK 中的线程是协作式的,而不是抢占式的。
所以,我们可以在 while 循环中,可以通过 isInterrupted() 来判断标记位状态,来判断是否终止线程,比如:
1 | static class UsetThread extends Thread { |
在这里,需要注意线程自己成员方法 isInterrupt() 以及 Thread.isInterrupt() 方法,如果是后者的话,它发现Thread.isInterrupt() == true 的时候,会又置为 false。所以上述在while 循环外面输出的最终线程xxx会为false(而如果用线程的成员方法isInterrupt() 这里会输出true ):
最终线程isInterrupted标记位:false 。不过我在本地运行(JDK1.8)的时候,并没有 Thread.isInterrupted() 这个方法了,可能高版本不见了
还是推荐使用 isInterrupted() 来终止线程
博客或者很多书籍上都会定义一个 volatile 类型的boolean 值 isCancel 来判断是否要结束线程的运行,如下所示:
1 | while(!isCancel) { |
但是,其实我们并不推荐这样做,因为这样的话,假如我在里面实现了Thread.sleep() 操作,这时候,我压根就不会判断到这个 isCacel 变量:
1 | while(!isCancel) { |
但是,在 sleep 阶段我们可以照常响应 interrupt 操作:
1 | while(!isInterrupted()) { |
这里是会响应try-catch 的,但是这里要注意一点,这个 println 会输出 :
in InterruptedException 中,isInterrupted = false
也就是在 catch 里面,我们去判断 isInterrupt 居然还是 false,这是因为抛出这个异常之后,又会将标志位置为 false,所以如果要真正让状态对,还需要我们在 catch 代码中手动实现 interrupt 方法:
1 | while(!isInterrupted()) { |
sleep 、wait 、join 等方法在使用的时候都会 catch InterruptedException 异常:
1 | try { |
那么,为什么要这么设计成在 catch InterruptedException 的时候,isInterrupted 还是 false 呢?也就是说如果不这样会有什么问题呢?
假设 sleep 过程持有了资源,如果中断来了直接中断,没有给程序员干预的时间,可能造成资源不能释放,造成死锁。并且注意一点:死锁状态的线程,是不会理会中断的。
所以,要让你自己处理完自己的操作之后(比如释放锁资源),才自己去设置 interrupt = true,自主性更强。像上述第二段代码,自己加了 interrupt 之后,再次 while 循环就不会进去了。
二、Thread 的 run 和 start
new Thread 的时候,只是创建了一个 Thread 类的实例而已。如果直接调用 Thread.run() 方法,就是和普通对象的普通方法是一样的,并不会新开线程;只有调用 start 方法,才会启用新的线程。
三、Thread 的 join 方法
线程 A 执行,这时候如果在 A 线程中调用线程B的 join 方法,则 A 线程会挂起,等 B 线程执行完成后,A 线程再继续执行。
所以,面试问怎么保证 2 个线程顺序执行,怎么办?那就使用 join() 方法咯。
四、线程的优先级
Java 里面的优先级级数和操作系统里面的级数是不一定相同的。最终有没有用,还得看操作系统的决策,所以优先级高的线程,获得的时间片不一定多。
五、守护线程
当所有的用户线程和非守护线程结束后,守护线程才结束掉,我们通过 thread.setDaemon(true); 操作即可将线程设置为守护线程。
在守护线程的 run() 方法中,finally 都不一定能给保证执行(用户线程是可以保证finally执行),这是为什么呢,资源还怎么释放呢?这是因为,一般守护线程关闭的时候,整个进程都要结束了,所以这时候资源都是会一起释放了,这时候守护资源也无需保证 finally 一定执行了。
一般适合做后台调度和支持性工作。