为了学习官方协程,我们先实现一些轻量级的复合协程,只是用于学习,不适合生产环境。
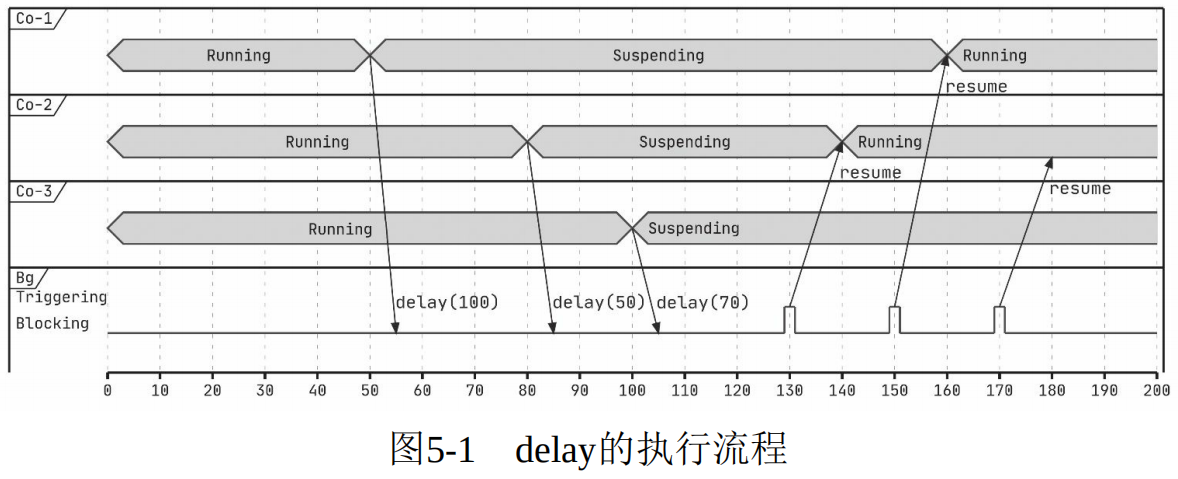
5.1 开胃菜:实现一个 delay 函数 使用线程的时候,如果希望代码延迟一段时间再执行,通常会调用 Thread.sleep 函数,这会令当前线程阻塞 。在协程中也可以这样,不过协程可以挂起还去阻塞线程,就很浪费资源,我们的目的是后面的代码延迟一段时间执行,因此可以确定以下2点:
不要阻塞线程
是个挂起函数,指定时间之后能够恢复执行即可
从上面 2 点我们可以给出 delay 函数的声明:
1 2 3 4 suspend fun delay (time: Long , unit: TimeUnit = TimeUnit.MILLISECONDS) if (time <= 0 ) return 。。。 }
接下来要考虑挂起,自然就想到了 suspendCoroutin :
1 2 3 4 5 6 7 suspend fun delay (time: Long , unit: TimeUnit = TimeUnit.MILLISECONDS) 。。。 suspendCoroutine<Unit > {continuation: Continuation<Unit > -> } 。。。 }
只需要做到在指定的 time 之后执行 continuation.resume() 就行,因此,我们只需要提供这样一个定时回调机制就可以! ,定时任务很容易想到 ScheduledExecutorService ,因此代码可以这样写:
1 2 3 4 5 6 7 private val executor = Executors.newScheduledThreadPool(1 , object : ThreadFactory{ override fun newThread (r: Runnable ) return Thread(r, "Scheduler" ).apply { isDaemon = true } } })
这里为什么要设置 isDaemon ,放到后面说。接着我们可以实现功能了:
1 2 3 4 5 6 7 8 9 suspend fun delay (time: Long , unit: TimeUnit = TimeUnit.MILLISECONDS) suspendCoroutine<Unit > {continuation: Continuation<Unit > -> executor.schedule(object : Runnable{ override fun run () continuation.resume(Unit ) } }, time, unit) } }
5.1.1 为什么这样用 ScheduledExecutorService(自己加的标题) 了解 ScheduledExecutorService 工作机制的朋友还会有疑惑:Scheduled-ExecutorService 在等待延时的阶段还是会阻塞 ,这不也浪费资源吗?这里说明下2个原因:
5.2 协程的描述 Java 平台上 Thread 的定义很直观,让人很容易识别 Java 线程;而协程一开始只是在标准库中放了协程基础设施,导致难以上手和分辨。这里我们尝试给一个类来描述协程,按照官方的做法把它命名为 Job ,如下代码清单:
1 2 3 4 5 6 7 8 9 10 11 interface Job : CoroutineContext.Element { companion object Key : CoroutineContext.Key<Job> override val key: CoroutineContext.Key<*> get () = Job val isActive: Boolean fun invokeOnCancel (onCancel: OnCancel ) fun invokeOnCompletion (onComplete: OnComplete ) fun cancel () fun remove (disposable: Disposable ) suspend fun join () }
与 Thread 相比, Job 同样有 join ,调用时会挂起( 而线程的 join 则会阻塞线程 ),直到协程完成;cancel() 类比与 Thread 的 interrupt() ,用于取消协程; isAlive() 类比 Thread 的 isAlive() ,用于查询协程是仍在执行。
invokeOnCancel 用于协程取消时的回调;invokeOnCompletion 可以注册协程完成的回调。remove 用于移除回调。 key 将协程 Job 存入上下文,这样就很容易拿到 Job 实例。
5.2.2 协程的状态 我们对协程进行封装,目的就是让它状态更容易管理。对于协程来讲,启动之后主要就是 未完成、已取消、已完成 这几种状态,接下来定义一下状态:
1 2 3 4 5 6 7 8 sealed class CoroutineState class Imcomplete : CoroutineState class Cancelling : CoroutineState class Complete <T >val value: T? = null , val exception: Throwable? = null ) : CoroutineState() }
——————-中间略过一大截,看不懂—————————–
5.4 协程的执行调度 协程在哪里挂起、什么时候恢复都是开发者自己决定的,意味着不像线程那样把调度工作交给操作系统,而是在用户态解决,所以协程也经常被称为用户态线程 。
5.4.2 协程的调度位置 当协程执行到挂起点为止时,如果产生异步行为,协程就会在这个挂起点挂起 ,这里的一部情形包括以下形式:
挂起点对应的挂起函数内部切换了线程,并在线程内部调用 Continuation 的恢复调用来恢复。
挂起函数内部通过某种事件循环机制将 Continuation 的恢复调用转到新的线程调用栈上执行。如:Android平台通过 Handler 的 post 操作,实际上这个过程不一定发生线程切换
挂起函数内部将 Continuation 保存,在后续某个时机再执行恢复调用,这个过程也不一定发生线程切换,但是函数调用栈会发生变化。
综上所述,不管何种形式,恢复和挂起不再同一个函数调用栈中执行就是挂起点挂起的充分条件! 只有当挂起点真正挂起,我们才有机会实现调度,而实现调度需要使用协程拦截器 。
5.4.3 协程的调度器设计 官方协程框架的默认调度器就是基于线程池实现的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 object DefaultDispatcher : Dispatcher { private val threadGroup = ThreadGroup("DefaultDispatcher" ) private val threadIndex = AtomicInteger(0 ) private val executor = Executors.newFixedThreadPool( Runtime.getRuntime().availableProcessors() + 1 ) { runnable -> Thread( threadGroup, runnable, "${threadGroup.name} -worker-${threadIndex.getAndIncrement()} " ).apply { isDaemon = true } } override fun dispatch (block: () -> Unit ) executor.submit(block) } }
调用dispatch 方法的时候,实际上是将 block 扔给 executor 放到线程中执行。
其实也可以实现成基于拦截器的方式:
1 2 3 override fun resumeWith (result: Result <T >) dispatcher.dispatch { delegate.resumeWith(result) } }
基于UI事件循环的调度器就是通过在disptch() 方法中用 Handler 的 post 实现:
1 2 3 4 5 6 object AndroidDispatcher : Dispatcher { private val handler = Handler(Looper.getMainLooper()) override fun dispatch (block: () -> Unit ) handler.post(block) } }
——————-后续的又看懵逼了—————————–